이전 포스팅에서는 조건수가 데이터 분석에서 어떤 영향을 끼치는 지에 대해서 알아보았다.
조건수가 커지게 되면 X의 값이 조금만 변화하더라도, 예측 결과가 크게 변화하기 때문에, 조건수를 줄이는 방향으로 데이터 분석을 진행해야 한다는 것을 알아보았다.
조건수를 줄이는 방법
조건수를 줄이는 방법 중 크게 2가지에 대해서 알아볼 것이다.
1. Scaling
2. 다중 공선성 제거
1. Scaling
스케일링은 데이터의 각 Column마다 단위가 다르기 때문에, 단순히 각 Column들의 Variance를 보고 데이터를 정확하게 파악하기 힘들다. 이런 어려움을 없애기 위해서 범위를 일반적으로 0 ~ 100까지 의 비율로 통일시키는 과정을 Scaling이라고 부른다.
Scaling의 방법에도 여러가지가 있다.
1 - 1. Standard Scaler
(X값) - (평균 ) / 표준편차 의 계산을 통해서 스케일링을 진행한다.
가정 : 각 변수가 정규분포를 따른다.
(이 가정에 부합하지 않는다면, 최선의 방안이 아닐 확률이 높다.)
1 - 2. Min-Max Scaler
(X값) - (최솟값) / {(최댓값) - (최솟값)}
일반적으로 가장 많이 사용한다.
분포의 모습은 보존하고 Scale 만 동일하도록
단, Outlier나 표준 편차가 커지게 되면 왜곡 가능성이 존재한다.
1 - 3. Robust Scaler
Min-Max Scaler가 Outlier에 취약하다는 단점을 보완하기 위해서
최댓값 ⇒ 상위 25%의 데이터
최솟값 ⇒ 하위 25%의 데이터
를 대체하여 사용한다.
위와 같은 설정을 해줌으로써 Outlier의 영향을 덜 받으면서 Scaling을 진행하는 것이 가능하다.
주로 Min-Max / Robust가 가장 많이 사용되지만, 모든 상황에서 항상 효과적이라고 단정지을 순 없다.
따라서, 모든 방법을 다 시도하고 성능이 가장 좋은 방법을 선택하는 식으로 데이터 분석을 진행해야 한다.
2. 다중 공선성 제거
다중 공선성(Multicollinearity)이라는 용어 자체도 생소할 확률이 높다.
다중 공선성은 회귀 분석에서 등장하는 단어로, 수리적으로는 어떤 독립 변수(X의 특정 column)가 다른 독립 변수 들과 완벽한 선형 독립이 아닌 경우를 의미한다.
일반적으로 데이터 분석에서 다중 공선성의 의미는 회귀 분석에서 사용된 모형의 일부 설명 변수가 다른 설명 변수와 상관정도가 높아 데이터 분석시 부정적인 영향을 미치는 경우를 의미한다.
다중 공선성 → 독립 변수 공분산 행렬의 조건수 증가 → 과적합
다중 공선성은 언제 발생할까?
- 독립 변수의 일부가 다른 독립 변수의 조합으로 표현이 가능한 경우
- 독립 변수들이 서로 독립이지 않고, 상호 상관 관계가 강한 경우
- 독립 변수의 공분산 행렬 벡터 공간의 차원과 독립 변수의 차원이 같지 않은 경우
위의 세가지 표현은 수리적으로 다중 공선성이 발생하는 경우를 기술한 것이고, 우리가 쉽게 이해를 하는데에는 데이터의 특성들이 독립된 관계를 가지지 않고, 서로 연관성이 강하다는 점을 알고 있으면 이해하기 쉽다.
다중 공선성을 줄이는 방법
이제 다중 공선성이 언제 어떻게 발생하는지 알아봤으니, 다중 공선성을 줄이기 위한 2가지 방법을 알아보자.
2 - 1. VIF (Variance Inflation Factor)
독립성이 강한 특정 개수의 X 피처를 선택하여 그것만 분석에 사용하는 기법
즉, 다른 column들의 선형 조합으로 표현이 가능한 column을 배제하고, 나머지 column들만 분석에 사용하는 기법이다.
독립성을 판단하는 기준
독립 변수를 다른 독립 변수들로 선형회귀한 성능을 비교하여 상호 의존적인 독립 변수를 제거한다.
예를 들어 한가지 특성을 나머지 특성들의 선형 회귀한 결과로 성능 지표를 나타내었을 때, 성능이 좋게 나온 것이 "의존성이 강하다"라고 판단을 할 수 있다.
(이 경우에 성능 지표로 R-Square 수치를 이용한다.)
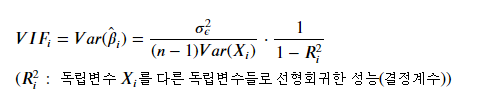
정확하게는 위의 식을 사용하여 각 Column에 대한 VIF 값들을 도출한 뒤 이들을 비교한다.
하지만, 정확한 VIF 값이 필요하지 않은 경우에는 R-Square값과 비례한다고 생각을 하는 것이 간편하다.
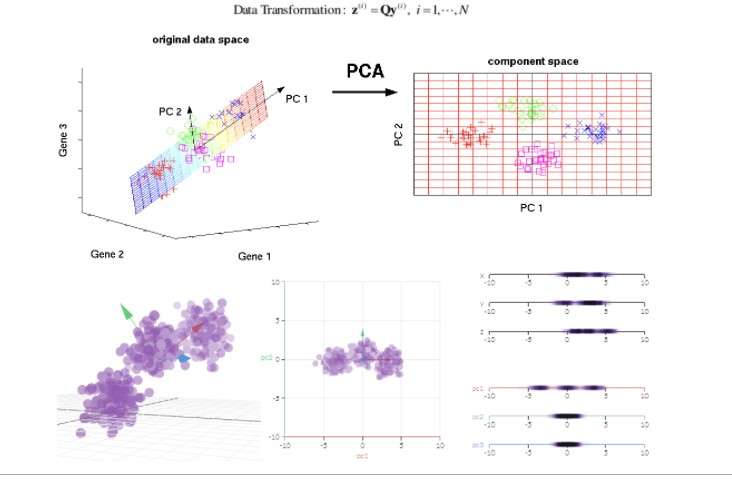
2-2. PCA
PCA = Principal Component Analysis
데이터를 가장 잘 나타낼 수 있는 차원과 축을 정해서 해당 축을 각 X의 column으로 지정하는 것.
특징적인 부분은, 변수를 선택하는 것이 아니라, 해당 변수들 간 축을 재설정하는 것이기 때문에, 분석 성능은 좋을지라도, 설명력이 떨어진다.
그래서, 원인을 분석해야하는 경우에는 적합하지 않다.
참고 :
다중공선성(Multicollinearity) 이란?
오늘 포스팅의 주제는 통계학에서 가장 핫한 이슈 중에 하나입니다. 학부 수업에도 꽤나 자주 등장하며 실...
blog.naver.com
패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
'딥러닝 > 시계열' 카테고리의 다른 글
| 정규화 방법론 알고리즘 (0) | 2021.03.24 |
|---|---|
| 정상성 (0) | 2021.03.22 |
| 조건수(Condition Number)에 대한 이해 (0) | 2021.03.14 |
| [논문 Review] 콜센터 인입 콜량 예측을 위한 시계열 모델 비교 분석 2 (0) | 2021.03.13 |
| [논문 Review] 콜센터 인입 콜량 예측을 위한 시계열 모델 비교 분석 1 (0) | 2021.03.12 |

최근댓글