
안녕하세요!!
브라이틱스 서포터즈 3기 이상민입니다.
요즘 대학원 진학과 취업 준비로 인해
하루가 48시간이었으면 좋겠다는 생각을
잠깐씩 하는데요..
이에 굴하지 않고
이번 브라이틱스 프로젝트 포스팅도
열심히 작성해보겠습니다!
저번 포스팅은
baseline model을 구성했는데요.
xgboosting model을 기본 model로 삼아
dacon에 제출하고 6.44라는 score를 도출했었습니다.

이번 포스팅은 머신러닝 모델의 가장 중요한
Feature engineering에 대해 알아보겠습니다.

먼저 data scientists들이 분석을 진행함에 있어서
데이터 전처리에 80이상의 시간을 사용하는데요.
이에 따라 데이터를 model에 적합하게 만들고
유의미한 변수를 창출해서 성능을 도출하는 것이
매우 중요하다는 것을 알 수 있습니다.
그렇다면 feature engineering의 예시는 무엇이 있을까요?
정리를 하자면
feature selection (변수 추출)
feature extraction (변수 추출 or 차원축소[PCA])
feature engineering (변수 생성)
이 있고
변수 생성의 방법으로는
21~30세는 20대로 분류하여 categorical한 변수로 만들다거나
변수의 평균과 대표값을 산출한다거나
비슷한 변수들의 다중공선성을 검증해서 합친다음
새로운 변수로 만드는 기법들이 있습니다.
그럼 이와 같은 방법들의 개념을 가지고
브라이틱스에 한 번 적용해볼까요?
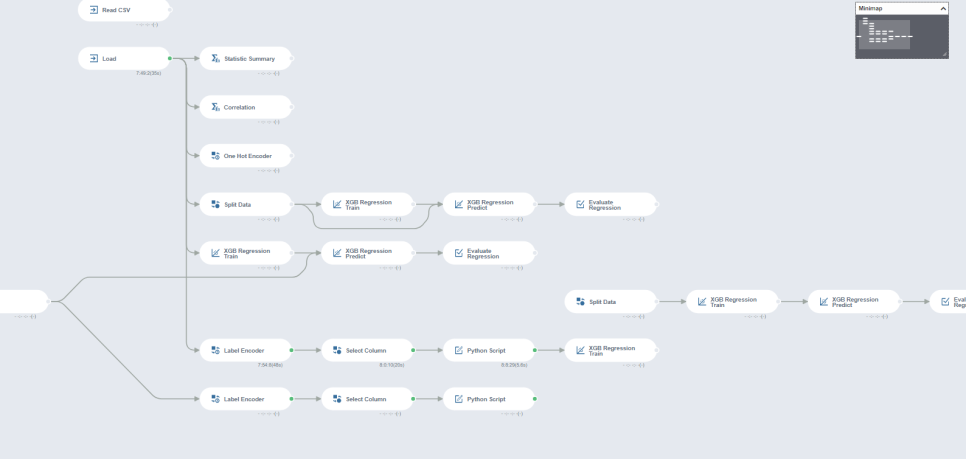
먼저 저번 포스팅에서
수치형 변수들만을 사용했는데요.
이번에는 명목형 변수를 처리하는 방법에 대해 알아보겠습니다.
명목형 변수는 '사과', '바나나'와 같이 문자형 변수를 뜻하고
이는 컴퓨터가 인식할 수 있도록 숫자로 변형해줘야 하는데요.
사과 -> 0, 바나나 -> 1
이렇게 숫자로 변형해주는 과정을 label encoding이라고 합니다.
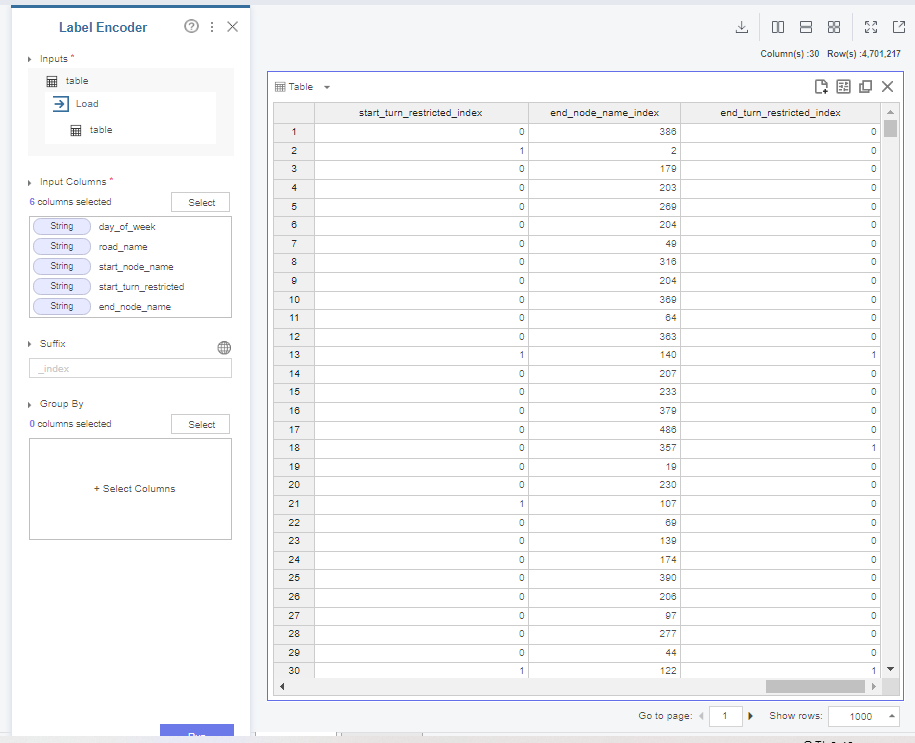
위 사진처럼 명목형 변수를 입력받아
숫자로 변형해주는 과정을 거칩니다.
사실 label encoding의 단점으로는
0,1과 같이 숫자로 변형해버리면
컴퓨터는 1이라는 숫자에 더 큰 가중치를 부여해버리는
문제점이 생기는데요.
이를 해결하고자 나온 것이 one-hot encoding이고

위 사진과 같이
값이 큰 변수에 더 큰 가중치를 부여하지 않도록
label마다 column을 새로 생성하여
해당 label에만 1을 부여하는 것을 뜻합니다.
이 기법은 서열이 없는 명목형 변수를
동등한 위치로 처리해주는 효과를 가지게 됩니다.
one-hot encoding이 브라이틱스 상에서
연산량 폭발로 처리를 하지 못해서
python에서 대신 처리해줬습니다.
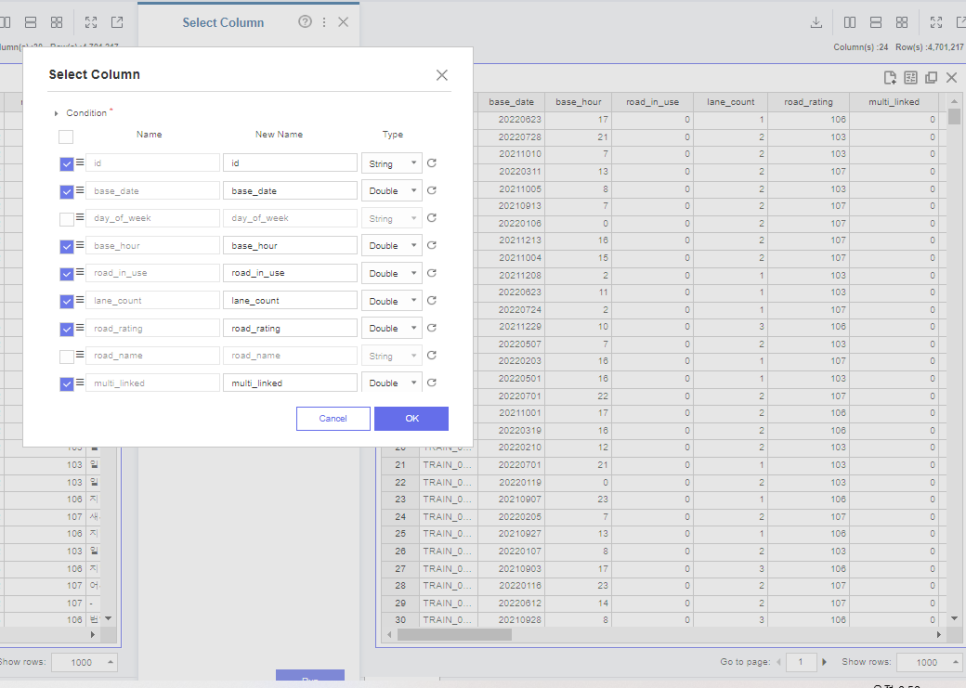
그 다음 기존 명목형 변수는 제외하고
새롭게 처리한 변수들을 추가해서 데이터로 가져옵니다.
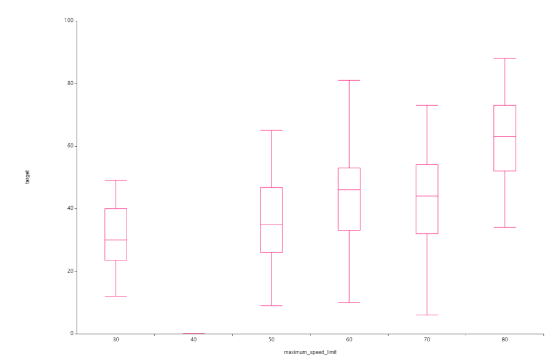
그리고 저번 EDA때
최대속도제한이라는 변수에서
40이라는 값의 이상치를 발견했었죠
이는 target값에 노이즈가 낀다고 판단하여
제거해주고자 했습니다.
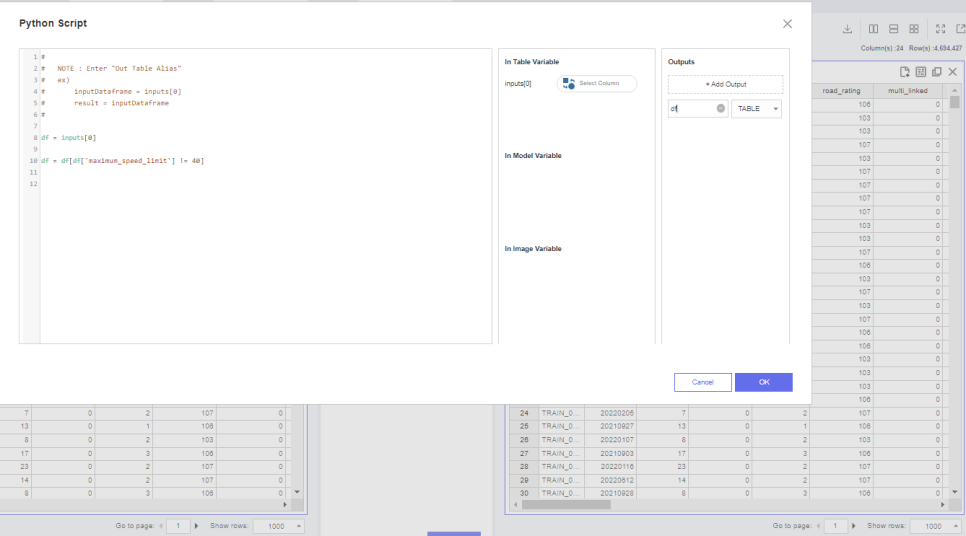
해당 방법은 python script를 사용했고
40이라는 값을 제외한 데이터만 가져오는 형식으로
처리해줬습니다.
이번 포스팅에는
기본적으로 명목형 변수를 처리해주고
유의미한 변수들만을 추출해줬는데요.
많은 지표들을 뽑아내지는 못했습니다.
다음 포스팅에는 더 많은 변수들을 생성하고
유의미한 실험을 통해 검증을
진행하도록 하겠습니다 :)
지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.

최근댓글