NLP VS 텍스트 분석 :
기본적으로 둘을 구분하는 것이 유의미하지는 않다. 굳이 구분하자면,
- NLP : 머신이 인간의 언어를 이해하고 해석하는 데 더 중점. 텍스트 분석을 향상하게 하는 기반 기술이라고 볼 수도 있다.
ex> 언어를 해석하기 위한 기계번역, 자동으로 질문을 해석하고 답을 하는 질의응답 시스템 - 텍스트 분석( = 텍스트 마이닝) : 비정형 텍스트에서 의미 있는 정보를 추출하는 것에 중점. 모델을 수립하고, 정보를 추출해 비즈니스 인델리전스, 예측 분석 등의 분석 작업을 주로 수행.
- 텍스트 분류
- 감성 분석
- 텍스트 요약
- 텍스트 군집화, 유사도 측정
텍스트는 비정형 데이터이지만, 머신러닝 알고리즘에 넣는 데이터는 숫자형 데이터가 들어가야 한다.
텍스트를 머신러닝에 적용하기 위해서는 '비정형 텍스트 피처를 어떻게 피처 형태로 추출하고 추출된 피처에 의미 있는 값을 부여하는가?'가 중요하다. (피처 벡터화, 피처 추출)
대표적인 방법 : BOW(Bag of Words), Word2Vec
파이썬 기반의 NLP, 텍스트 분석 패키지
- NLTK (Natural Language Toolkit for Python):
파이썬의 가장 대표적인 NLP 패키지. NLP의 거의 모든 영역을 커버. 수행 속도 측면에서는 아쉬운 부분이 있다.
⇒ 대량의 데이터 기반에서는 제대로 활용 X - Gensim : 토픽 모델링 분야에서 가장 두각을 나타내는 패키지
- SpaCy : 뛰어난 수행 성능으로 최근 가장 핫한 NLP 패키지.
머신러닝 기반의 텍스트 분석 프로세스
- 텍스트 사전 준비작업(전처리) :
클렌징, 대소문자 변경, 특수문자 삭제, 단어 토큰화 작업, Stop word 제거 작업, 어근 추출(Stemming, Lemmatization) - 피처 벡터화 , 추출 :
가공된 피처에서 피처를 추출하고 벡터 값을 할당. BOW(count 기반 & TF-IDF 기반 벡터화), Word2Vec - ML 모델 수립 및 학습, 예측, 평가:
ML 모델을 적용해 학습, 예측, 평가
텍스트 전처리 (텍스트 정규화)
- 클렌징 (Cleansing) : 불필요한 문자, 기호 등을 제거하는 작업
(ex > HTML, XML 태그나 특정 기호 삭제) - 토큰화 (Tokenization) :
문서 → 문장 분리 (문장 토큰화) / 문장 → 단어 분리(단어 토큰화) NLTK에서 다양한 API 제공- 문장 토큰화 : 마침표(.), 개행문자(\n)에 따라 분리
nltk.download('punkt') : 마침표, 개행 문자 등의 데이터 셋을 다운로드
각 문장이 가지는 시맨틱적인 의미가 중요한 요소로 사용될 때 사용. - 단어 토큰화 : 기본적으로 공백( ), 콤마(,), 마침표(.), 개행문자(\n)으로 분리
단어의 순서가 중요하지 않은 경우 → 문장 토큰화 X, Only 단어 토큰화 OK
(단어 토큰화 시 문맥적인 의미가 무시되는 문제를 해결하기 위한 방안) - 문장 토큰화 : 마침표(.), 개행문자(\n)에 따라 분리
- 필터링, 스톱워드 제거, 철자 수정 :
Stop Word ⇒ 분석에 큰 의미가 없는 단어를 지칭. (NLTK가 가장 다양한 언어의 스톱 워드를 제공.) - Stemming & Lemmatization : 문법적으로, 의미적으로 변화하는 단어의 원형을 찾는 것.
Stemming은 원형 단어 변환 시 일반적인 방법 or 단순화된 방법을 적용하기 때문에, 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 존재한다.
Lemmatization는 품사와 같은 문법적인 요소와 더 의미적인 부분을 감안하여 더 정확한 철자로 된 어근을 찾아준다.
NLTK에서 제공하는
Stemmer : Porter, Lancaster, Snowball Stemmer Lemmatization : WordNetLemmatizer
lemmatization : WordNetLemmatizer
(이때 정확한 단어 추출을 위해서 단어의 품사를 함께 입력해주어야 한다.)
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('working'), stemmer.stem('works'), stemmer.stem('worked'))
print(stemmer.stem('amusing'), stemmer.stem('amuses'), stemmer.stem('amused'))
print(stemmer.stem('happier'), stemmer.stem('happiest'))
print(stemmer.stem('fancier'), stemmer.stem('fanciest'))

Stemming을 이용하면 첫번째 경우인 work를 제외하고는 제대로 원형을 찾지 못하는 것을 볼 수 있다.
from nltk.stem import WordNetLemmatizer
import nltk
nltk.download('wordnet')
lemma = WordNetLemmatizer()
print(lemma.lemmatize('amusing','v'), lemma.lemmatize('amuses', 'v'), lemma.lemmatize('amused','v'))
print(lemma.lemmatize('happier','a'), lemma.lemmatize('happiest','a'))
print(lemma.lemmatize('fancier','a'), lemma.lemmatize('fanciest','a'))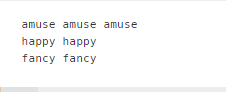
Stemming 과정에서 제대로 어근을 찾지 못한 예시들을 Lemmatization을 수행한 경우, 제대로 찾을 수 있었다.
Bag of Words - BOW
문서가 가지는 모든 단어(Words)를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델.
장점 : 쉽고 빠른 구축 ⇒ 여러 분야에서 활용도가 높다.
단점 :
- 문맥 의미(Semantic Context) 반영 부족 :
n_gram기법을 활용할 수 있지만, 이것 또한 제한적이다. - 희소 행렬 문제 :
문서마다 서로 다른 단어로 구성되어 단어가 문서마다 나타나지 않는 경우가 더 많다. 이로 인해 행렬을 만들면 대부분의 값이 0으로 채워지는 희소행렬이 생성된다. 희소 행렬은 일반적으로 ML 알고리즘의 수행시간과 예측 성능을 떨어뜨려, 희소 행렬을 위한 특별 기법이 마련되어 있다.
BOW 피처 벡터화
각 문서(Document)의 텍스트를 단어로 추출해 피처로 할당. 각 단어의 발생 빈도를 이 피처의 값으로 부여해 각 문서를 이 단어 피처의 발생 빈도 값으로 구성된 벡터로 만드는 기법.
BOW의 피처 벡터화 :
- 카운트 기반의 벡터화
- TF-IDF(Term Frequency - Inverse Document Frequency) 기반의 벡터화
단순히 등장하는 횟수에 따라 중요도를 판단하는 것보다, TF-IDF를 사용하는 방식이 더 좋은 예측 성능을 보장한다.
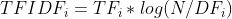
TF_i : 개별 문서에서의 단어 i 빈도
DF_i : 단어 i를 가지고 있는 문서의 개수
N = 전체 문서의 개수
reference : 파이썬 머신러닝 완벽 가이드
'딥러닝 > 자연어처리' 카테고리의 다른 글
| [NLP] Transformer 논문 리뷰 (0) | 2023.01.03 |
|---|---|
| [NLP] seq2seq Learning (0) | 2023.01.03 |
| NLP 논문리뷰 - Distilling the Knowledge in a Neural Network (1) | 2021.05.13 |
| NLP 논문 리뷰 - GPT1 (Improving Language Understanding by Generative Pre-Training) (0) | 2021.04.15 |
| Transformer - Attention is All you need (0) | 2021.04.08 |

최근댓글