.

안녕하세요 저는 브라이틱스 서포터즈 3기
이상민입니다 :)
저번 포스팅에는 개인 프로젝트인
제주도 도로 교통량예측 데이터
EDA를 진행했는데요.
이번 포스팅은 Baseline Model(기준 모델)을 구현하며
분석의 기준점을 세우고
추가적인 실험을 진행하여
성능을 높이고자 합니다.

왜 feature engineering이 아닌
Baseline model부터 만드나요??
기본적으로 데이터분석을 진행하신 분들은
궁금증을 가지실 수 있습니다.

맞습니다! 기본적인 분석 과정은
데이터 수집 -> EDA -> Feature engineering(변수 생성&조합)
-> Modeling -> Evaluation으로 진행하는데요.
저는 분석을 진행하면서 기준 model을 먼저 세우고 진행합니다.
그 이유는 변수를 생성하고, 그 변수가 유의미한지
즉 성능적인 면에서 상승이 있었는지 확인할 수 있어야 하는데요.
이렇기 때문에 가장 base한 변수, 주어진 변수들만을 활용하여
baseline model을 먼저 만들고
추후 feature engineering과정을 통해
유의미한 변수와 무의미한 변수를 구별해주려고 합니다!
baseline model 구현
그럼 baseline model을
브라이틱스 스튜디오를 통해
함께 구현해보겠습니다.
먼저 저번 포스팅때처럼
data를 load해줍니다!
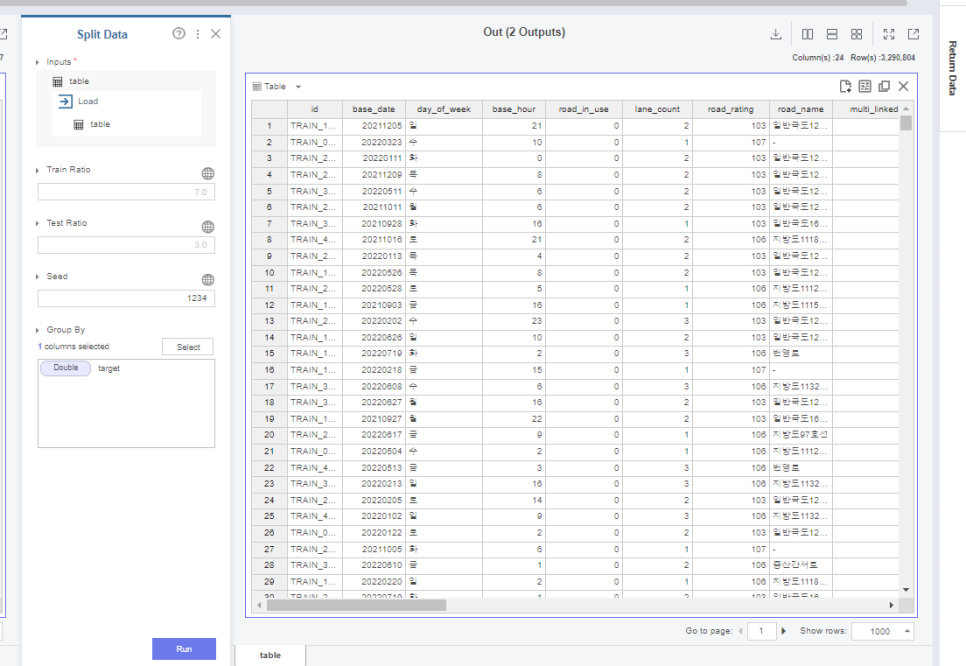
그 다음은 split data 함수를 통해
데이터를 train과 test로 분리해줍니다.
여기서 seed를 고정해주는데요.
이는 추후 실험을 반복할 때,
똑같은 데이터셋으로
성능적인 면의 변화를 보기 위해
고정해줘야 합니다.
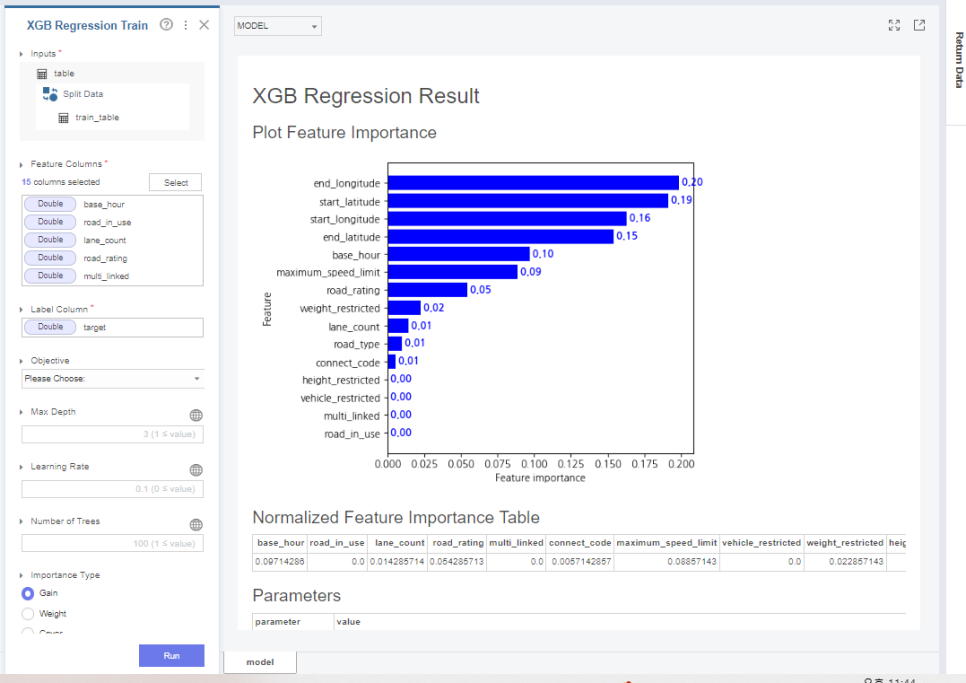
그 후 xgboost regression함수를 통해
train data를 학습해줍니다.
여기서 변수는 numerical한 변수만 사용해줬는데요.
baseline model이기 때문에
categorical한 변수는 사용하지 않았습니다.
추후 encoding과정을 통해 변환한 후,
데이터셋에 붙인 다음
categorical한 변수만 사용했을 때 비해
얼마나 성능향상이 이뤄졌는지 확인해보려고 합니다.
추가적으로 하이퍼 파라미터도
기본값으로 설정해줍니다.
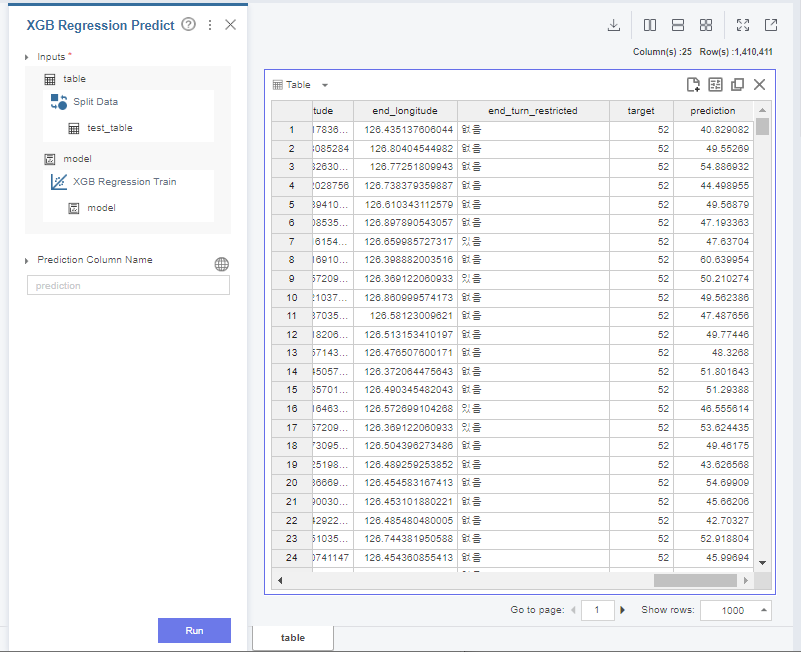
그 다음 predict 함수를 통해
test data를 예측해줍니다.
이 때 사용한 model은
train data로 학습한 xgb regression 모델입니다.
데이터를 보시면
predict라는 변수가 생성된 것을 볼 수 있는데,
이는 바로 predict에서 예측한 값입니다.
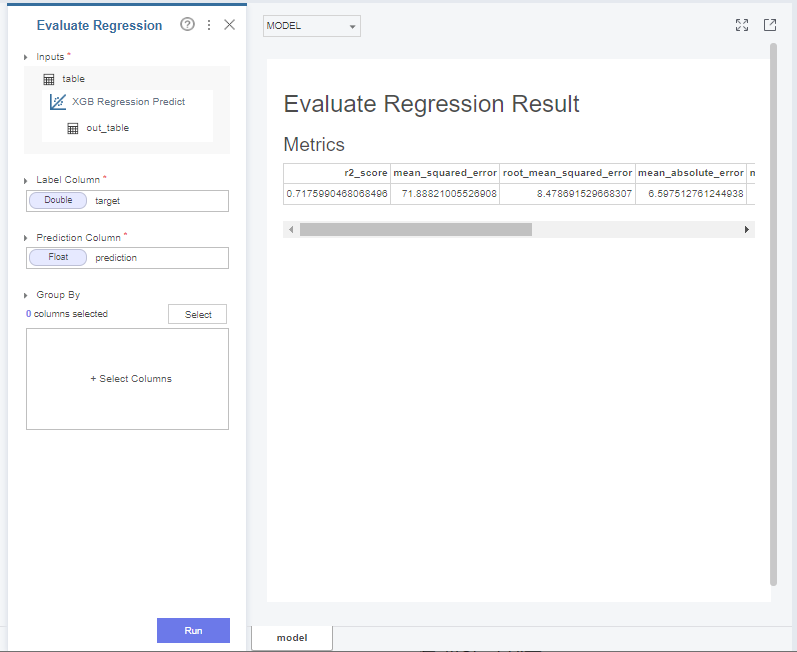
마지막으로 모델이 제대로 평가를 진행했는지
확인하기 위해 evaluation을 해줘야하는데요.
브라이틱스에는 regression, classification 태스크에 맞게
자동적으로 평가지표를 측정해줍니다.
label과 prediction column만 올바르게 부착만 해주면
되기 때문에 매우 편리한 함수입니다!

위는 model이 예측한 값을 바탕으로
평가한 지표들인데요.
먼저 이 지표들에 대해 간단히 알아보자면
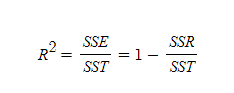

r2 score란 모델의 회귀선과 실제 값들간의
차이(오차)를 나타내는 값인데요.

SSE = SUM(추정값 - 관측값 평균)^2
SST = SUM(관측값 - 관측값 평균)^2
SSR = SUM(관측값 - 추정값 평균)^2
으로
관측값과 추정값의 차이, 즉 오차를 1에서 뺀 후
얼마나 오차가 적은지 나타내는 값이 S2 score라고 볼 수 있습니다.
이에 따라 1에 가까울수록 모델이 실제 데이터와 가깝게 예측한 것이고
0에 가까울수록 올바르게 예측하지 못한 것이라고 볼 수 있습니다.
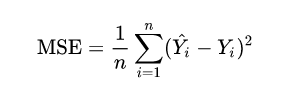

다음은 MSE와 MAE인데요.
먼저 MSE는 Mean squared error로,
오차의 제곱을 평균으로 나눈 것입니다.
0에 가까울수록 정확도가 높다고 볼 수 있습니다.
여기서 rmse는 mse에 root를 씌운 것인데요.
이 효과는 실제 값에 비해 얼마나 떨어져 있는지
직관적으로 볼 수 있습니다.
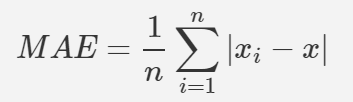
다음 MAE는 Mean Absolute Error로
평균절대오차입니다.
제곱이 아닌 절대값의 오차를 나타내기 때문에
RMSE와 비슷하게 실제값으로부터 얼마나
차이가 나는지 직관적으로 확인 가능합니다.
test 데이터 검증 진행
이렇게 학습과정을 거치고
실제 test데이터를 바탕으로 평가를 진행해봐야 되겠죠?

도로교통량의 test데이터를 불러오고,
이번에는 data를 나누지 않고
full data로 학습을 진행해줍니다.
test 데이터는 위와 같은데요.
말 그대로 검증을 위한 데이터이니
label인 target변수가 없는 것을 볼 수 있습니다.
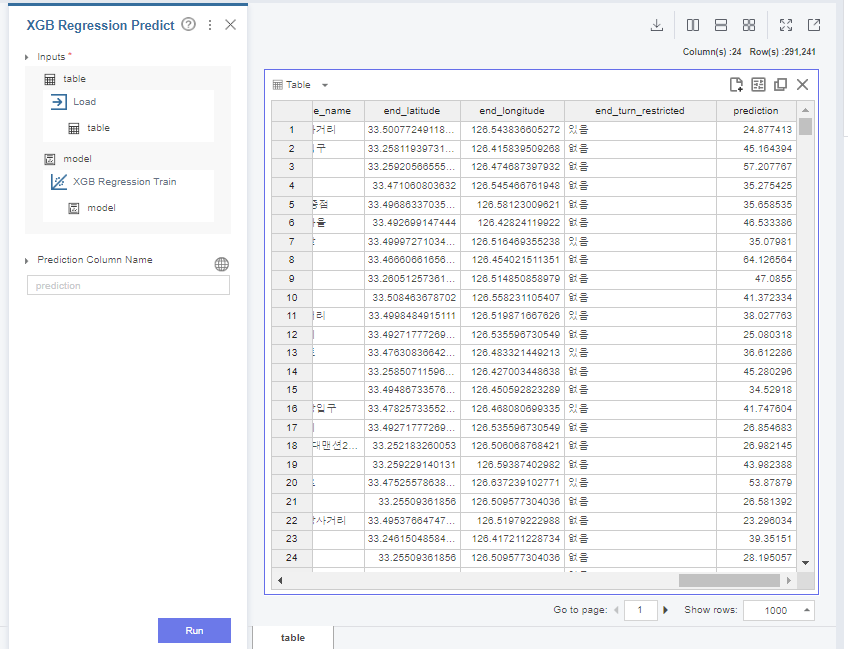
train인 full data로
학습을 다시 진행해주고,
test data로 prediction을 진행하여
label을 부착해줍니다.
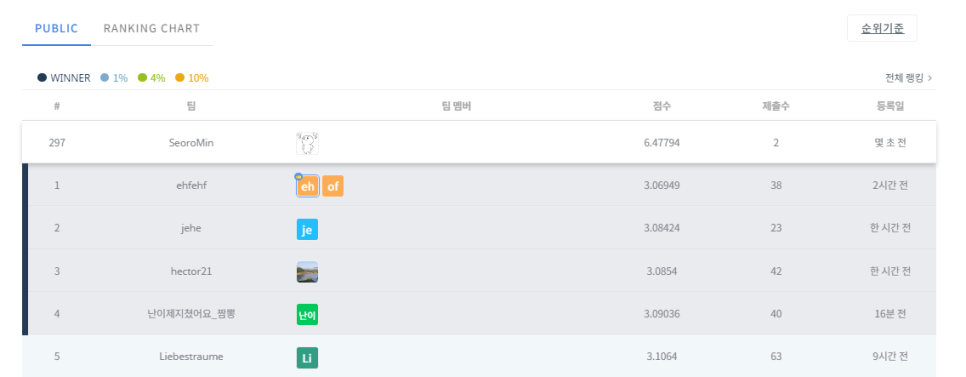
부착해주고 나서 csv형태로 dacon에 제출해봤는데요.
점수는 6.44를 가졌고
baseline mode을 형성하였습니다.
정리
많은 데이터분석가와
분석가를 꿈꾸는 분들이
dacon을 자주 이용하시는데요.
브라이틱스를 활용해서도
좋은 모델을 구현할 수 있다는 점을
보여주고 싶었습니다.
다음 포스팅에는 변수를 생성하고
실험을 비교 검증하는 과정에 대해
주로 작성할 예정입니다!
다음주도 기대해주세요

지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.

최근댓글