(카테고리는 Kaggle이지만, 데이터를 분석하는 과정을 실습하는 과정이므로, 해당 카테고리에
포스팅하게 되었다.)
데이터 다운로드
주소는 https://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones
UCI Machine Learning Repository: Human Activity Recognition Using Smartphones Data Set
Human Activity Recognition Using Smartphones Data Set Download: Data Folder, Data Set Description Abstract: Human Activity Recognition database built from the recordings of 30 subjects performing activities of daily living (ADL) while carrying a waist-moun
archive.ics.uci.edu
으로 접속하여 DataFolder을 클릭해 .zip 압축 파일을 다운받으면 된다.


데이터 전처리(알맞은 피처명 변환)
바로 X_train, X_test 등의 파일을 확인하기 전에 feature.txt파일을 열어 groupby()를 통해 피처 명을 확인해보면
중복된 피쳐명이 중간중간 존재한다는 것을 확인할 수 있다. 이런 상태에서 데이터를 불러와 DataFrame으로 만들게 되면 오류가 발생하게 된다. 따라서 중복된 피처 명을 _1, _2 등의 방식으로 구별한 후에 DataFrame으로 만들어주어야 한다.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
#features.txt 파일에는 피처 이름 index와 피처 명이 공백으로 분리되어 있음. 이를 DataFrame으로 로드
feature_name_df = pd.read_csv('./human_activity/features.txt', sep = '\s+', header = None, names = ['column_index', 'column_name'])
feature_name_df
feature_dup_df = feature_name_df.groupby('column_name').count()
feature_dup_df

이 오류를 해결하기 위해선 2개의 함수를 정의해야 하는데,
첫번째 함수는 해당 피처명이 몇번째 중복된 피처인지를 나타내기 위한 함수이다. 예를들어 피처명을 칼럼으로 가지는 DataFrame을 생성했을 때, 0번째 인덱스에 'A'라는 피처가, 56번째에도 'A'라는 피처가 , 112번째에도 'A'라는 피처가 존재한다면 이것을 .cumcount() 메서드를 통해서 0번째 피처명은 'A', 56번째는 'A_1', 112번째는 'A_2' 이런식으로 만들어 주는 칼럼을 기존의 DataFrame에 추가하는 함수이다.
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data = old_feature_name_df.groupby('column_name').cumcount(), columns = ['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how= 'outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x: x[0]+'_'+str(x[1])
if x[1]>0 else x[0], axis = 1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis = 1)
return new_feature_name_dfimport pandas as pd
def get_human_dataset():
#각 데이터 파일은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep로 할당
feature_name_df = pd.read_csv('./human_activity/features.txt', sep = '\s+', header = None, names = ['column_index', 'column_name'])
#중복된 피처명을 수정하는 get_new_feature_names_df()를 이용, 신규 피처명 DataFrame 생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
#DataFrame에 피처명을 칼럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
#학습 피처 데이터세트와 테스트 피처 데이터를 DataFrame으로 로딩. 칼럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt', sep = '\s+', names = feature_name)
X_test = pd.read_csv('./human_activity/test/X_test.txt', sep = '\s+', names = feature_name)
#학습 레이블과 테스트 레이블 데이터를 DataFrame으로 로딩하고 칼럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt', sep = '\s+', names = ['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt', sep = '\s+', names = ['action'])
#로드된 학습/테스트용 DataFrame을 모두 변환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
2번째 함수는 실질적으로 분석해야 하는 데이터들을 첫번째 함수에서 제작한 칼럼명을 가진 DataFrame으로 만들어주는 것이다.
함수를 실행한 이후에 X_train.info()를 보면 정상적으로 DataFrame으로 들어와있는 것을 확인할 수 있다.
print('### 학습 피처 데이터셋 info()')
print(X_train.info())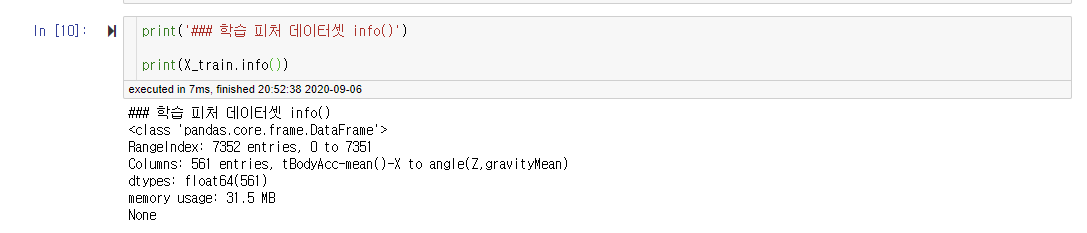
레이블 값에 해당하는 y의 'action' 칼럼의 레이블 값 분포에 대해서 알아본다.
print(y_train['action'].value_counts())
레이블 값의 분포가 심하게 왜곡되지 않고 (값이 한쪽으로 몰리지 않고) 비교적 골고루 분포하고 있는 것을 확인할 수 있다.
결정트리 클래스를 호출하여 학습 / 예측에 사용할 것이다. 성능 지표는 정확도로 측정을 할 것이고,
기존의 성능을 더 높이기 위해서 결정트리에서 사용하는 하이퍼 파라미터 목록을 출력하였다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
#예제 반복시마다 동일한 예측 결과 도출을 위해 random_state설정
dt_clf = DecisionTreeClassifier(random_state = 156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('결정 트리 예측 정확도 : {0:.4f}'.format(accuracy))
#DecisionTreeClassifier의 하이퍼 파라미터 추출
print('DecisionTreeClassifier 기본 하이퍼 파라미터 : \n', dt_clf.get_params())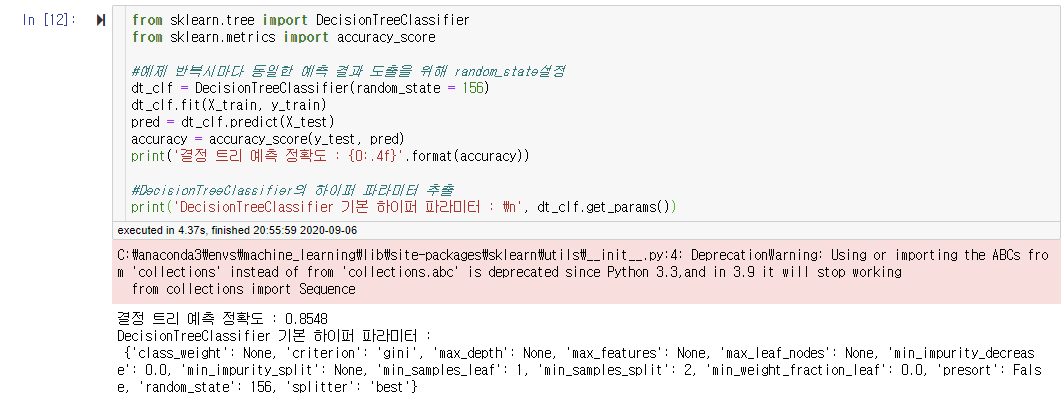
GridSearchCV
하이퍼 파라미터가 가질 수 있는 여러 값들을 한꺼번에 수행하여 비교하고, 가장 최적의 하이퍼 파라미터를 찾아주는
GridSearchCV를 이용할 것이다. 하이퍼 파라미터 최적화는 모든 파라미터에 대해서 수행을 하게 된다면 좋겠지만,
그러기엔 너무나 많은 시간이 소요되고, 시간이 소요되는 만큼의 성능향상을 기대할 수 없기에, 1~2개의 하이퍼 파라미터를 가지고 GridSearchCV를 수행하였다.
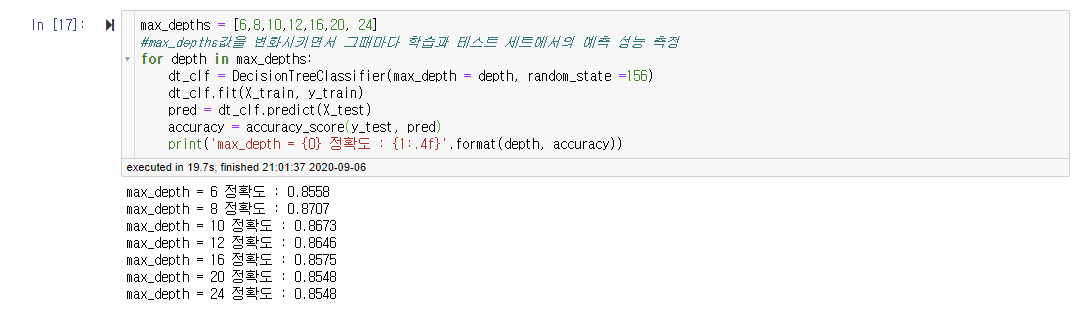
일단 첫번째 하이퍼 파라미터는 max_depth이다. 결과는 'max_depth'가 8일때 최고 평균 정확도 수치가 0.8526이 나온것을 확인할 수 있다.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20, 24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring= 'accuracy', cv = 5, verbose = 1)
grid_cv.fit(X_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터 :', grid_cv.best_params_)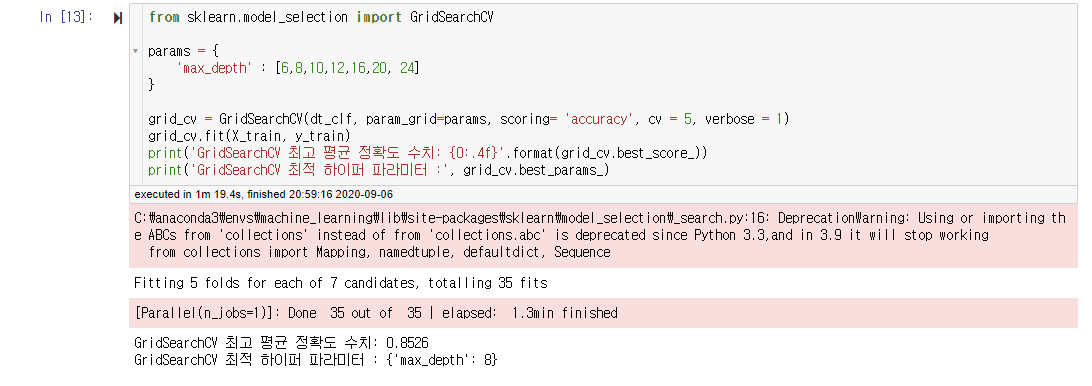
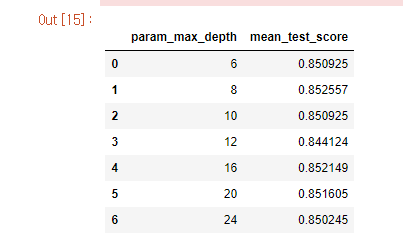
단지 최적의 하이퍼 파라미터에 관한 값만 알아낼 수 있는 것이 아니라, 학습과 예측을 수행한 모든 파라미터 값에 대해서도 성능 지표를 확인할 수 있다. 하나는 .cv_results_를 통해서 'param_max_depth', 'mean_test_score'를 확인하는 방법과 다른 하나는 단순하게 for문을 통해서 학습을 진행할 때마다 파라미터 값과 성능 지표를 출력하도록 만들 수 있다.
#GridSearchCV 객체의 cv_results_ 속성을 DataFrame으로 생성.
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
#max_depth 파라미터 값과 그때의 테스트 세트, 학습 데이터 세트의 정확도 수치 추출
cv_results_df[['param_max_depth', 'mean_test_score']]max_depths = [6,8,10,12,16,20, 24]
#max_depths값을 변화시키면서 그때마다 학습과 테스트 세트에서의 예측 성능 측정
for depth in max_depths:
dt_clf = DecisionTreeClassifier(max_depth = depth, random_state =156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('max_depth = {0} 정확도 : {1:.4f}'.format(depth, accuracy))
추가적으로 'min_samples_split'이라는 하이퍼 파라미터를 추가하여 학습/ 예측을 수행하였고, 예측 정확도가 올라간 것을 볼 수 있다. 하지만, 2배로 긴 과정을 수행하여 올라간 수치는 매우 미미하므로, 너무 많은 하이퍼 파라미터 최적화는 시간적인 면에서 비효율적이라는 것을 알 수 있다.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20, 24],
'min_samples_split' : [16,24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring= 'accuracy', cv = 5, verbose = 1)
grid_cv.fit(X_train, y_train)
print('GridSearchCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSearchCV 최적 하이퍼 파라미터 :', grid_cv.best_params_)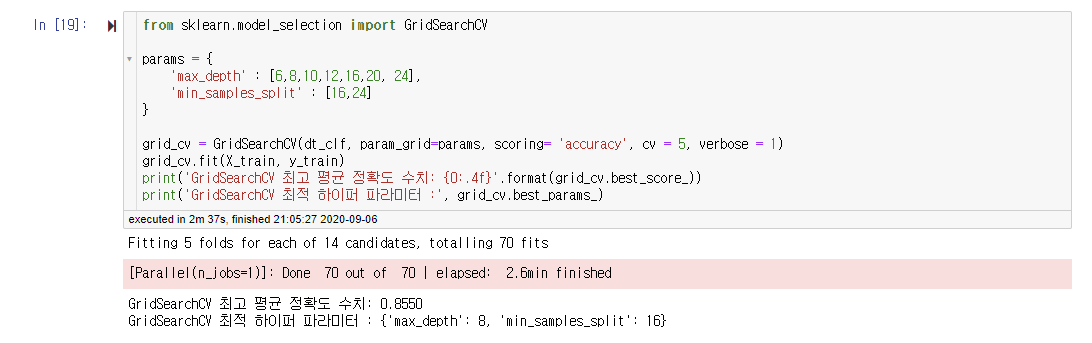
'best_estimator_'를 통해서 grid_cv를 통해서 최적의 하이퍼 파라미터를 찾고(best_df_clf), 해당 파라미터 셋에 대한 Test set의 성능을 알아본다.
best_df_clf = grid_cv.best_estimator_
pred1 = best_df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred1)
print('결정 트리 예측 정확도 : {0:.4f}'.format(accuracy))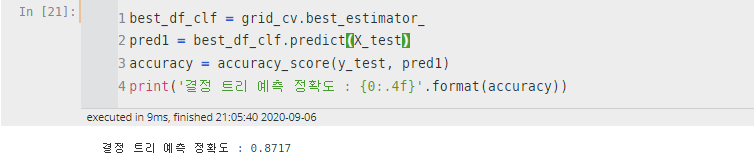
시각화
Seaborn을 통해서 예측 값들은 어떤 피처에 영향을 가장 많이 받는지를 시각화한 자료이다. 바로 위에서 구한 최적의 성능을 내는 하이퍼 파라미터를 가진 분류기인 best_df_clf를 사용하여 피처 중요도를 알아보았다. 한눈에 정돈되어보이도록, 내림차순으로 정리하고, 상위 20개를 시각화한 자료이다. 이 그래프를 통해서 어떤 피처가 레이블 값에 영향을 가장 많이 주는지를 확인할 수 있다.
import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
#Top 중요도로 정렬을 쉽게 하고, 시본(Seaborn)의 막대 그래프로 쉽게 표현하기 위해 Series 변환
ftr_importances = pd.Series(ftr_importances_values, index = X_train.columns)
#중요도값 순으로 Series 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize = (8,6))
plt.title('Feature importances Top 20')
sns.barplot(x = ftr_top20, y = ftr_top20.index)
plt.show()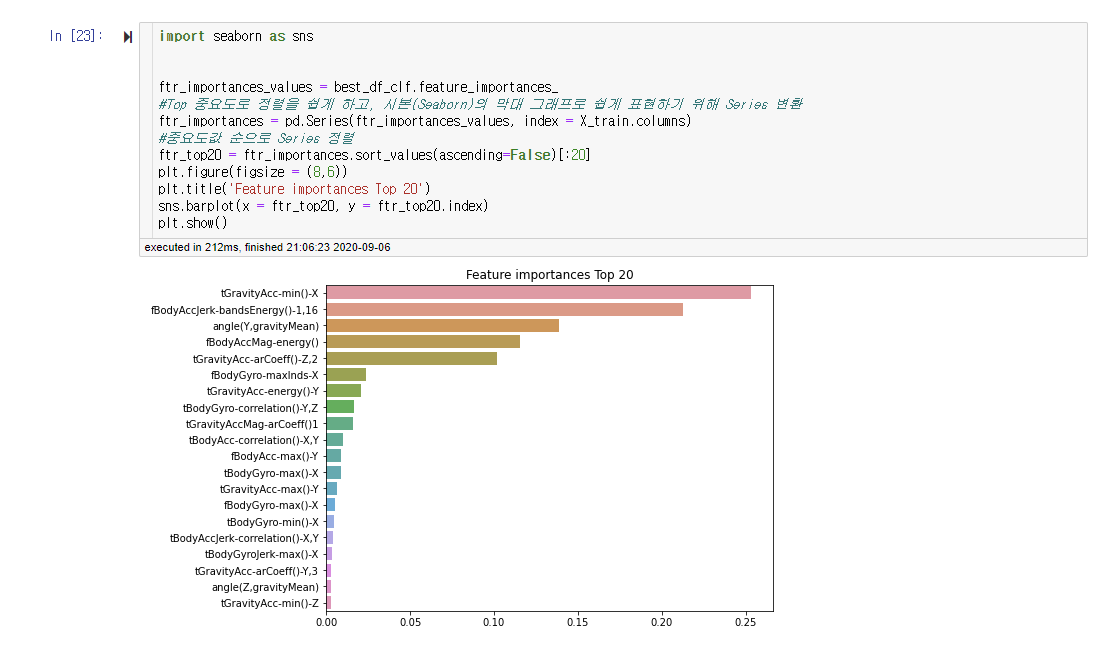
느낀점
이번 실습에서는 생각보다 학습 / 예측을 하는 과정보다는 데이터를 우리가 활용할 수 있는 머신러닝 알고리즘이나 클래스에 알맞은 형태로 변환해주는 작업에 대한 비중이 높았다. 하지만, 연습이나 실습이 아닌 실제로 데이터를 분석하는 경우에 이렇게 데이터를 알맞은 형태로 가공해주는 과정의 비중이나 들어가는 시간이 훨씬 크다고 한다. 특히나, 학습 / 예측을 이렇게 기존에 만들어진 알고리즘을 활용하여 수행하는 경우, 성능의 차이를 낼 수 있는 부분은 데이터를 전처리하는 부분이어서 이 부분에 대해서 조금 더 심화적으로 공부할 필요성을 느꼈다.
'기계학습 > Kaggle' 카테고리의 다른 글
| Kaggle : Pima Indians Diabetes[파이썬 머신러닝 완벽 가이드] - 피처 스케일링, 평가 지표 (0) | 2020.09.01 |
|---|---|
| Kaggle : Titanic [파이썬 머신러닝 완벽 가이드] - 2 (0) | 2020.08.27 |
| Kaggle : Titanic [ 파이썬 머신러닝 완벽 가이드 ] - 1 (0) | 2020.08.26 |

최근댓글