해당 논문은 Transfer-Learning을 이용하여 Chest X-ray와 CT 데이터를 분석하여 COVID-19를 진단하는 모델에 대한 연구이다.
Transfer Learning
현재, 여러 딥러닝과 머신러닝 모델들이 좋은 예측 성능을 보이고 있다. 하지만, 좋은 성능을 보이기 위해서는 질 좋고, 다량의 데이터와 긴 학습시간이 소요가 된다. 이는 머신러닝과 딥러닝을 적용하는 것에 있어서 가장 큰 걸림돌이 되고 있다.
전이 학습의 주요 내용은 머신러닝 / 딥러닝에서도 사람이 학습하듯이 '다른 데이터나 task에서 학습한 내용을 현재 하고자 하는 task에 적용할 수 있는 능력'을 가지도록 할 수 있다는 것이다.
전이학습의 과정
데이터가 많은 분야의 데이터를 모델이 사전 학습(pre-train)을 진행한다. 그 이후, 사전 학습된 모델(pretrained model)의 특정 부분과 그 부분의 가중치를 고정한 채로 추출한다. 그리고 나서 실제 모델을 적용하려는 분야의 데이터를 통해 학습을 진행하고 이 과정에서 학습되지 않은 모델의 나머지 부분들의 가중치들이 계산이 된다. Pre-trained Model에서 가져오는 층의 개수, 하이퍼 파라미터 등을 설정하여 전이학습을 최적화 할 수 있다
예를 들면, 이 논문에서는

ImageNet이라는 데이터 셋을 통해서 사전 훈련된 여러 CNN기반의 모델(DenseNet121, InceptionResNetV2, ResNet50, VGG16)을 가져와 Fully-Connected Layer를 제외한 Convolution Layer들을 가져온다. 이후 Fully-Connected Layer의 부분을 다른 8가지의 Classifier를 가져와 COVID-19를 진단하는 Transefer-learning based framework를 제안한다.
여기에서 보면 Convolution Layer에서는 각 이미지들의 특징을 추출하는 단계라고 볼 수 있으며, 이렇게 추출되어진 특징들을 이용하여 분류기에 넣어 분류기들이 최종적으로 COVID를 진단한다고 보면 된다.
전이학습이 적용되는 분야
- 의료 영상 분야
- 자율 주행 자동차
- 로봇
- 자연어 처리
특히, 의료 영상 분야에서는 가용할 수 있는 데이터가 제한적인 의료 영상에서 다른 이미지를 통해 학습한 모델을 사용하여 적은 의료 영상 데이터만을 가지고 좋은 예측 성능을 낼 수 있는 모델을 단기간에 제작할 수 있다. 또한, 자율 주행에서도 인터넷 영상들이나, 영화의 장면들을 학습하여, 자율 주행 자동차에 무단횡단이나, 역주행 등 돌발상황에 대한 학습을 수행할 수 있다.
자연어 처리를 제외하고는 모두 영상들과 관련된 분야에서 전이학습이 많이 이루어지고 있는 것을 볼 수 있다.
사전학습(Pre-training)
이미지와 관련된 Task에서 전이학습이 많이 적용이 되며, 이 경우에는 ImageNet Data set이 Pre-trianing에서 많이 사용이 된다.
ImageNet Dataset은 약 140만장의 이미지 샘플들을 가지고 있으며, 1000개의 Label을 가진 이미지 데이터 셋이다. Label은 강아지, 고양이 등의 동물부터 해서, ski, minibus 등 다양한 Label을 가지고 있다.
최근에는 iNat2021이라는 이미지 데이터 셋도 사전 학습에서 데이터 셋으로 사용되기도 한다. ImageNet과 비교를 하자면, 더 세부적으로 나뉘어진 Label을 가지고 있다.
(A Systematic Benchmarking Analysis of Transfer Learning for Medical Image Analysis : 의료 영상 분야에서 ImageNet을 사전학습한 모델들과 iNat2021를 통해서 사전학습한 모델의 성능을 비교하는 내용이 포함되어 있다.)
데이터 셋(Data Sets)
두가지 종류의 데이터 셋을 이 논문에서는 사용한다.
- Chest X-Ray :
COVID-19와 관련된 25가지의 이미지와 non-COVID인 75개의 이미지로 이루어져 있다. 특히 non-COVID에서는 정상인의 Chest X-Ray만을 가지지 않고, 다른 폐 질환을 가진 사람의 Chest X-Ray 데이터를 포함을 하여, 모델이 단순히 폐 질환을 가진 사람을 COVID라고 진단하지 않고, 정확하게 COVID와 관련된 사람들만 COVID로 진단할 수 있도록 만들어주었다. - CT :
Chest X-Ray 보다 더 많은 데이터 샘플을 가지고 있다. 349개의 Covid image를 가지고, 397개의 non-Covid image를 가진다.
모델의 구조
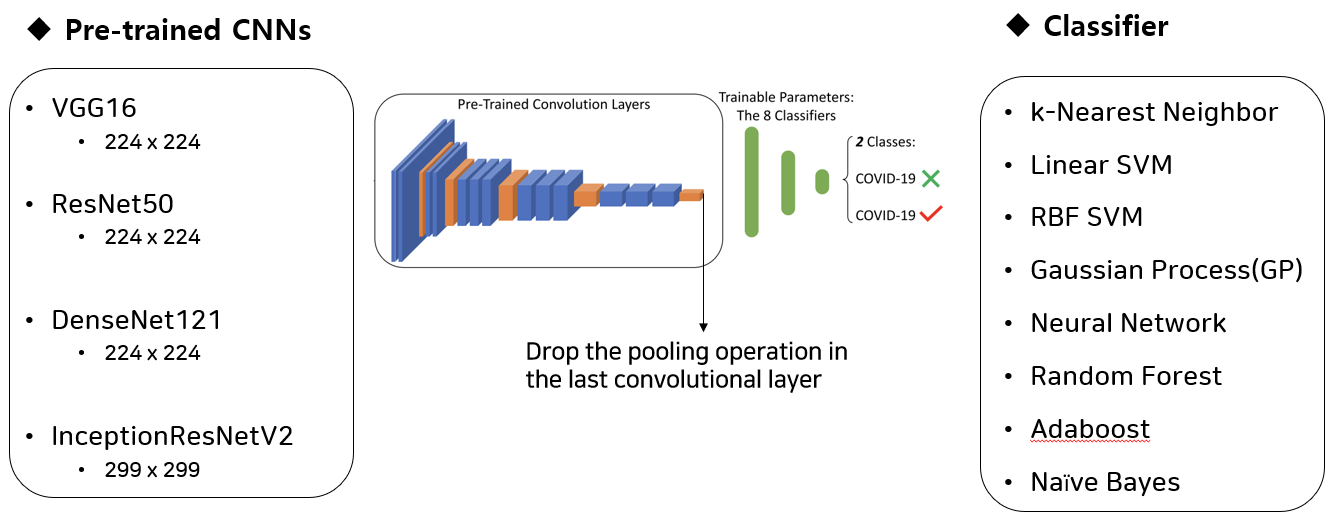
모델의 구조는 크게 Pre-trained와 Classifier 2 부분으로 나눌 수 있다. Pre-trained Model은 전부 Convolutional Neural Network 기반의 모델을 사용한다.
Pre-trained CNNs으로 사용한 모델들로는
- VGG16
- ResNet50
- DenseNet121
- InceptionResNetV2
Classifier로 사용한 모델들로는
- k-Nearest Neighbor
- Linear SVM
- RBF SVM
- Gaussian Process(GP)
- Neural Network(NN)
- Random Forest
- Adaboost
- Naive Bayes
를 사용하였다.
Experiments
위 논문에서는
- 여러가지 Metric(성능 지표)를 이용하여 각 Case(4 x 8 = 32)마다의 성능을 측정
- Network Size & Number of Features를 통해서 여러 Case를 비교
- Data가 input으로 들어왔을 때, 예측에 대한 Uncertainty(불확실성)을 측정
이렇게 3가지 종류의 실험을 하게 된다.
첫번째 실험
Accuracy(정확도), Sensitivity(민감도), Specificity(특이도), AUC Score(ROC 곡선 하단 영역의 넓이)를 성능 지표(Metric)으로 측정하였다. 통계적인 유의성을 보장하기 위해서 각 경우마다 100번씩 훈련과 훈련된 모델의 성능을 측정하는 과정을 거쳤다.
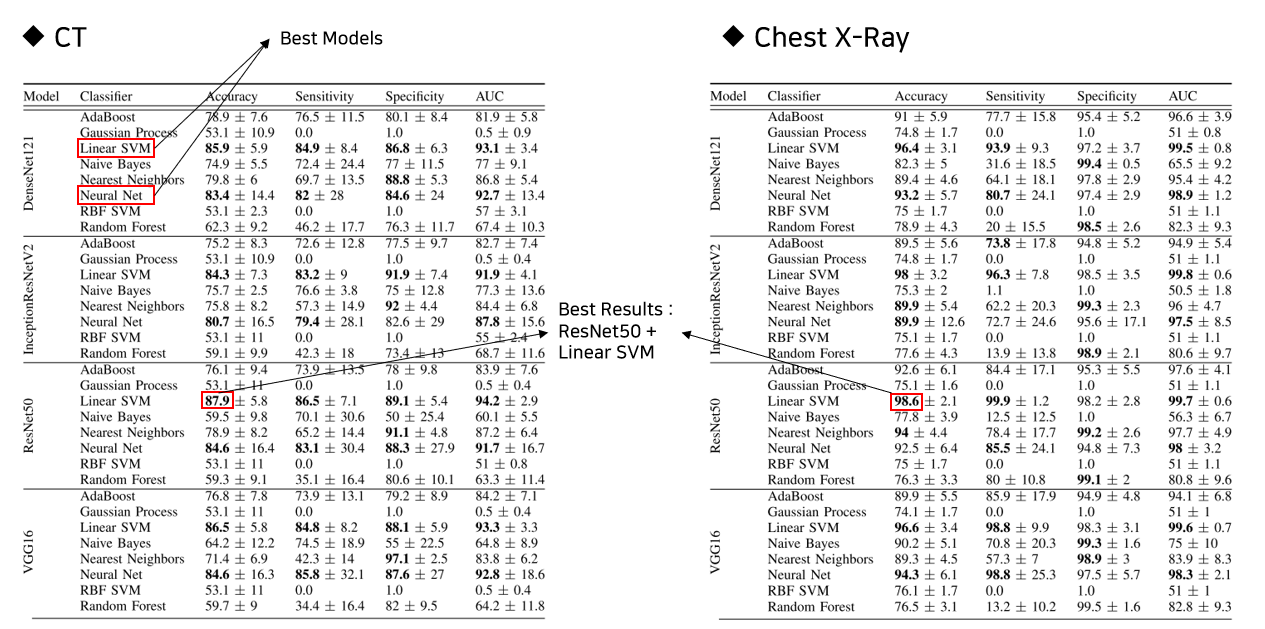
성능을 측정한 결과로는 Pre-trained Model들의 영향은 크게 받지 않았고, Accuracy의 경우, Linear SVM과 Neural Network(NN)의 분류기를 사용했을 때, 전반적으로 좋은 성능을 보이는 것을 확인할 수 있었다. 특히, ResNet50을 Pre-trained CNN으로 사용한 경우가 가장 정확도가 높았다.
(위의 표는 백분율(Percent)로 표현이 되었음에도 불구하고, 100이 넘는 값을 가진다. 이는 평균과 표준편차를 나타낸 표현으로, 데이터가 100%에 가까운 곳에 몰려있고, 그 밑으로도 넓은 영역에 걸쳐 분포한 경우에, 이런 수치가 나올 수 있다. 밑의 이미지를 보면 Sensivity에 해당하는 분포가 방금 언급한 부분이다. )
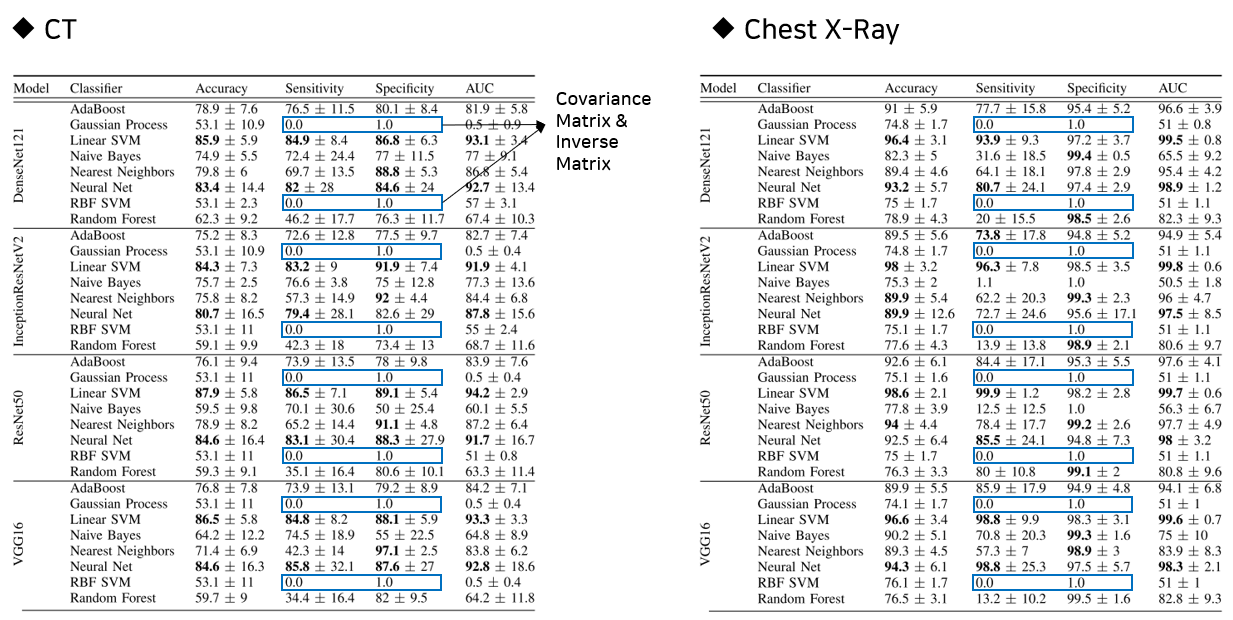
한가지 특징적인 점을 얘기해보면, Gaussian Process와 RBF SVM에서 Sensitivity와 Specificity의 값이 전부 0.0과 1.0으로 통일이 되어있는 것을 확인할 수 있다. 이는 두 모델이 공분산 행렬(Covariance Matrix)과 그 역행렬(Inverse Matrix)을 사용함으로 인해 나오게 된다. 위의 특징으로 인해 Classifier가 사용하는 Feature의 수가 많아질 수록 Sensitivity가 낮아지는 현상이 발생하여 너무 많은 Feature를 사용한 나머지 Sensitivity가 0이 되는 것을 볼 수 있다.
ROC-AUC Score
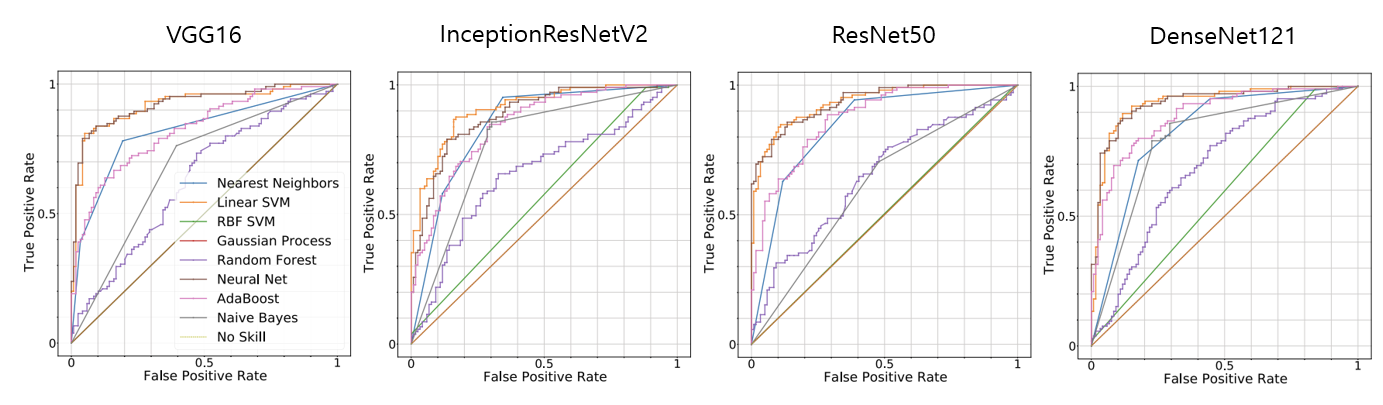
각 그래프는 Pre-trained CNN에 따른 Classifier마다의 AUC score를 나타내고 있다. 여기에서 알 수 있었던 점은 Linear SVM과 Neural Network가 가장 좋은 성능을 보이고 있다는 점과, 나머지 Classifier의 경우, Pre-trained CNN의 종류에 따라서 성능의 순위가 달라지는 것을 확인할 수 있었다.
두번째 실험

두번째 실험은 첫번째 실험에서 가장 좋은 성능을 보인 두 Classifier(Linear SVM, Neural Network)에 대해서만 실험을 진행하였다. X축에 표시되어 있는 Total Parameters는 Pre-trained CNN과 Classifier에서 사용하는 파라미터의 개수를 의미하며, Y축에 표시되어 있는 Number of Features는 Pre-trained CNN들로부터 마지막에 추출된 Feature의 개수를 의미한다.
여기에서는 주로 Accuracy와 AUC의 성능이 어떤지에 주목을 하기보다는, 이들의 성능이 각 조건마다 유사한 것에 주목하였다. 이를 거꾸로 생각을 하면 성능은 비슷하지만, 훈련과정에서 더 많은 파라미터를 학습해야 되고, 더 많은 Feature를 추출해야 하는 모델은 비효율적이라는 것이다. 4
따라서, VGG16이 적은 파라미터를 사용하면서, 가장 적은 Feature를 추출함에도 불구하고 가장 효율적으로 학습 및 예측을 진행하였고, 반대로, InceptionResNetV2는 가장 많은 파라미터를 학습해야 하며, 많은 Feature를 추출함에도 성능이 다른 모델들과 비슷한 것을 보아 가장 비효율적인 모델이라는 결론을 내었다.
세번째 실험
모델의 예측에 대한 불확실성을 측정하는 실험으로, 모델들이 각 예측을 진행함에 있어서 얼만큼의 확신을 가지고 예측을 진행하는지를 정량적으로 나타내는 실험이다.
불확실성에 대한 종류로는
- Aleatoric Uncertainty : 데이터를 수집하는 과정에서 발생하는 불확실성으로, 이는 줄이기가 굉장히 어렵다.
- Epistemic Uncertainty : 모델이 데이터를 모르기 때문에 발생하는 불확실성으로, 더 많은 데이터를 수집하여 학습을 진행한다면 줄이는 것이 가능하다.
이런 불확실성의 특성으로 인해서 논문에서는 Epistemic Uncertainty를 줄이는 것을 목표로 한다.
불확실성을 측정하기 위해서 앙상블 모델을 생성한다. 이 앙상블 모델은 20개의 개별적인 Neural Network를 가진 모델들로 구성된다. 개별적인 Neural Network는 하나의 은닉층을 가지고 있으며, 은닉층이 포함하고 있는 Node의 수는 50 ~ 400의 수 중 랜덤으로 골라 해당하는 수 만큼의 노드를 은닉층이 포함하게 된다.
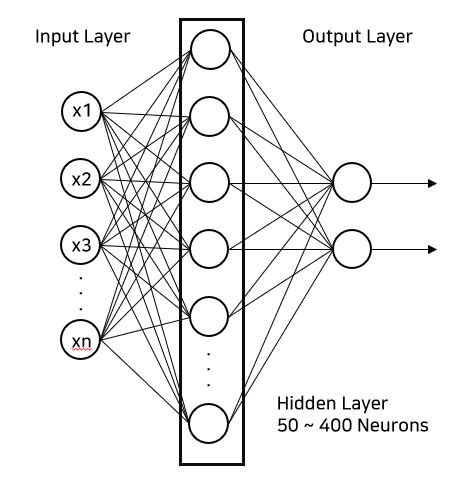
불확실성을 계산하는 방법으로는
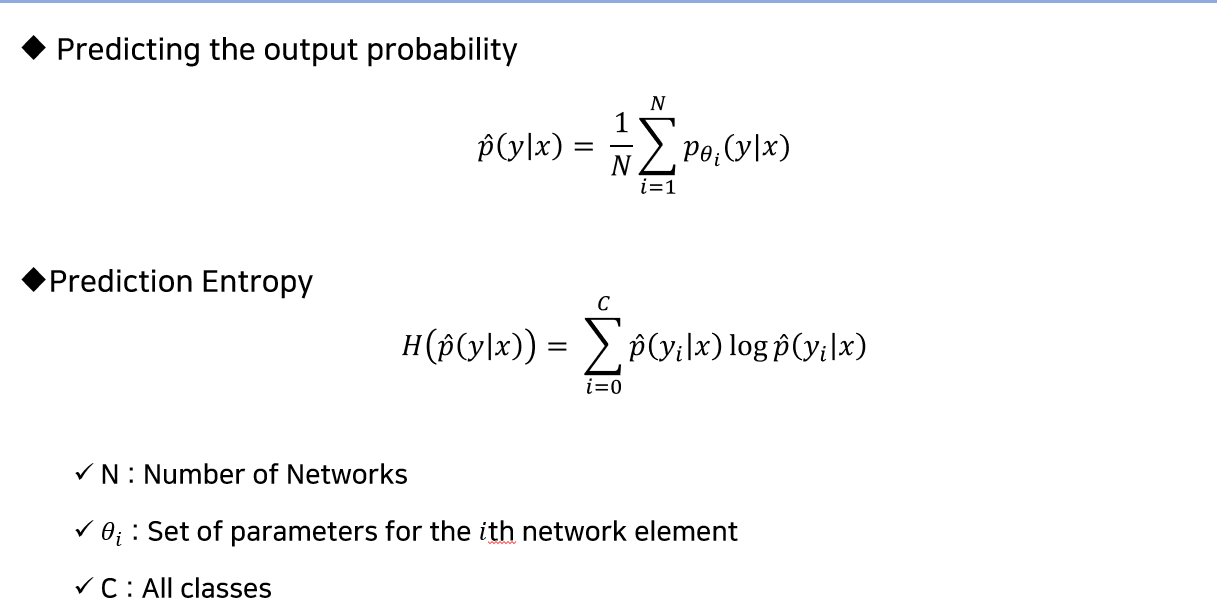
위의 이미지 처럼, 20개의 모델이 COVID로 예측한 것과 non-COVID로 예측한 것들의 수를 세어 각 Label을 확률 값으로 변환하고, 이를 엔트로피 계산식에 대입하여 불확실성을 측정하게 된다.
Chest X-Ray
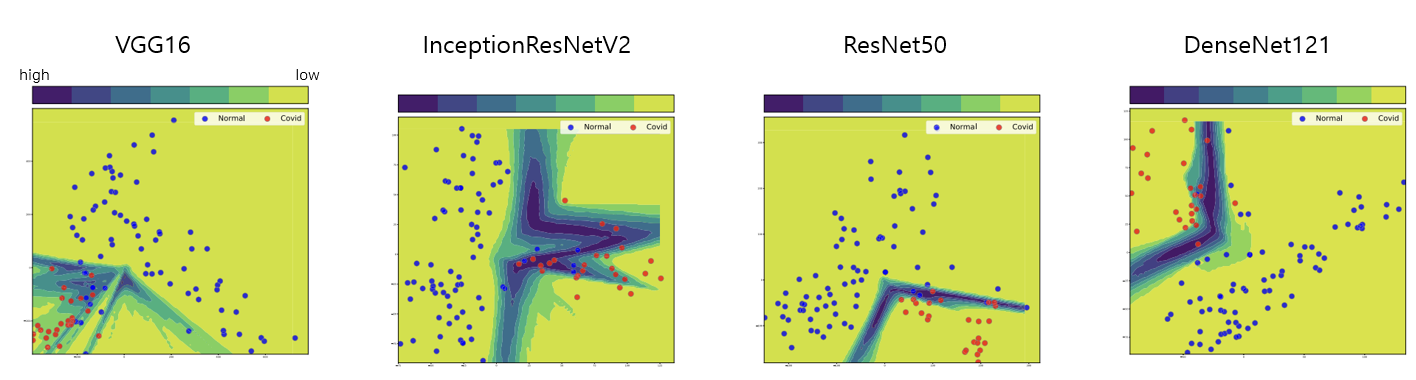
CT
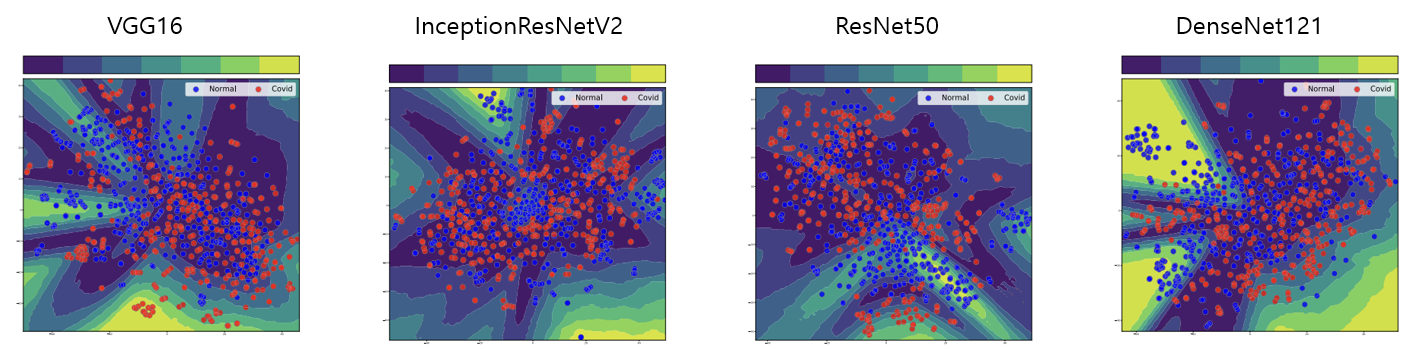
위의 그래프들은 각 데이터를 Pre-trained CNN을 통해서 추출한 Feature들을 PCA를 통해서 2가지의 Vector로 표현한 이후에, 2D에 Mapping하는 과정을 거치고, 각 Sample마다 불확실성을 측정하여, 연두색의 밝은 색을 나타내는 영역은 불확실성의 값이 낮은 부분, 남색에 해당하는 영역은 불확실성의 값이 높은 부분을 의미한다.
결과를 보면, 확실히 Chest X-Ray에서가 불확실성이 전반적으로 낮은 것으로 보이며, CT에서는 불확실성이 꽤 높은 것으로 나타난다.
결론
이 논문이 Transfer Learning(전이 학습)을 통해서 COVID-19 진단에 대한 연구를 진행하게 된 동기는 의료 영상 데이터를 확보하는 데에 있어서 많은 제약이 따른다는 것에서부터 출발하였으며, 결과적으로 Linear SVM과 Neural Network 분류기가 제안된 8가지 분류기들 중에서 가장 좋은 성능을 보였음을 알 수 있었다.
이후 연구에서는 Pre-trained CNN에서 추출된 Feature를 결합하는 Hybrid Model을 제작하거나, Classifier의 예측을 결합하는 Ensemble Model 제작 등을 통해서 예측의 성능을 더 높일 수 있을 것이라고 기대하고 있다.
'소개 및 연구분야 > 한주혁 - NeuroScience' 카테고리의 다른 글
| Pycaret - Feature Importance 뽑기 (0) | 2022.07.24 |
|---|---|
| Pycaret - 소개, 학습 방법, 파라미터 튜닝 (1) | 2022.07.17 |

최근댓글