GPT: Generative Pre-Training of a Language Model

- unlabeled dataset이 labeled dataset보다 훨씬 많기에 이를 잘 활용하면 지도학습 task에 좋은 성능을 낼 수 있다.
- unlabeled text를 사전에 미리 활용하고, 그 뒤에 labeled text를 활용하자.
- unlabel 단어로부터 word-level 이상의 정보를 활용하는 것은 매우 chellenge(1- 목적 함수가 효과적인지 모르기에, 2-transfer learning을 하기 위한 효과적인 방법의 수렴이 없다.)
ELMo vs GPT

- ELMo는 forward와 backward의 양방향 학습을 거치고 output을 선형결합하여 사용
- GPT는 Backward를 쓰지 않고 forward에 대해서도 masking한 것을 사용(Transformer의 decoding block쪽만 사용)
-> GPT Unsupervised pre-training의 목적

Θ : parameter
P : conditional probability modeled using parameter
k : size of context window
ui-1, ui-2, ... ui-k -> ui를 최대화하는 것이 목적함수.
* log likelihood : 확률(밀도) 값이 likelihood, 즉 모델이 데이터를 얼마나 잘 설명하는지 수치화 하는 척도. 하지만 확률들은 곱하면 underflow 현상이 일어날 수 있어 이를 방지하기 위해 log를 취해 곱을 합으로 변경.
GPT의 idea (구조)

- transformer의 decoder block만 올려 쌓는 구조. encoder나 encoder-decoder attention 사용 안 함.

- token embedding matrix와 the context vector of tokens를 곱한 후 position embedding matrix를 더함.
- h(l-1)의 transformer_block을 거치고 hl을 output으로. 전 단계의 hidden state를 block을 거치면서 갱신
- 마지막으로 n번째의 hidden state와 token embedding matrix를 transpose한 것을 곱함으로써, 그 다음 토큰이 무엇인지 예측
GPT의 Decoder block

- 정보가 주어졌을 때, 해당하는 이전 토큰들만 사용 (모든 token을 사용하는 self-attention이 아닌, 해당 토큰 뒤 토큰들은 masking을 씌워서 활용하지 못 하도록 함)
- encoder-decoder self-attention은 사용하지 않음.
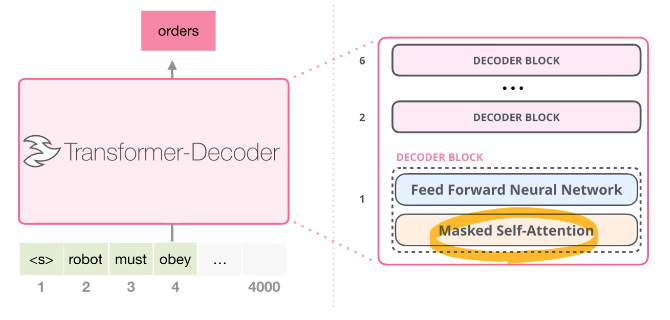
- masked self-attention -> feed forward neural network의 구조. block을 몇 개 쌓느냐는 하이퍼 파라미터.
Supervised fine-tuning
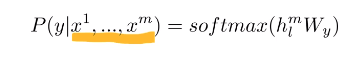
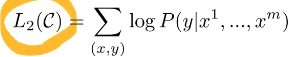
- y라는 label이 주어진 토큰들의 sequence(x1, x2, ... xn)가 주어진다면
- final transformer block의 activation hl*m을 구함 -> linear output layer에 넣어 예측을 하도록 함.
- 이 확률을 최대화하는 것이 목적함수(주어져있는 sequence에 따라 정답 label이 무엇인지 확률값을 최대화)
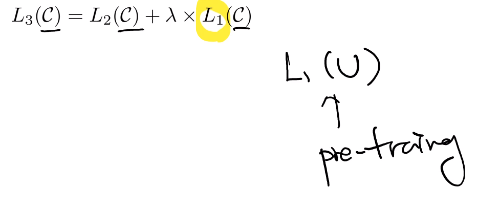
- L1(U) : unsupervised learning corpus에 대해 pre-training
- C : supervised learning의 corpus
- supervised learning의 목적함수(L2) + 우리가 보유하고 있는 LM 용 supervised learning을 함께 update 하게 되면
-> (1) supervised model에 대한 일반화가 향상, (2) 학습속도가 빨라짐.
정리 : unsupervised learning용 L1 model을 학습하고, task specific한(labeled) data가 주어지면 해당하는 model에 대한 Language model(L1) fine-tuning과 supervised-learning에 해당하는 목적함수를 함께 학습하면 더 좋은 성능이 일어남.
Task-specific input transformations
- GPT의 input은 task에 따라 특정 구조를 가지고 있음.

- Classification : text를 transformer를 거쳐 나온 output을 선형결합
- Entailment : Premise [Delim] Hypothesis -> transformer(output 1개) -> linear
- Similarity : 문장 2개를 순서를 바꿔서, 각각 transformer를 거쳐 output을 concat 후 linear
- Multiple choice : context와 answer에 대한 조합들을 n개의 transformer를 거쳐 linear 후, 결과를 softmax.
Experiments
- pre-training dataset : BookCorpus
- '' dataset2 : 1 Billion Word Language Model Benchmark

- Supervised learning에 대한 datasets
- 대부분의 task, datasets의 성능을 개선함.

- dataset이 크면 supervised corpus에 해당하는 Language model 목적함수를 사용하는 것이 도움이 됨.
- dataset이 작으면 language model을 사용하지 않는 게, task specific한 L.M을 fine-tuning하지 않는 것이 유리
'딥러닝 > 자연어처리' 카테고리의 다른 글
| [Transformer 모델 구조 분석] Attention Is All You Need (0) | 2023.02.20 |
|---|---|
| [NLP] GPT-2 논문리뷰 (0) | 2023.01.16 |
| [NLP] Bert 논문 리뷰 (0) | 2023.01.13 |
| [NLP] Transformer 논문 리뷰 (0) | 2023.01.03 |
| [NLP] seq2seq Learning (0) | 2023.01.03 |

최근댓글