저번에 네이버 API를 통해 검색에서 네이버 기사를 긁어왔다면, 이번엔 python 모듈 중 하나인 beautifulsoup4로 네이버 주요뉴스를 크롤링하는 방법을 알아보기로 하자.
1. 조회수 별 랭킹 뉴스 살펴보기

네이버 랭킹뉴스는 총 4가지(조회수, 댓글 수, 공감 수, 공유 횟수)로 나누어 분류하고 있다. 그 중 조회수 순으로 정렬된 "많이 본 뉴스"에 대해서만 알아보자. 우선 뉴스는 전체적으로 정치, 경제, 사회, 생활/문화, 세계, IT/과학, 총 6가지 섹션으로 나뉘어져 있으며 시간대 별로 조회수를 집계하는 기준이 다르다. 오전 1시 ~ 오전 6시에는 별도의 집계없이 오전 1시 랭킹 결과의 노출을 유지하고, 오전 6시 ~ 오전 7시에는 오전 1시부터의 조회수를 합쳐서 집계한 랭킹을 노출하며 오전 7시 ~ 다음날 오전 1시까지는 매 시간마다 이전 한 시간 조회수를 기준으로 집계한 랭킹이 노출된다. 대신 오늘을 기준으로 이전 날짜를 선택하면 해당 일 하루 단위의 랭킹을 확인할 수 있으니, 조회 수가 많은 순으로 뉴스를 크롤링 해올 때, 오늘 날짜의 뉴스를 긁어오기 보다는 그 이전 날짜의 뉴스들을 가져오는 것이 좀 더 합리적일 것이다. (네이버 뉴스에 대한 서비스 운영 원칙은 이 곳에서 더 자세하게 살펴볼 수 있다.)
우선 각 섹션별로 뉴스의 구성이 어떻게 되어있는지 살펴보자.

살펴보니 해당 날짜별 주요뉴스는 각 섹션별로 30개까지 노출되는 것을 알 수 있다. 즉, 조회수 별로 긁어올 수 있는 뉴스의 갯수는 섹션별로 30개이며 하루에 총 180개 까지 긁어올 수 있다는 것을 알 수 있다.
2. url과 웹페이지 구성요소 살펴보기
| 정치 | https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&SectionId=100&date=20200430 |
| 경제 | https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&SectionId=101&date=20200430 |
| 사회 | https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&SectionId=102&date=20200430 |
| 문화 | https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&SectionId=103&date=20200430 |
| 세계 | https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&SectionId=104&date=20200430 |
| 과학 | https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&SectionId=105&date=20200430 |
rankingType=popular_daty&까지 변함이 없다가 SectionId와 date별로 조회수별로 집계되는 랭킹뉴스가 달라지는 것을 알 수 있다. 만약 4월 30일에 모든 섹션의 주요뉴스를 크롤링해오고 싶으면 "date=20200430"으로 고정해놓고 SectionId를 100~105까지 돌며 뉴스를 긁어오면 될 것이고, 만약 경제 섹션의 주요뉴스를 1월부터 4월까지 크롤링해오고 싶으면 "SectionId=101"로 고정해놓고 date를 20200101~20200430까지 돌면 될 것이다.

웹페이지 구성요소를 살펴보면 뉴스와 관련된 정보로는 해당 뉴스의 제목과 조회수, 짧은 내용, 링크 정도가 될 것이다. "ctrl + shift + n"을 통해 해당 페이지의 코드를 열어 어떤 속성에서 위와 같은 정보를 얻어낼 수 있는지 살펴보자.
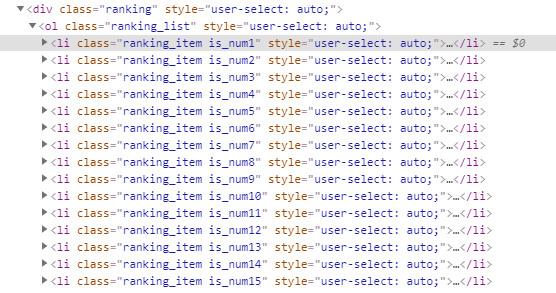
보니 해당 뉴스들의 정보들은 rangking_list라는 <ol>태그 안에 ranking_item is_numX라는 <li>태그로 묶여있었다. 그 안에서 제목, 헤드라인은 ranking_headline 클래스가 있는 <div>태그 안에 <a>태그의 title클래스로, 링크는 그 <a>태그의 href클래스로 묶여있다. 또한 조회수는 ranking_view 클래스가 있는 <div>태그 안에 내용으로 묶여있었다. 이를 잘 활용해서 DataFrame으로 정리하면 보기좋기 정리될 것이다.
해당 주요뉴스의 내용도 함께 크롤링해오고 싶었지만 위의 웹페이지에서 보듯이 소스 코드에도 그 정도 짧은 내용정도 밖에 들어있지 않아서 해당 뉴스기사의 전문을 긁어오고 싶으면 위에서 크롤링한 링크로 접근하여 직접 그 뉴스를 가져와야할 것이다. 다음에는 위에서 설명한 내용을 바탕으로 네이버 주요뉴스를 조회수별로 크롤링해오는 코드를 짜보자.
'데이터 분석 & 시각화 > Crawling' 카테고리의 다른 글
| 다음 랭킹 뉴스 크롤링 (0) | 2021.01.31 |
|---|---|
| 네이버 랭킹 뉴스 크롤링 (1) | 2021.01.28 |
| 크롤링 (5), beautifulsoup4로 네이버 기사 크롤링하기 (5) | 2020.05.02 |
| 크롤링(3) (0) | 2020.04.15 |

최근댓글