정규화 방법론
선형회귀 분석을 통해서 계산된 계수(Weight)에 대한 제약 조건을 추가함으로써 과적합(Overfiiting)을 방지하는 방법
일반적으로 과적합은 계수의 크기를 엄청나게 증가시키는 경우에 많이 발생하므로, 정규화 방법론에서 사용하는 제약 조건은 계수의 크기를 제한하는 방법이 많이 사용된다.
참고> argmin
앞으로 선형 회귀 등 여러 기계학습 알고리즘을 접하다 보면, argmin이라는 기호를 접할 때가 있다.
argmin은 뒤의 식을 최소로 만드는 해당 변수의 값을 찾아낼 때 사용하는 것으로

대괄호 안에 있는 식은 ( x - 1) ^ 2이므로, x = 1인 경우에 최솟값 0을 가진다. 이런 경우에 x_hat에는 대괄호 안에 있는 식을 최솟값으로 만드는 x의 값인 1을 x_hat에 할당한다.
정규화 회귀 분석 알고리즘
1. 일반 회귀 분석
실제 Y의 값과 예측한 Y값인 Y_hat의 차이를 최소화하도록 하는 것.

2. Ridge Regression
기존의 비용함수에서 각 계수의 제곱합을 추가한 비용함수

제곱수를 더한 것이므로, 절댓값이 큰 수의 감소가 절댓값이 작은 수의 감소보다 비용함수식에 더 큰 영향을 미친다. ( 동일하게 1을 줄이는 경우에, 10 → 9 로 줄이는 경우 제곱수는 100에서 81로 19가 감소하는 반면, 1 → 0 으로 줄이는 경우 제곱수는 1에서 0으로 1만 감소한다.)
3. Lasso Regression
기존의 비용함수에서 각 계수의 절댓값의 합을 추가한 비용함수

위에서 설명한 Ridge와 비교하여 설명하자면, 위에서는 절댓값이 큰 계수의 감소를 우선적으로 실행했다면, 이 방법으로는 전반적인 계수들을 동시에 줄이는 것이다. 따라서, 상대적으로 계수를 0으로 만드는 데에 초점을 두는 역할을 한다.
이런 원리로 인해서 변수 선택의 기능이 있어 사용이 많이 되는 방법이다. 하지만, 특정 변수에 대한 계수가 커지는 단점이 발생한다.
4. Elastic Net

Ridge와 Lasso의 두가지 방법을 동시에 사용하여 정규화를 하는 방법이다.
큰 데이터 셋에서는 효과가 좋지만, 작은 데이터 셋에서는 효과적이지 않다.
2 ~ 4의 식을 보면, 선형 회귀 비용함수 식 뒤에 계수의 제곱합, 절댓값의 합을 나타내는 시그마 식앞에 lambda 계수가 붙어있는 것을 확인할 수 있다. 이것은 사용자가(분석하는 사람)이 직접 정해주는 하이퍼 파라미터로, 계수들을 얼마나 강하게 정규화 시킬지에 따라서 lambda를 크게 하거나 작게 설정할 수 있다.
코딩으로 해당 정규화 방법론을 사용하는 경우에는 통상적으로
사이킷런에 내재되어 있는 Ridge, Lasso, ElasticNet의 함수를 사용한다.
from sklearn.linear_model import Ridge, Lasso, ElasticNet
해당 함수를 사용하면, 그대로 구현이 되고, 방금 위에서 얘기한 lambda 계수를 설정해주는 것은 함수 내의 alpha라는 파라미터에 해당하는 lambda 계수를 입력해야 된다.
예시>
alpha_weight = 0.5
fit = Ridge(alpha = alpha_weight, fit_intercept = True, normalize = True, random_state = 123).fit(X, y)
pd.DataFrame(np.hstack([fit.intercept_, fit.coef_]),columns = ['alpha = {}'.format(alpha_weight)])( fit_intercept 파라미터는 상수항 계수를 추가 할것인지 여부를 확인하는 것이고, normalize는 fit_intercept 파라미터가 True로 지정이 된 경우에, 회귀 분석 이전에 X를 정규화 할지 여부를 설정해 주는 파라미터이다. )
실습
import warnings
warnings.filterwarnings('always')
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, Lasso, ElasticNet실습을 하는데 필요한 모듈들을 import 한다.
diabetes = datasets.load_diabetes()
X = diabetes.data
y = diabetes.target
print('Data View')
display(pd.concat([pd.DataFrame(y, columns=['diabetes_value']), pd.DataFrame(X, columns=diabetes.feature_names)], axis=1).head())사이킷 런에 있는 당뇨병 데이터를 불러오고, 이것을 DataFrame의 형태로 만든다.

# Ridge 사용
alpha_weight = 0.5
fit = Ridge(alpha=alpha_weight, fit_intercept=True, normalize=True, random_state=123).fit(X, y)
pd.DataFrame(np.hstack([fit.intercept_, fit.coef_]), columns=['alpha = {}'.format(alpha_weight)])
#Lasso 사용
alpha_weight = 0.5
fit = Lasso(alpha=alpha_weight, fit_intercept=True, normalize=True, random_state=123).fit(X, y)
pd.DataFrame(np.hstack([fit.intercept_, fit.coef_]), columns=['alpha = {}'.format(alpha_weight)])각각 Ridge와 Lasso를 사용해서 정규화를 실행하고, 결과로 나오는 DataFrame을 확인한다.
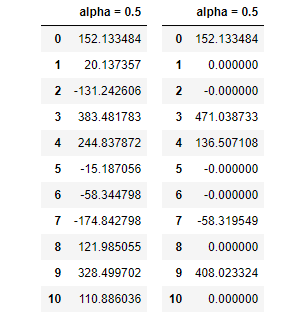
확실하게 오른쪽에 Lasso를 사용했을 때, 계수가 0이 되는 것들이 왼쪽과 비교해서 훨씬 많은 것을 확인할 수 있다.
시각화
이번에는 각 Ridge와 Lasso의 lambda(코드에서는 alpha)의 계수를 변화시켜가며, 계수들이 어떤 방향으로 변화하는지에 대해서 살펴보자.
result_Ridge = pd.DataFrame()
alpha_candidate = np.hstack([0, np.logspace(-2, 1, 4)])
for alpha_weight in alpha_candidate:
fit = Ridge(alpha=alpha_weight, fit_intercept=True, normalize=True, random_state=123).fit(X, y)
result_coef = pd.DataFrame(np.hstack([fit.intercept_, fit.coef_]), columns=['alpha = {}'.format(alpha_weight)])
result_Ridge = pd.concat([result_Ridge, result_coef], axis=1)
result_LASSO = pd.DataFrame()
alpha_candidate = np.hstack([0, np.logspace(-2, 1, 4)])
for alpha_weight in alpha_candidate:
fit = Lasso(alpha=alpha_weight, fit_intercept=True, normalize=True, random_state=123).fit(X, y)
result_coef = pd.DataFrame(np.hstack([fit.intercept_, fit.coef_]), columns=['alpha = {}'.format(alpha_weight)])
result_LASSO = pd.concat([result_LASSO, result_coef], axis=1)
result_Ridge.plot(figsize=(10,10), legend=True, ax=plt.subplot(211))
plt.title('Ridge')
plt.xlabel('Columns')
plt.ylabel('coefficients')
plt.legend(fontsize=13)
plt.grid()
result_LASSO.plot(legend=True, ax=plt.subplot(212))
plt.title('LASSO')
plt.xlabel('Columns')
plt.ylabel('coefficients')
plt.legend(fontsize=13)
plt.tight_layout()
plt.grid()
plt.show()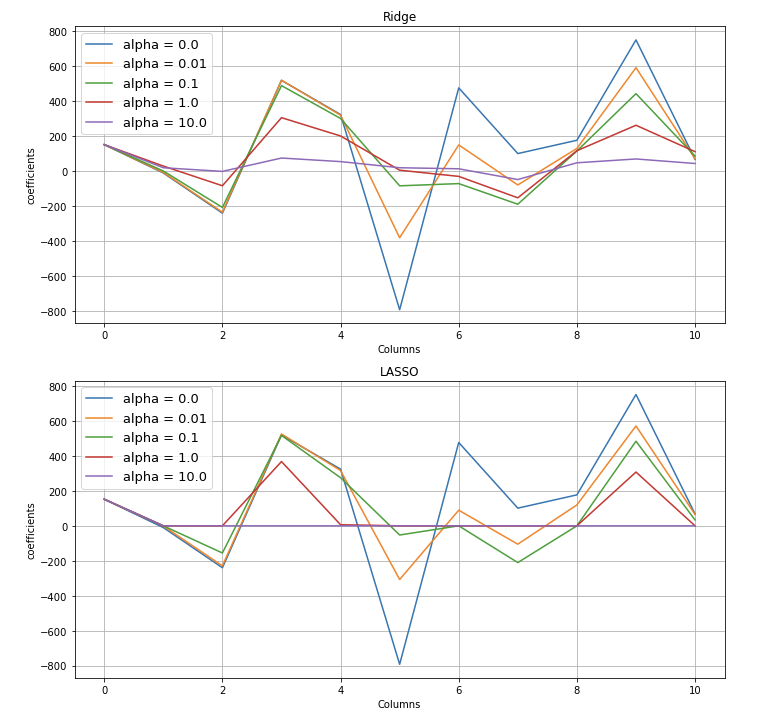
Ridge부터 살펴보면, alpha가 0일 때인 파란색 선이 각 열에 따라서 위 아래로 퍼져있는 것을 확인할 수 있고, alpha가 커지면서, 계수가 정확하게 0이 되지는 않지만, 모두 점점 0에 가까워 지고 있는 것을 확인 할 수 있다.
Lasso의 경우에는 alpha가 가장 클 때인 10, 보라색선을 확인하면 0번 Column을 제외하고는 1 ~ 10번 Column까지 계수가 전부 0인 것을 확인할 수 있다.
이번에는 계수와 alpha와의 관계를 축을 바꿔서 확인해보자.
result_Ridge.T.plot(figsize=(10,10), legend=False, ax=plt.subplot(211))
plt.title('Ridge')
plt.xticks(np.arange(len(result_Ridge.columns)), [i for i in result_Ridge.columns])
plt.ylabel('coefficients')
plt.grid()
result_LASSO.T.plot(legend=False, ax=plt.subplot(212))
plt.title('LASSO')
plt.xticks(np.arange(len(result_Ridge.columns)), [i for i in result_Ridge.columns])
plt.ylabel('coefficients')
plt.tight_layout()
plt.grid()
plt.show()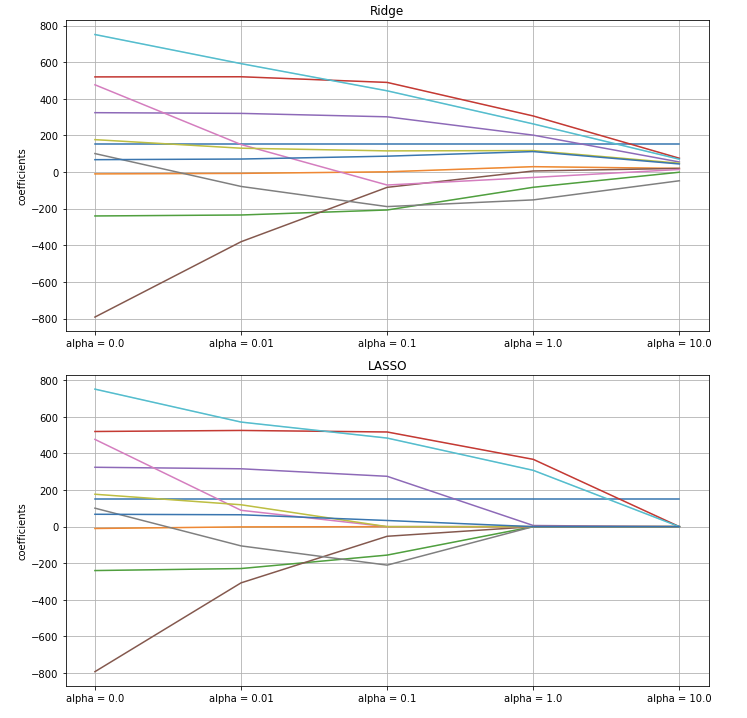
X축이 왼쪽에서 오른쪽으로 진행할수록 alpha가 커지는 것이므로, 왼쪽에서 오른쪽으로 진행할 때, 각 Column(각 선)들이 어떻게 변화하는 지 확인을 해보면, Ridge는 정확하게 0이 되는 것은 거의 없지만, 대부분의 계수가 0으로 수렴하는 형태를 보여주고 있다.
Lasso는 왼쪽에서 오른쪽으로 진행할수록, 정확하게 0이 되는 계수들이 점점 늘어나고 있는 것을 확인할 수 있다.
Reference : 패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
'딥러닝 > 시계열' 카테고리의 다른 글
| [논문 Review] 온라인 게임의 주간 플레이어 인구 패턴 2 (0) | 2021.03.27 |
|---|---|
| [논문 Review] 온라인 게임의 주간 플레이어 인구 패턴 1 (0) | 2021.03.26 |
| 정상성 (0) | 2021.03.22 |
| 조건수를 줄이는 방법 (0) | 2021.03.15 |
| 조건수(Condition Number)에 대한 이해 (0) | 2021.03.14 |

최근댓글