.rolling( )
(count_day, count_week)
해당 실습에서는 빈도(frequency)를 시간('H')으로 설정했다. 하지만, 이 데이터에서 시간으로 빈도를 설정하는 것이 가장 옳은 방식이라고 단정할 수는 없다. 시간 외에도 일(Day), 주(Week)의 단위에 대해서도 데이터를 분석해봐야 하고, 이때 사용할 수 있는 함수가 .rolling( )이다.
pd.concat([raw_all[['count']],
raw_all[['count']].rolling(24).mean(),
raw_all[['count']].rolling(24*7).mean()], axis = 1).plot(kind = 'line', figsize = (20, 6), linewidth = 3, fontsize = 20,
xlim= ('2012-01-01', '2013-01-01'), ylim = (0, 1000))
plt.title("Time Series of Target", fontsize = 20)
plt.xlabel("Index", fontsize = 15)
plt.ylabel('Demand', fontsize = 15)
plt.show()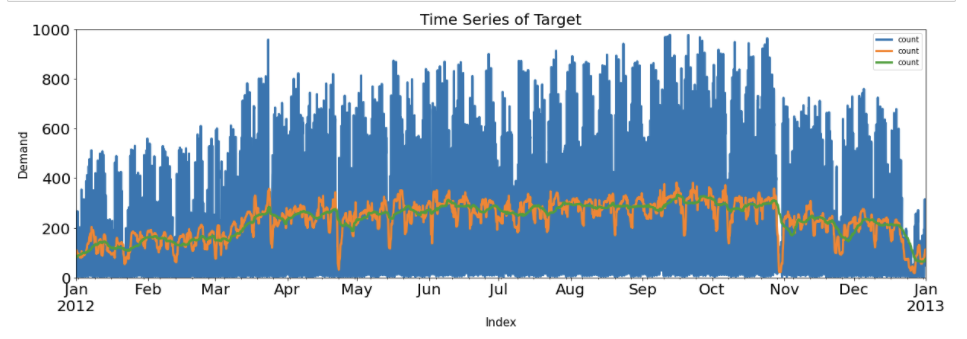
코드에서도 볼 수 있듯이, 단지 .rolling( ) 함수만을 사용하는 것이 아니라, 뒤에 .mean( ) (평균을 사용할 때), 혹은 .sum( )(총합을 사용할 때) 등을 사용해서, rolling에 입력받은 수만큼의 단위를 묶어 해당 계산을 한 뒤 값을 반환한다. 여기에서는 평균값을 사용했다.
파란색 선이 시간에 따른 자전거 수요량, 주황색 선이 일(Day)에 따른 자전거 수요량, 초록색 선이 주(Week)에 따른 자전거 수요량을 시각화한 것이다.
rolling 함수를 사용하게 되면 해당 날짜를 포함하여 입력으로 받은 수만큼 앞의 날짜에 대한 수치를 가져와 하나로 묶는 역할을 하는 함수이다. 예를 들어 .rolling(24)를 사용한다면, 0번째에서 22번째 인덱스까지는 NaN값을 가지게 된다. NaN값을 채워주기 위해서 .fillna( )의 method를 사용해서 자동으로 뒤의 데이터를 가져올 수 있도록 만든다.
Y_count_Day = raw_all[['count']].rolling(24).mean()
Y_count_Day
raw_all에 rolling(24)와 rolling(24 * 7)의 데이터를 pd.concat( ) 으로 추가할 수 있다.
# fill nan as some values and merging
Y_count_Day = raw_all[['count']].rolling(24).mean()
Y_count_Day.fillna(method='ffill', inplace=True)
Y_count_Day.fillna(method='bfill', inplace=True)
Y_count_Day.columns = ['count_Day']
Y_count_Week = raw_all[['count']].rolling(24*7).mean()
Y_count_Week.fillna(method='ffill', inplace=True)
Y_count_Week.fillna(method='bfill', inplace=True)
Y_count_Week.columns = ['count_Week']
if 'count_Day' not in raw_all.columns:
raw_all = pd.concat([raw_all, Y_count_Day], axis=1)
if 'count_Week' not in raw_all.columns:
raw_all = pd.concat([raw_all, Y_count_Week], axis=1)
raw_all
앞의 값과 차이를 계산하는 .diff( )
(count_diff)
단순히 종속변수 Y ('count')의 값 자체로만 분석을 하는 것에 더해서, 시간이 지남에 따라 Y의 값이 어떻게 변화하고 있는지에 대해서도 분석을 할 수 있다. 이런 경우에는 현재 값을 이전의 값으로 뺀 값을 별도의 데이터로 지정한다.
Y_diff = raw_all[['count']].diff()
Y_diff.fillna(method = 'bfill', inplace = True)
Y_diff.fillna(method = 'ffill', inplace = True)
Y_diff.columns = ['count_diff']
if 'count_diff' not in raw_all.columns:
raw_all = pd.concat([raw_all, Y_diff], axis = 1)
raw_allSeries.diff( )를 사용해서 이를 구현할 수 있고, raw_all 에 'count_diff'라는 column으로 합친다.
카테고리형 변수를 만드는 pd.cut( )
('temp_group')
기존 raw_all의 데이터에서 'temp'는 온도를 나타내고, 연속적인 float형으로 데이터가 구성이 되어있는 것을 확인할 수 있다. 수치로서 데이터 분석을 하는데에 영향이 있을 수도 있지만, 조금 더 명확한 분류를 하기 위해서 특정 구간들로 나누어서 이것들을 카테고리화 할 수 있다. 이 때 사용하는 함수가 pd.cut( ) 이다.
raw_all['temp_group'] = pd.cut(raw_all['temp'], 10)
raw_all['temp_group'].dtype
#카테고리 형으로 되어있어 추가적인 FE가 더 필요하지만 일단은 이런 것이 있다라는 정도로만 생각을 할 수 있으면 된다.

pd.cut( )은 연속된 숫자형에서 처음과 끝의 범위를 기준으로 사용자가 지정하는 카테고리의 개수만큼을 동일한 간격으로 나누어 카테고리화를 진행한다.
datetime 데이터 타입을 이용하여 세부 시간 추출
(Year, Quarter, Month, Day, Hour, DayofWeek)
시계열 데이터 분석 코드 - 1에서 datetime 데이터 타입에 관하여 다루었었다. 그 때, 추후 추가적인 데이터 전처리 과정을 위해서 하나의 열 'datetime' 을 더 만들었었다. 이제 'datetime' 특성을 활용해서, 우리가 원하는 시간의 정보를 추출할 수 있다.
raw_all['Year'] = raw_all.datetime.dt.year
raw_all['Quarter'] = raw_all.datetime.dt.quarter
raw_all['Quarter_ver2'] = raw_all['Quarter'] + (raw_all.Year - raw_all.Year.min()) * 4
raw_all['Month'] = raw_all.datetime.dt.month
raw_all['Day'] = raw_all.datetime.dt.day
raw_all['Hour'] = raw_all.datetime.dt.hour
raw_all['DayofWeek'] = raw_all.datetime.dt.dayofweek
raw_all(추가적으로 DataFrame에서 특정 열을 지칭할 때에는 DataFrame['column']의 형식으로 지칭할 수도 있지만, DataFrame.column의 형식으로 지정할 수도 있다. )
위와 같이, datetime 데이터 형식을 가지고 있는 객체에 원하는 시간을 추출하는 방법은 상당히 간단하다.
특징적으로 봐야할 점은 'Quarter'와 'Quater_ver2'이다.
데이터를 확인해보면 알겠지만, 2011년과 2012년의 시간에 대한 데이터이다. 이 때, 'Quater'와 같이, 단순히 분기로 나누면, 2011년의 1분기인지, 2012년의 1분기인지 구별할 수 없는 상황이 발생한다. 따라서, 2012년에는 분기에 4를 더한 값이 들어갈 수 있도록 하였다.
(raw_all.Year == 2011이면 4 * 0이 더해지고, raw_all.Year == 2012이면 4 * 1이 더해진다.)
지금까지 데이터 전처리를 한 결과 현재 raw_all의 DataFrame이 어떻게 변화했는지 확인해보자.
raw_all.info()
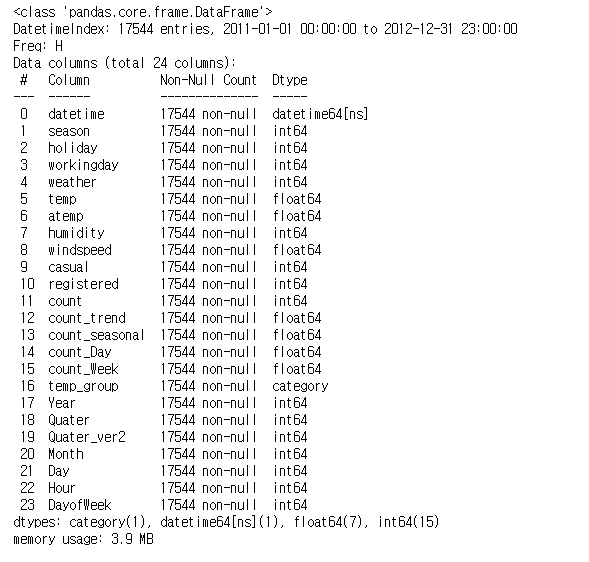
11번 열인 'count' 이후로 23번 열까지는 데이터 전처리 과정에서 새롭게 생성된 열이라는 것을 확인할 수 있고, temp_group은 category형 데이터 타입, 그 외에는 숫자형 데이터 타입을 가지고 있다는 것을 확인할 수 있다.
'딥러닝 > 시계열' 카테고리의 다른 글
| 시계열 분석 실습 코드 - 4 (0) | 2021.02.19 |
|---|---|
| 시계열 분석 실습 코드 - 3 (0) | 2021.02.18 |
| 시계열 데이터 분석 실습 코드 - 1 (0) | 2021.02.16 |
| 시계열 데이터 분리, 분석 성능 확인 (검증지표, 잔차진단) (0) | 2021.02.16 |
| 시계열 데이터 패턴 추출 (Feature Engineering) 1 (3) | 2021.02.01 |

최근댓글