sequence to sequnce
seq2seq의 input, output의 길이는 같을 필요는 없다.
encoder : 입력된 정보를 어떻게 처리해서 저장할 것이냐?
- context vector를 생성
- context vector를 decoder로 넘겨줌
decoder : 압축된 정보를 어떻게 풀어서 반환해줄것인가?
- output sequence를 item by item으로 넘겨줌
Encoder-Decoder with RNN
- RNN : input 값을 hidden state와 output값으로 처리해줌. 이 값들을 계속 전달해나가는 구조
- 가장 마지막의 hidden state인 context vector가 decoder로 전달 됨.
- docoder를 통해 다시 sequence가 추출됨(i, am, a, student)
- 특징 : context vector가 뒤쪽의 hidden state에 큰 영향을 받고, 앞쪽 hidden state들의 영향은 미미함
Attention
- long sentences에 대해서 context vector는 bottleneck(병목현상)이 발생할 수 있음.
- model이 각각 input sequence에 대해 중요한 부분을 가중치를 부여하여 attention 구조를 만듦.
2가지 Attention 구조
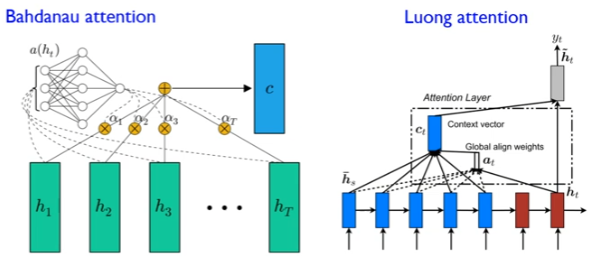
Bah~~ attention : 모델 학습을 통해 attention score를 만드는 구조
Luong attention : 모델 학습을 하지 않고 단순 곱셈 연산으로 attention score를 만드는 구조 (실용적)
attention is seq2seq learning
- encoder가 decoder로 더 많은 정보를 넘겨줌(final hidden state만 넘겨주는 것이 아니기 때문에)
- 모든 hidden state를 decoder로 넘겨줌
- 중요한 단어에 가중치를 부여할 수 있음

Attention 메커니즘 단계
1) input에 해당하는 hidden state 정보를 가져옴. decoder가 만드는 hidden state를 가져옴
2) attention score : decoder hidden state와 encoder hidden state를 내적한 값을 구함.
3) softmax score : decoder가 가져온 정보를 추론함
4) 각각의 벡터들을 concat해서 context vector를 만듦.
전체 메커니즘

attention score를 구한 후 context vector를 구함.
context vector와 hidden state를 concat한 후 ff-net을 거침
'딥러닝 > 자연어처리' 카테고리의 다른 글
| [NLP] Bert 논문 리뷰 (0) | 2023.01.13 |
|---|---|
| [NLP] Transformer 논문 리뷰 (0) | 2023.01.03 |
| 자연어 처리 (0) | 2021.07.12 |
| NLP 논문리뷰 - Distilling the Knowledge in a Neural Network (1) | 2021.05.13 |
| NLP 논문 리뷰 - GPT1 (Improving Language Understanding by Generative Pre-Training) (0) | 2021.04.15 |

최근댓글