데이터는 이전 포스팅에서 어디에서 가져올 수 있는지 확인 가능하다.
데이터 불러오기
!python -m pip install --user --upgrade pip위의 코드를 주피터 노트북에서 실행함으로써, anaconda prompt에서 입력해야 하는 명령어를 주피터 노트북 상에서 실행할 수 있다.
#ignore wanrings
import warnings
# warnings.filterwarnings('always') # 항상 warning이 뜨도록 설정
warnings.filterwarnings('ignore')
#System related and data input controls
import os
#Data manipulation and visualization
import pandas as pd
pd.options.display.float_format = '{:.2f}'.format
pd.options.display.max_rows= 100
pd.options.display.max_columns = 20
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#Modeling algorithms
#General
import statsmodels.api as sm
from scipy import stats
#Model selection
from sklearn.model_selection import train_test_split
#Evaluation metrics
#for regression
from sklearn.metrics import mean_squared_error, mean_squared_log_error, r2_score, mean_absolute_error
#location = 'https://raw.githubcontent.com/...'
location = './Data/BikeSharingDemand/Bike_Sharing_Demand_Full.csv'
raw_all = pd.read_csv(location)
# raw_all데이터 분석에서 사용할 모듈들을 import 한다. 그 후, 데이터를 저장한 디렉토리를 location이란 변수에 저장하고, pd.read_csv( ) 함수를 통해서 데이터 프레임으로 불러온다.

정상적으로 데이터 프레임으로 불러와 졌다면 위의 이미지와 같은 데이터 프레임을 확인할 수 있다.
인덱스 설정 및 결측치(NaN) 확인하기
(Datetime, datetime)
if 'datetime' in raw_all.columns:
raw_all['datetime'] = pd.to_datetime(raw_all['datetime'])
raw_all['DateTime'] = pd.to_datetime(raw_all['datetime'])# 다른 활용을 위해서 하나 더 만들어 놓음
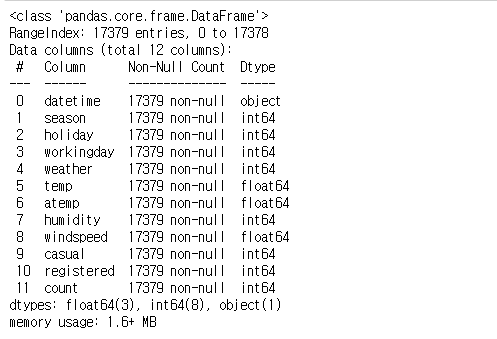
raw_all.info()
if raw_all.index.dtype== 'int64':
raw_all.set_index('DateTime', inplace = True)
raw_all가장 첫번째 열에 있는 'datetime'이라는 열을 raw_all.info( )를 통해서 확인하면, object 데이터 형식으로 되어있는 것을 확인할 수 있다. object data type은 string 형태라고 생각하면 된다.
날짜 형식으로 적혀 있지만, 현재 데이터 프레임에서는 string으로 인식하고 있으므로, pd.to_datetime( )을 활용하여, object 형식을 datetime64 형식으로 변환한다. 그 후에, datetime 열의 data type이 변환되었는지 확인한 후에, DataFrame의 인덱스를 해당 'Datetime'으로 바꾼다.
Dtype이 datetime64인 경우에는 해당 "column.dt.시간단위" 를 통해서 원하는 시간의 부분을 추출하여 활용할 수도 있다.
(여기에서 datetime, Datetime 두 개의 열로 저장한 이유는 추후에 다른 방식으로 활용할 가능성이 높기 때문에, 인덱스로 활용하는 것 이외에도 여분으로 더 만들어 놓은 것이다. )

raw_all.isnull()
raw_all.isnull().sum()
raw_all.isnull().sum().sum()인덱스까지 설정하는 것을 마쳤다면, 원본 데이터 형식에 NaN값 (결측치)이 들어있는지 확인해야 한다.
첫번째 코드를 실행하면, NaN값이 있는 위치에서만 True이고, 나머지는 False로 채워진 DataFrame을 반환한다.
두번째 코드는 각 열마다 NaN값이 몇개가 있는지를 표의 형태로 보여준다.
세번째는 총 NaN값의 수를 반환한다.
빈도 (Frequency) 설정하기
※ 빈도 : 데이터를 분석하면서 설정하는 시간의 최소 단위
raw_all.index위에서 설정한 raw_all의 인덱스를 확인해보자.
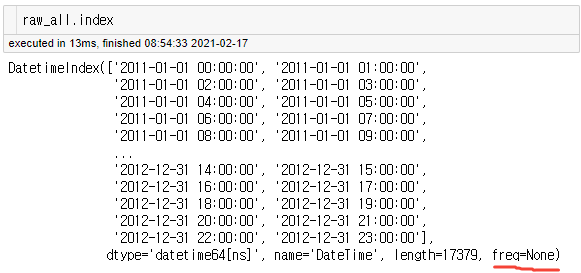
빨간색 밑줄이 쳐져있는 부분이 Frequency를 나타내고 있는 부분이다. 아직까지 빈도에 대해서는 설정해준 것이 없기 때문에 None으로 되어있는 것을 확인할 수 있다. 이를 설정해주기 위해서는 pd.asfreq( ) 를 통해서 설정할 수 있다. 이렇게 빈도를 설정하게 되면, 데이터에 있는 시간 범위 내에 해당 시각이 없는 경우, 자동으로 NaN으로 채워진 새로운 행이 채워진다.
raw_all.asfreq('H')[raw_all.asfreq('H').isnull().sum(axis = 1) >0]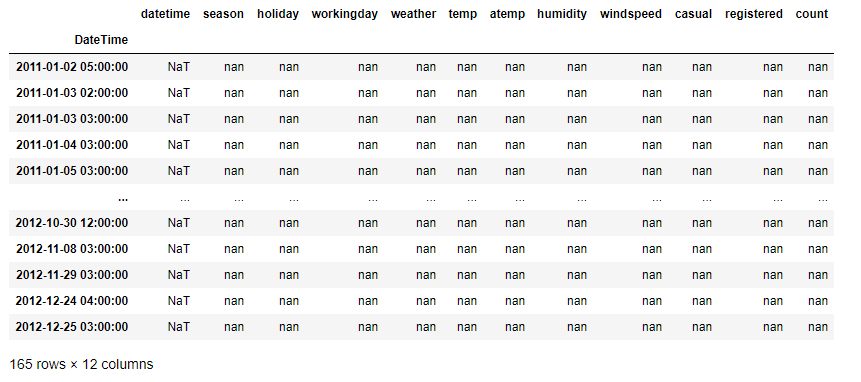
빈도를 시간('H')으로 설정했을 때, 비어있던 행(새롭게 생성한 행)만을 추출해서 DataFrame으로 만든 결과이다. 확인해보면, 2011-01-02 5시, 2011-01-03 2시 등의 기존의 DataFrame에서는 없던 행이었고, NaN값들로 채워져 새롭게 생성된 것을 볼 수 있다.
raw_all.asfreq('H').isnull().sum()
raw_all = raw_all.asfreq('H', method = 'ffill')
raw_all.isnull().sum()첫번째 줄은 이렇게 새롭게 생긴 행의 개수를 각 열마다 확인하기 위한 코드이고, 두번째 줄은 이렇게 생성된 행을 앞 혹은 뒤의 데이터를 이용해서 자동으로 채워지도록 하기 위해서 method 파라미터에 'bfill', 'ffill'을 입력한 것이다.
(bfill은 뒤의 데이터 값을 그대로 가져와 결측치 대신 사용하는 것을 의미하고, ffill은 앞의 데이터 값을 그대로 가져와 결측치 대신 사용하는 것을 의미한다.)
그후 다시 결측치를 확인해보면 결측치가 0개가 된 것을 확인할 수 있다.
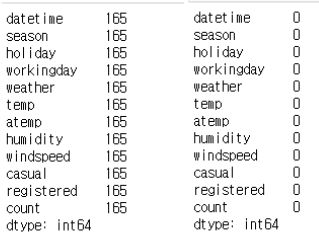
이렇게 새롭게 빈도를 설정하고 다시 인덱스를 확인해보자.
raw_all.index
오른쪽 하단을 보면 아까는 None이었던 frequency가 'H'로 변경된 것을 볼 수 있다.
Y와 관련된 'count' 'casual' 'registered' 열 시각화 및 시계열 요소 추출
(count_trend, count_seasonal)
count는 데이터에서 최종적으로 예측할 종속변수에 해당한다. (자전거 총 수요)
casual은 비회원이 자전거를 대여해서 타는 횟수를, registered는 등록한 회원이 자전거를 대여해서 타는 횟수를 의미한다. 즉, count는 casual과 registered를 합한 값이다.
raw_all[['count','registered','casual']].plot(kind = 'line', figsize = (20, 6), linewidth = 3, fontsize=20,
xlim = ('2012-01-01', '2012-06-01'), ylim = (0, 1000))
plt.title('Time Seires of Target', fontsize = 20)
plt.xlabel('Index', fontsize = 15)
plt.ylabel('Demand', fontsize = 15)
plt.show()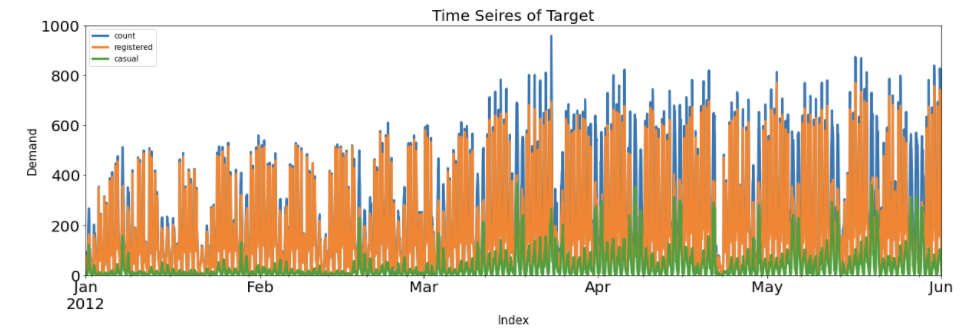
sm.tsa.seasonal_decompose(raw_all['count'], model = 'additive').plot()
plt.show()
result = sm.tsa.seasonal_decompose(raw_all['count'], model = 'additive')
result = sm.tsa.seasonal_decompose(raw_all['count'], model = 'additive')
Y_trend = pd.DataFrame(result.trend)
Y_trend .fillna(method = 'bfill', inplace = True)
Y_trend.fillna(method = 'ffill', inplace = True)
Y_trend.columns = ['count_trend']
Y_trend.iloc[:20, :]
Y_seasonal = pd.DataFrame(result.seasonal)
Y_seasonal.fillna(method = 'bfill', inplace = True)
Y_seasonal.fillna(method = 'ffill', inplace = True)
Y_seasonal.columns = ['count_seasonal']
Y_seasonal.iloc[:20, :]첫번째 줄의 코드를 실행하면, sm.tsa.seasonal_decompose( )라는 함수를 이용하여 Y값에 대해 trend, Seasonal, Resid값을 자동을 분리하여 보여준다.
(sm과 tsa는 관련 모듈들을 import하는 코드에서 확인하면, 정확히 어떤 모듈을 사용하는 것인지 알 수 있다.)
Trend와 Seasonal에 대한 특성은 해당 행과 주위의 행을 동시에 이용하기 때문에 앞뒤로 특정한 개수의 데이터 만큼은 Trend와 Seasonal이 NaN으로 되어있는 것을 학인할 수 있다. 이 경우에는 pd.fillna( )를 활용해서 결측치를 채워놓는다.
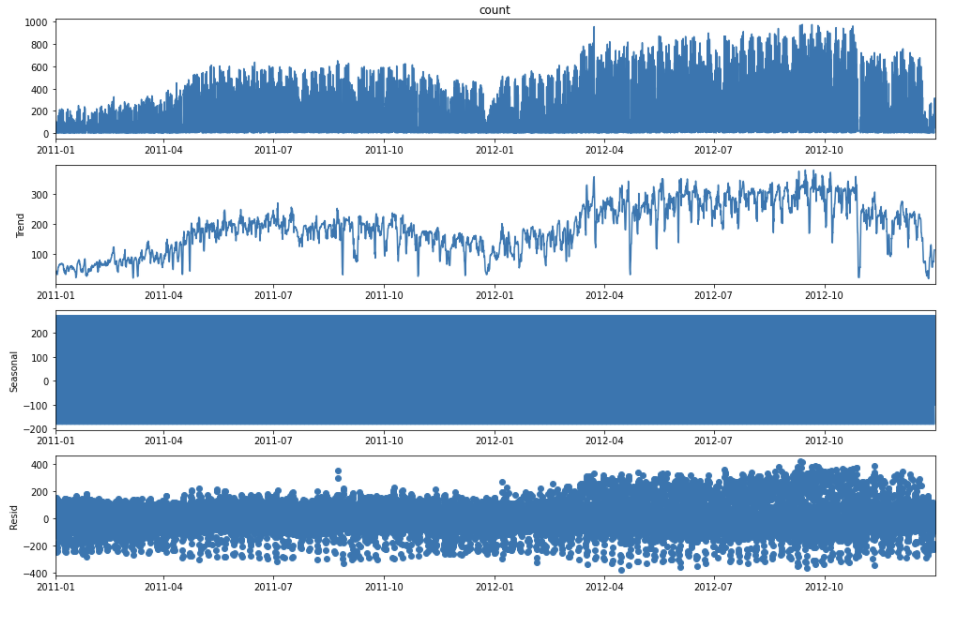
이때, pd.seasonal_decompose( )에서 model 파라미터에는 'additive'와 'multiplicative'가 들어갈 수 있다.
additive : Trend, Seasonal, Resid가 더해져서 해당 값을 구성한다고 가정
multiplicative : Trend, Seasonal, Resid가 곱해져서 해당 값을 구성한다고 가정
if 'count_trend' not in raw_all.columns:
if 'count_seasonal' not in raw_all.columns:
raw_all = pd.concat([raw_all, Y_trend, Y_seasonal], axis = 1)
raw_allseasonal_decompose( ) 후 세가지 특성 각각에 접근할 수도 있다. 위의 코드와 같이 시계열 요소 추출을 저장해놓은 변수 뒤에 .trend, .seasonal, .resid를 통해서 각각의 값에 접근이 가능하고, 실제로 여기에서는 trend와 seasonal을 'count_trend'와 'count_seasonal'이라는 새로운 열을 만들어 원본 DataFrame에 추가하였다.
Reference :
패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
'딥러닝 > 시계열' 카테고리의 다른 글
| 시계열 분석 실습 코드 - 3 (0) | 2021.02.18 |
|---|---|
| 시계열 데이터 분석 코드 - 2 (0) | 2021.02.17 |
| 시계열 데이터 분리, 분석 성능 확인 (검증지표, 잔차진단) (0) | 2021.02.16 |
| 시계열 데이터 패턴 추출 (Feature Engineering) 1 (3) | 2021.02.01 |
| 데이터 분석, Cycle, 용어 (0) | 2021.01.30 |

최근댓글