본 논문에서는 implicit gradients를 활용한 Meta Learning을 통해 의료 이미지에 대한 segmentation에 관한 내용을 다룬다.
1. Meta Learning
Medical Image Analysis 분야에서 발생하는 주요 문제는 1) 질병에 대한 annotation 작성의 어려움, 2) 피부나 위 등 다양한 기관 및 흑색종이나 용종 등 여러 질병으로 구성된 heterogeneous dataset, 3) public한 dataset의 부족과 잘못된 label이 포함된 품질적인 이슈 등이 존재한다. 이러한 문제를 해결하기 위해 Few shot Setting에서의 Meta Learning이 잠재적인 솔루션으로 부상하고 있다.
Meta Learning이란 'Learning to learn'이라고도 하며, 자신이 아는 것과 모르는 것을 구별할 수 있는 메타인지라는 개념에서 시작이 되었다. 사람이 강아지와 고양이를 단 몇 마리만 보고도 구별하도록 학습하는 것처럼 메타러닝의 학습 방식도 사람이 학습하는 방식과 유사하게 이루어진다. 즉, Meta Learning의 학습 방식은 적은 양의 데이터로도 스스로 학습하여, 학습한 정보와 알고리즘을 통해 새로운 task를 해결하도록 이루어진다.
Meta Learning의 Approach는 크게 3가지가 존재한다.
1) Metric Based Learning : 효율적인 distance metric을 학습
데이터 간의 거리를 학습함으로써, latent space에서 같은 class 간의 데이터는 가깝게, 다른 class 간의 데이터는 멀리 떨어지도록 한다.
ex : Siamese Neural Network, Prototypical Network...
2) Model Based Learning : 모델 내/외부에 각각 메모리를 별도로 두어 모델 학습 속도를 조절
빠른 학습에 특화된 모델을 기반으로 적은 train 단계만으로 모델 parameter를 효율적으로 학습하도록 한다.
ex : MANN(Memory-Augmented Neural Network), MetaNet(Meta Network)...
3) Optimizer Learning : 최적의 모델 초기 parameter를 찾도록 학습
Meta task 자체를 parameter 최적화 문제로 고려하여 좋은 초기 가중치를 찾도록하여 특정 task에 대한 overfitting을 막도록 한다.
ex : MAML(Model Agnostic Meta Learning), FOMAML(First-Order MAML)...
본 논문에서는 마지막의 Optimizer Learning 방식을 사용하여 메타러닝을 수행하였다.
2. MAML(Model Agnostic Meta Learning)
MAML은 model agnostic이라는 것에서 의미하는 것처럼 gradient descent 방식으로 학습하는 모든 모델에 적용 가능한 알고리즘으로, 모델 독립적인 방법이다.

3개의 task가 있을 때, θ1*, θ2*, θ3*를 활용하여 공통의 parameter로부터 특정 task에 대한 모델 adaptation을 한 후에, 각 task의 Loss를 계산해서 모델 update 및 3개의 gradient를 조합해서 3개의 task에 최적화할 수 있는 공통의 parameter update 과정을 거쳐 최적의 가중치를 찾을 때까지 위의 과정을 반복한다.
3. Few shot Learning
위와 같은 Meta Learning 방식을 기반으로 적은 수의 데이터로 학습하는 방법을 Few Shot Learning이라 한다. 일반적인 Supervised Learning에서는 train/test set이라 지칭하는데, Few shot Learning에서는 train을 위한 데이터를 support set, test를 위한 data를 query set이라고 부른다. Few-shot Learning은 N-way K-shot task라고도 하는데, N은 class의 개수 K는 class의 support 데이터 수를 의미한다. 아래 고양이와 자동차를 각각 5장의 이미지로 훈련하고 분류하는 것을 2-way 5-shot task라고 한다.

4. Datasets
본 논문에서 사용한 Dataset은 내시경 용종 데이터(3 sets)와 피부 병변 데이터(2 sets)로 총 5가지의 데이터 셋을 사용하였다.

5. Methods
이미지 segmentation을 위해 사용된 CNN 모델은 Attention U-Net, Meta-learning 알고리즘으로는 implicit MAML이 적용되었다. 앞서 소개한 MAML은 back propagation 중에 gradient vanishing이 발생할 수 있기에, 본 논문에서는 implicit MAML을 선택했다.

Loss function은 binary cross entropy와 Log-Hyperbolic Cosine-Dice의 합에 2차 정규화가 적용되었다.
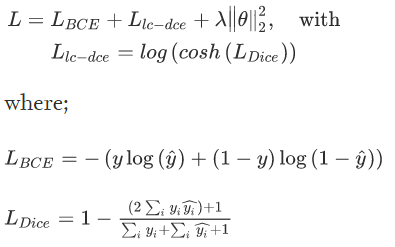
Model Architecture는 다음과 같다.
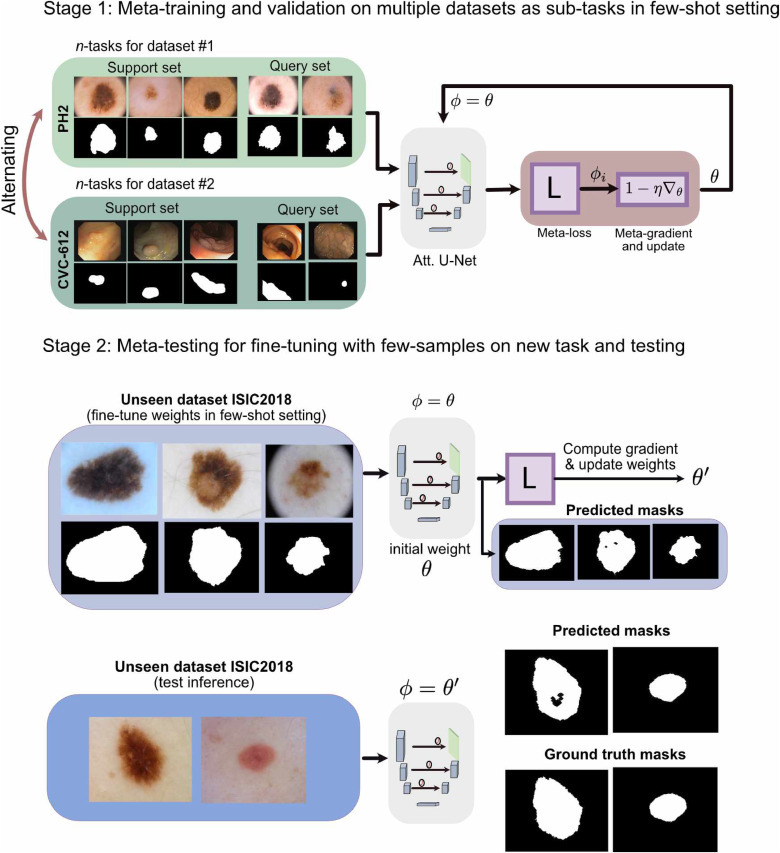
해당 논문에서는 Meta Learning을 2가지 단계로 나누어 수행하였다.
1) Meta-training & validation on multiple datasets as sub-tasks in few-shot setting : meta-train과 validation을 수행하는 과정으로, N개의 task를 각각 학습을 한 후에 gradient update를 거쳐 최적의 초기 파라미터인 θ를 얻게 된다. 해당 단계가 끝나고 난 후에 초기 가중치를 얻게 되는 셈이다.
2) Meta-testing for fine-tuning with few-samples on new task and testing : meta-test인 단계로, inital weight인 θ를 가지고 test data의 일부를 사용하여 fine-tuning을 거쳐 θ'를 얻게 된다. 그 후에, 최종적으로 남은 데이터로 image segmentation을 inference 한다.
6. Experiments & Results
실험 내용은 총 3가지이고, 공통적으로 2-way n-shot setting을 적용하고, 256X256으로 이미지 크기를 resize 하였다. 모델 성능을 측정하는 Metric은 F1 score라고도 하는 DSC를 사용하였다.
1) Meta-training with samples drawn exclusively from 2 unique datasets & categories
2가지의 다른 카테고리를 지닌 데이터 셋으로 meta-train을 진행한 것이다. 즉, 용종과 피부 데이터 set을 혼합하지 않고 구분된 상태로 train을 진행하였다는 의미다. train에 사용된 데이터는 Kvasir-SEG(polyp)와 PH2(skin)이고, test에 사용된 데이터는 ISIC-2018(skin)이다.
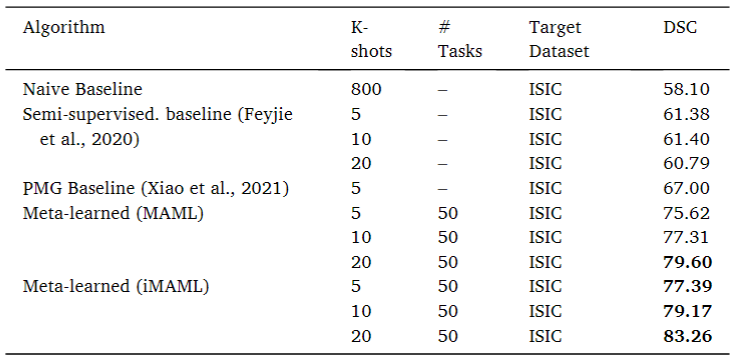
naive 한 attention U-Net으로 수행했을 때 DSC는 58%인 것에 비해, 본 연구에서 제시한 iMAML 방식으로 측정한 DSC의 최고 성능은 20 shot일 때 83%를 보였다.
2) Task comprising mixed samples of 2 unique datasets
위의 실험과 동일한 데이터지만, 용종과 피부경 데이터를 섞어서 train을 진행한 것이다.

위의 실험 대비 iMAML의 20 shot에서 10%가량 낮은 성능이 도출되었으나, naive Baseline인 Attention U-Net과 general 한 MAML보다는 높은 성능을 보였다.
3) Task comprising samples from 2 unique datasets of the same class
마지막 실험은 용종과 피부 병변을 각각 2 데이터셋을 묶어서 실험을 진행한 것이다. 아래 표의 왼쪽은 용종 dataset 2개(CVC-612, Kvasir-SEG)로 train 하여 피부 병변(ISIC-2018) datset으로 test 한 결과이고, 오른쪽은 피부 병변 dataset 2개(ISIC-2018, PH2)로 train하여 용종(Kvasir-SEG, KvasirCapsule-SEG) datset으로 test한 결과다.
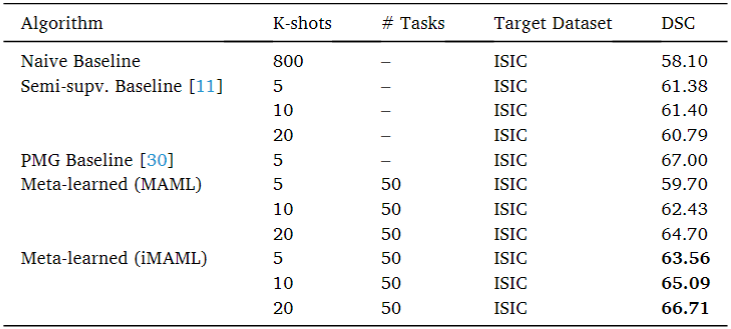
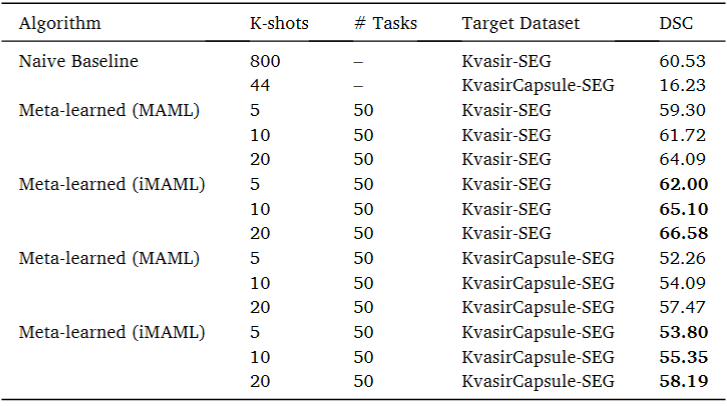
왼쪽 테이블에서 iMAML이 Naive model과 MAML보다는 높은 성능을 도출했으나, PMG라는 다른 논문의 SOTA보다는 5 shot에서 3.5%가량 낮은 성능이 나타났다. 하지만, 우측 테이블에서는 shot 별로 MAML보다 implicit MAML이 모두 높은 성능이 도출되었다.
7. Conclusion
본 논문의 3번째 실험의 일부 iMAML의 성능이 다른 모델에 비해 낮게 도출되었으나, 향후 연구에서는 메타 러닝을 수행할 때 2번째 실험과 같이 dataset의 instance를 섞은 경우에 더욱 좋은 성능이 나타날 것을 기대한다고 한다.
Reference
R.Khadga, D.Jha, S.Hicks, V.Thambawita, M.A. Riegler, S.Ali, and P.Halvorsen, "Meta-learning with implicit gradients in a few-shot setting for medical image segmentation", Computers in Biology and Medicine, Volume 143, April 2022.

최근댓글