BERT : Bidirectional Encoder Representations from Transformer
- transformer에서 encoder 정보만 사용하는데, bidrectional한 정보만 사용하겠다.
1) Masked language model : 순차적으로 model을 사용하는 것이 아닌, 특정 위치에 mask를 씌워서 그 부분을 예측.
2) Next sentence prediction : 다음 sentence가 corpus에서의 contextual하게 다음 등장하는 sentence인지 학습.
Input/Output representations

- down-stram tasks에 따라, single-sentence를 받을수도 pair로 된 sentences를 받을 수도 있다.(Q-A Task)
- Sentence : 연속적인 task의 span(문법적으로 맞는, 완벽한 문장이 아니어도 된다.)
- Sequence : single setence일수도 2개의 sentence가 결합된 형태일수도 있음.
- sentence가 들어갈 때 token단위로 들어가는데, 일정 비율로 token에 mask를 씌워서 input으로 넣음. (unlabeled sentence-> 연속적인 sentence를 집어 넣겠다.)
Token 개념
- [CLS] : sentence의 시작을 알려주는 토큰
- [SEP] : 두 개의 sentence를 구분해주는 토큰
- final hidden vector of [CLS] token : 감성분류나, NSP, 유사도와 같은 binary 분류만 할 때는 이 token만 사용함.
- Tn : n번째 token에서 hidden vector
Bert의 목적
- 0/1 token(final [cls] token)과 Mask LM task를 동시에 학습시키는 게 목적
Input Representation is the sum of

1) Token embedding : wordpiece embeddings with a 30,000 token vocabulary (token들의 위치에 해당하는 embedding vector)
* wordpieces :_J et _makers _fe _ud -> 띄어쓰기로 word를 구분하는 걸 _로 구분. 한 word 내에서 자주 발생하는 것으로 나눈다는 개념(=BPE와 유사). 자주 쓰는 단어 단위.
2) Segment embedding : [SEP] token 기준으로 sentence를 기준으로 나뉘는 embedding. 위 그림에서 EA, EB로 나눠진 이유.
3) Position Embedding : token position에 대한 embedding.
-> 각각의 embedding들이 동일한 차원을 가지고 있으므로 더해서 representations을 구성하게 됨.
Pre-training BERT Task1 : Masked Language Model(MLM)

- 전체 sequence의 15%만 [mask] token을 씌움.
- output 윗 단에 FC layer + GELU + Norm -> w'4이 w4(실제 token)이 되도록 학습을 시켜주는 것이 MLM.
- ELMo는 양방향으로 각각 학습해서 token을 선형결합하는 방식 사용. vs Bert는 순차적이 아닌 mask를 씌워서 model이 학습을 통해 가려진 단어를 예측하도록 함.
- pre-trained단계에서만 일어나고 fine-tuning단계에서는 일어나지 않음. [MASK] token에 대한 mismatch가 발생할 수 있음.

-> mismatch 해소 solution : i번째 token이 mask가 씌워진다고 하면, 그 중 80%만 실제로 masking을 하고, 10%는 random token으로 치환, 10%는 masking을 하지 않고 original token을 그대로 사용. (왜?)
Task2 : Next Sentence Prediction (NSP)
- QA이나 NLI는 2개 이상의 문장들에 대한 관계를 이해해야 풀어낼 수 있음. 문장 단위의 Language model은 이 관계를 이해할 수 없음. ELMo와 GPT는 문장 단위로 학습했기에, 2개 이상의 문장을 함께 학습하진 않음.

- 50%는 A -> B가 이어지는 문장에서 뽑아와서 label 1로 주고, 50%는 실제로 다음 문장이 아닌 것에서 뽑아와서 label 0으로 줌. 그 이후 sequence를 구성해서 [token]을 통해 next sentence인지 아닌지 판별.
Datasets for pre-training
- BookCorpus(800M words), https://github.com/soskek/bookcorpus
- English Wikipedia(2,500M words), https://github.com/attardi/wikiextractor
Hyper-paramter settings
- maximum token length : 512 (90%의 step은 128개로 사용)
- batch size : 256
- l2 weight decay
- 모든 layer에 대해 dropout 0.1
- ReLU -> GeLU
Fine-tuning BERT

- BERT 바로 윗 단에 layer하나만 쌓아도 각 task에 맞게 적용 가능.
MNLI 등 : sentence pair를 classification. sentence 2개가 유사한지 아닌지 class label로 분류
binary classfication 등 : 단일 sentence를 분류하는 task
QA 등 : Question와 paragraph를 입력으로 주고 question에 해당하는 answer를 output으로 출력
NER 등 : 단일 sentence의 각 token에 대해 output을 출력하는(ex-각각의 형태소를 출력하는)
Experiment 1 : effect of Pre-training Tasks
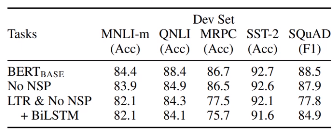
- NSP를 사용하지 않을 때보다 NSP을 사용했을 때, 2개의 문장을 사용하는 Task에서 큰 성능 향상이 일어남.
Experiment 2 : Effect of Model size
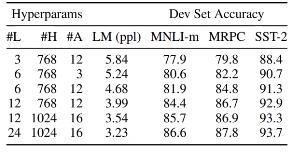
- Hyperparamter가 많아질수록. 복잡해질수록 성능 향상이 일어남.
Experiment 3 : Feature-based Approach with BERT
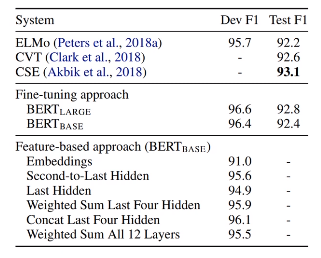
- fine tuning하지 않고 마지막 4개의 hidden layer를 결합 혹은 연산했을 때, fine tuning했을 때와 비슷한 성능을 가짐.
'딥러닝 > 자연어처리' 카테고리의 다른 글
| [NLP] GPT-2 논문리뷰 (0) | 2023.01.16 |
|---|---|
| [NLP] GPT 논문 리뷰 (0) | 2023.01.13 |
| [NLP] Transformer 논문 리뷰 (0) | 2023.01.03 |
| [NLP] seq2seq Learning (0) | 2023.01.03 |
| 자연어 처리 (0) | 2021.07.12 |

최근댓글