Data Frame은 다변량 데이터 분석에서 주로 사용되는 list형의 데이터 구조다.
1. Data Frame 생성
col1 <- c(1, 4, 7, 10)
col2 <- c(35, 55, 75, 95)
data <- data.frame(col1, col2)
data
숫자 벡터 col1과 col2를 만든 후, data.frame() 함수를 통해 Data Frame을 생성한 것이다. 하나의 데이터 프레임에 속한 열의 자료형은 서로 다를 수 있지만, 각 열의 길이는 같아야 한다.
data <- read.csv('data.csv')
data

별도의 패키지 설치 없이 read.csv() 함수로 CSV 파일을 불러와서 Data Frame을 생성한 것이다.
2. 데이터 탐색
1) head(), tail() : 데이터의 앞, 뒤 부분을 deafult로 6개의 행을 확인하는 함수

2) dim() : 데이터의 행과 열의 수를 확인하는 함수
3) str() : 데이터에 포함된 변수의 속성 확인하는 함수

3. 파생변수 생성 : 조건문을 활용하여 열 추가하기
파생변수란, 어떤 조건을 만족하거나 어떤 함수를 활용해서 값을 만든 후에 의미를 부여한 변수를 뜻한다.
data$churn <- ifelse(data$activity < 0.01, "Y", "N")
head(data)
위의 data의 activity 변수가 0.01보다 작으면 churn이라는 변수에 "Y"를, 그렇지 않으면 "N"을 부여한 뒤 맨 앞 6개의 행을 확인한 것이다.
파생변수는 이처럼 조건문을 활용해도 되며, 여러 변수의 평균을 구해서 만들어도 된다.
table(data$churn)
qplot(data$churn)
churn 변수에 대해 table()과 qplot() 함수를 실행한 것으로, 두 변수의 빈도 수를 확인할 수 있다. qplot() 함수를 실행하면 Console 창이 아닌 Plots 창에 결과가 표시된다. qplot() 함수는 ggplot2 패키지에 내장되었기 때문에, 실행하기 전에 ggplot2를 먼저 로드해야 한다.
4. 데이터 전처리
R에서 데이터 전처리에 주로 사용되는 패키지는 dplyr이다.
A Grammar of Data Manipulation
A fast, consistent tool for working with data frame like objects, both in memory and out of memory.
dplyr.tidyverse.org
1) select() : 필요한 변수만 추출
data %>% select(period, activity)
data %>% select(-period, -activity)
필요하지 않은 변수는 -를 붙여 제외할 수 있다. dplyr 패키지를 사용할 때는 pipe operator라고 하는 %>%를 사용해서 함수를 나열한다. %>%의 입력은 Ctrl + Shift + M으로 대체할 수 있다.
2) filter() : 조건에 맞는 데이터 추출
data %>% filter(age == 50 & (period > 150 | term > 2))
data에서 age가 50이면서 period가 150보다 크거나 term이 2보다 큰 것만 추출한 것이다.
3) arrange() : 정렬
data %>% arrange(disease)
data %>% arrange(desc(disease))
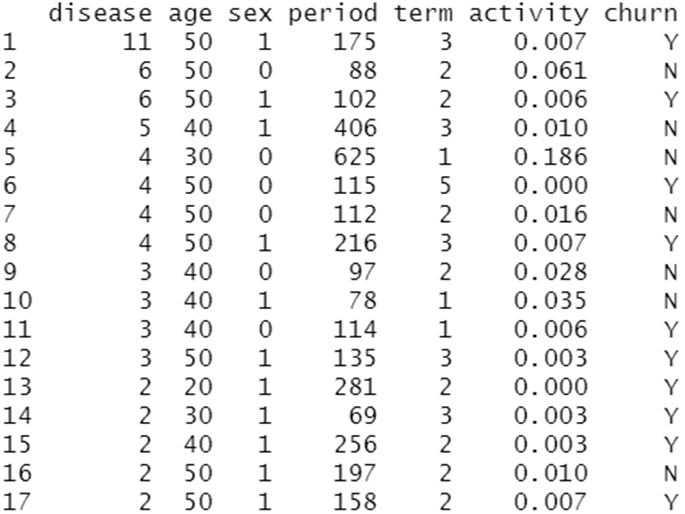
정렬할 기준 변수에 따라 오른차순, 내림차순으로 정렬할 수 있다.
4) mutate() : 파생변수 추가
data %>% mutate(churn_mutate = ifelse(data$activity < 0.01, "Y", "N")) %>% head(data)
mutate() 함수를 사용하지 않고 만든 것과 방법은 유사하다.
5) group_by(), summarise() : 집단별 요약
data %>%
group_by(churn) %>%
summarise(mean_disease = mean(disease),
mean_period = mean(period),
mean_activity = mean(activity))
group_by()와 summarise() 함수를 사용해서 churn의 값에 따른 disease의 평균(mean_disease), period의 평균(mean_period), activity의 평균(mean_activity)을 요약한 것이다.
'Programming Language > R' 카테고리의 다른 글
| [R] 회귀분석 - 변수선택 (0) | 2021.02.16 |
|---|---|
| [R] 가설검정, 상관분석 (0) | 2021.02.15 |
| [R] ggplot2 (0) | 2021.01.29 |
| [R] Data Frame 2 - 결합, 결측치 (0) | 2021.01.22 |
| [R] R Introduction (0) | 2021.01.08 |

최근댓글