Pycaret
Pycaret은 Machine Learning Workflow를 자동화하는 오픈소스 라이브러리이다.
Classification, Regression, Clustering 등의 Task에서 사용하는 여러 모델들을 동일한 환경에서 한번에 한 줄의 코드로 실행할 수 있도록 자동화한 라이브러리이다. 여러 모델을 비교할 수 있으며, 각 모델 별로 튜닝을 진행할 수도 있다.
(2022.07.17 현재, 가장 최근 Release는 Pycaret 2.3.10)
현재 연구 중인 분야가 Regression Task이기 때문에, Regression을 기준으로 설명한다.
여기에서는 내가 연구를 진행하면서 사용한 주요 메서드와 그 안에 입력한 파라미터들을 위주로 정리를 했으며, 추가적인 내용을 원하거나, 더욱 구체적으로 알고 싶은 경우에는 Pycaret 홈페이지(https://pycaret.readthedocs.io/en/latest/index.html)에서 찾아볼 수 있다.
Installation
# create a conda environment
conda create --name yourenvname python=3.8
# activate conda environment
conda activate yourenvname
# install pycaret
pip install pycaret
# create notebook kernel connected with the conda environment
python -m ipykernel install --user --name yourenvname --display-name "display-name"일반적으로는 다음과 같이 아나콘다 환경에서 설치를 할 수 있다.
Full Version
# install the full version of pycaret
pip install pycaret[full]Full Version은 꼭 필요한 패키지만을 설치하는 일반 버전과는 달리 부가적인 패키지들도 설치한다는데, 정확하게 어떤 차이가 있는지는 파악하지 못했다. 현재 나는 Full Version을 설치해서 진행했다. (일반 버전도 크게 다른 것 같지는 않다.)
Import
from pycaret.regression import *
Models
Pycaret에서는 25가지 Regressior를 제공을 해준다. 이후에 models()라는 메서드를 통해서 알 수 있다. 25가지의 모델들 중 세부적인 그룹으로 나눌 수 있는데, Linear Regressor, Tree Regressor, Ensemble Regressor가 있고, 세가지 그룹 모두에 해당하지 않는 모델들도 존재한다. 추가적으로 사용자가 Custom하게 선언해 준 모델들도 사용할 수 있다. (하지만, Tuning을 자동적으로 해주는 tune_models( ) 메서드에서는 튜닝이 적용되지 않는 모델들이 존재할 수도 있다.)
주요 함수들
setup( )
Train data, Test data, label column 등을 설정하는 부분이며, Normalization, Transformation, Fold Strategy 등 여러 전처리 기법들을 적용할 수 있다.
ixi_model = setup(session_id = 1, data = ixi_train, target = 'age', test_data = ixi_test, normalize = True, normalize_method = 'zscore',transformation=True, fold_strategy='stratifiedkfold', use_gpu = True)<파라미터>
- data : Input data를 입력해야 하며, Train, Test를 별도로 분리하지 않고 입력하면 뒤의 train_size에 입력한 비율대로 Train과 Test를 분리한다. Train과 Test를 별도로 입력하기 위해서는 여기에 Train data를 입력하고, test_data에 Test data에 해당하는 데이터를 입력해주면 된다.
- Target : 어떤 Column이 최종적으로 예측해야 하는 Column인지를 설정해주는 파라미터이다. Train data에 해당 Column이 존재해야 한다.
- session_id : Random seed를 설정해주는 부분이다. 즉, 난수 생성에 특정한 seed 값을 적용하여, Random하게 일을 처리하지만, 이후에 반복 실행을 했을 때에도, 동일한 결과가 나올 수 있도록 한다.
- normalize : 데이터에 정규화(Normalization)을 할 것인지를 True/False로 선택한다.
- normalize_method : Normalization=True인 경우에, 어떤 방식으로 Normalization을 진행할 것인지를 설정해주는 파라미터이다.
('zscore', 'minmax','maxabs','robust') - transformation : Power Transformation을 통해서 데이터 샘플들의 분포가 가우시안 분포(정규 분포)에 더 가까워지도록 처리해주는 과정이다.
- fold_strategy : Pycaret은 기본적으로 10-fold Cross-Validation을 수행하는데, 이를 다른 Fold Strategy(ex> stratified K-fold 등)으로 설정할 수 있는 하이퍼파라미터이다. (Regression인 경우에는 Label 값이 Int인 경우에는 Stratified K-fold가 제대로 실행되지만, 소수점이 있는 Float 형태인 경우에는 Stratified K-fold를 설정해주었을 때 학습이 수행되지 않으므로, 이 부분을 고려해야 한다. 나 같은 경우에는 Float 형태로 되어 있는 Label 값을 Int 형태로 변환하여 소수점 아래 자리를 버렸다. )
- use_gpu : GPU를 사용할 것인지를 설정해줄 수 있다.

코드를 실행하였을 때, 위의 이미지 처럼 각 Feature들이 Numeric인지 Categorical인지를 확인하고 오류가 없다면 Enter를 입력하면 된다.
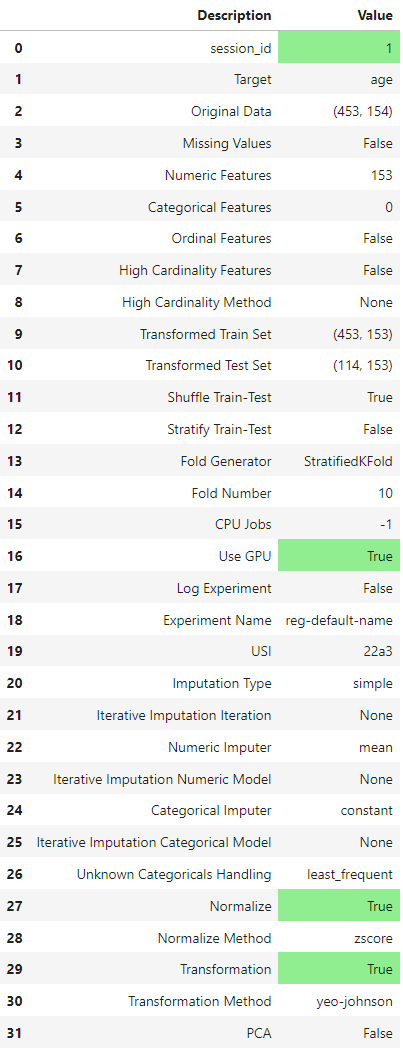
Enter를 입력하면 데이터에 대한 간단한 설명과, 선택한 옵션들이 초록색으로 강조되어 표시되는 것을 확인할 수 있다.
models( )
setup( ) 함수를 실행한 이후에는 models( )라는 메서드를 통해서 어떤 모델들을 사용할 수 있는지를 볼 수 있다.
(setup( ) 함수를 실행하지 않고는 이 메서드를 호출할 수 없다.)
models()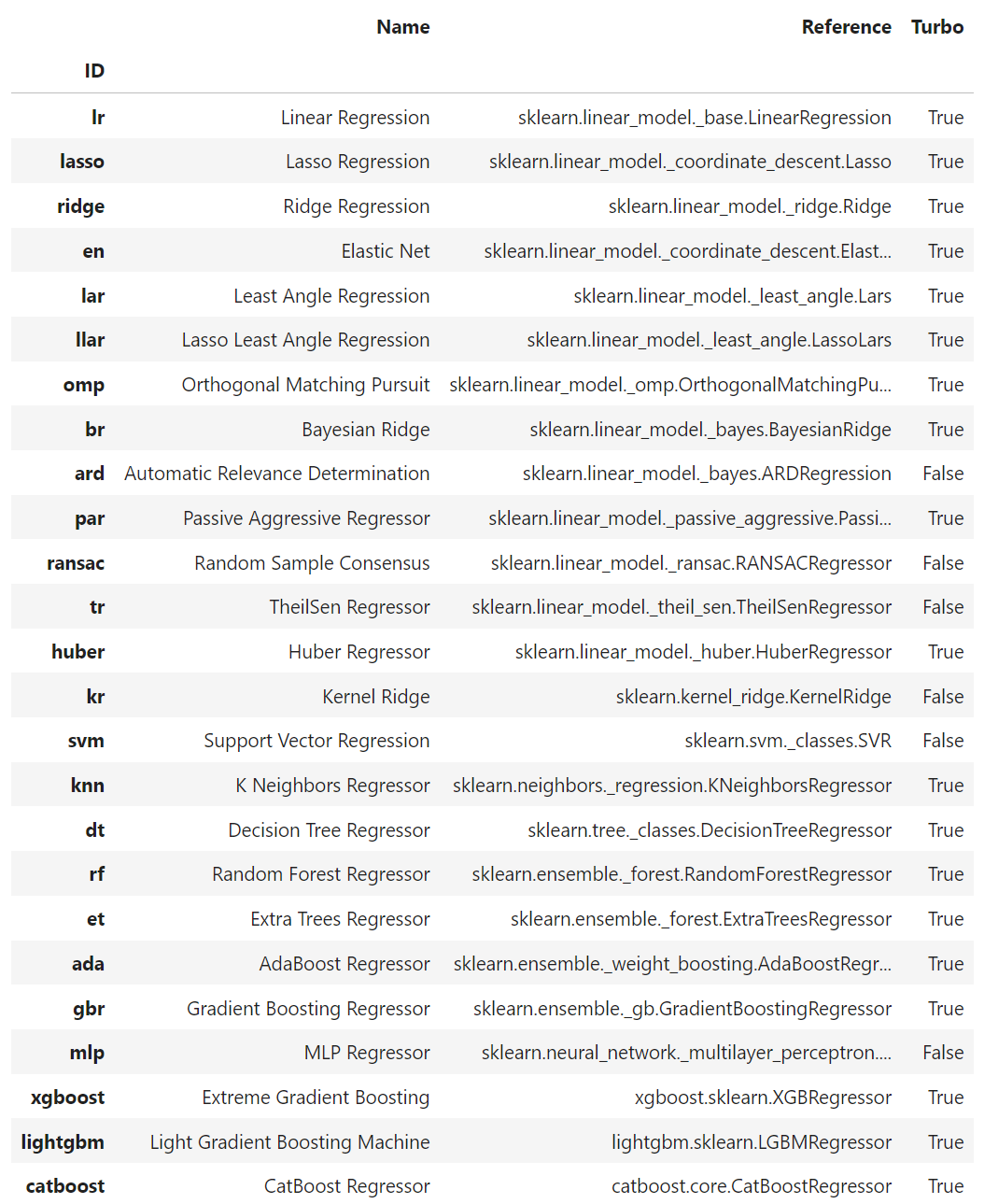
Regression Task 에서는 25가지 모델을 기본적으로 제공해주고, 각 모델들의 출처가 어디인지, Turbo 여부를 알려준다. (Turbo는 True로 하는 경우에, 학습 시간이 너무 오래걸리면, 생략하고 다음으로 넘어가는 것을 의미한다.)
compare_models( )
models() 에서 제공하는 모델들이나, scikit-learn에서 제공하는 모델을 별도로 선언한 이후에, 입력한 모델들의 성능(MAE, MSE, RMSE, R2, Train Time 등)을 DataFrame의 형태로 제공해준다.
pycaret_regression_models = compare_models(n_select=25, sort='MAE', include = ['lr','lasso','ridge','en','lar','llar','omp','br','ard','par','ransac','tr',
'huber','kr','svm','knn','dt','rf','et','ada','gbr','mlp','xgboost','lightgbm','catboost'])- n_select : compare_models( ) 함수는 학습을 수행한 모델을 최종적으로 반환(return)해주는데, 이 때 n_select에서 설정해준 수만큼의 모델을 가장 좋은 성능을 보였던 모델의 순서대로 저장한다.
- sort : Metric의 이름을 String 형태로 입력을 해주며, 최종적으로 반환해주는 DataFrame에서 모델들을 Sorting 할 때 어떤 Metric을 기준으로 Sorting을 진행할지 결정해주는 파라미터이다.
- include : 어떤 모델들을 비교할지 설정해주는 함수로, 여러 모델들을 리스트의 형식으로 입력을 해준다. models( ) 에서 볼 수 있던, ID를 입력하거나, 별도로 이전에 선언한 모델을 리스트안에 넣어주게 되면, 자동적으로 학습을 진행하게 된다.
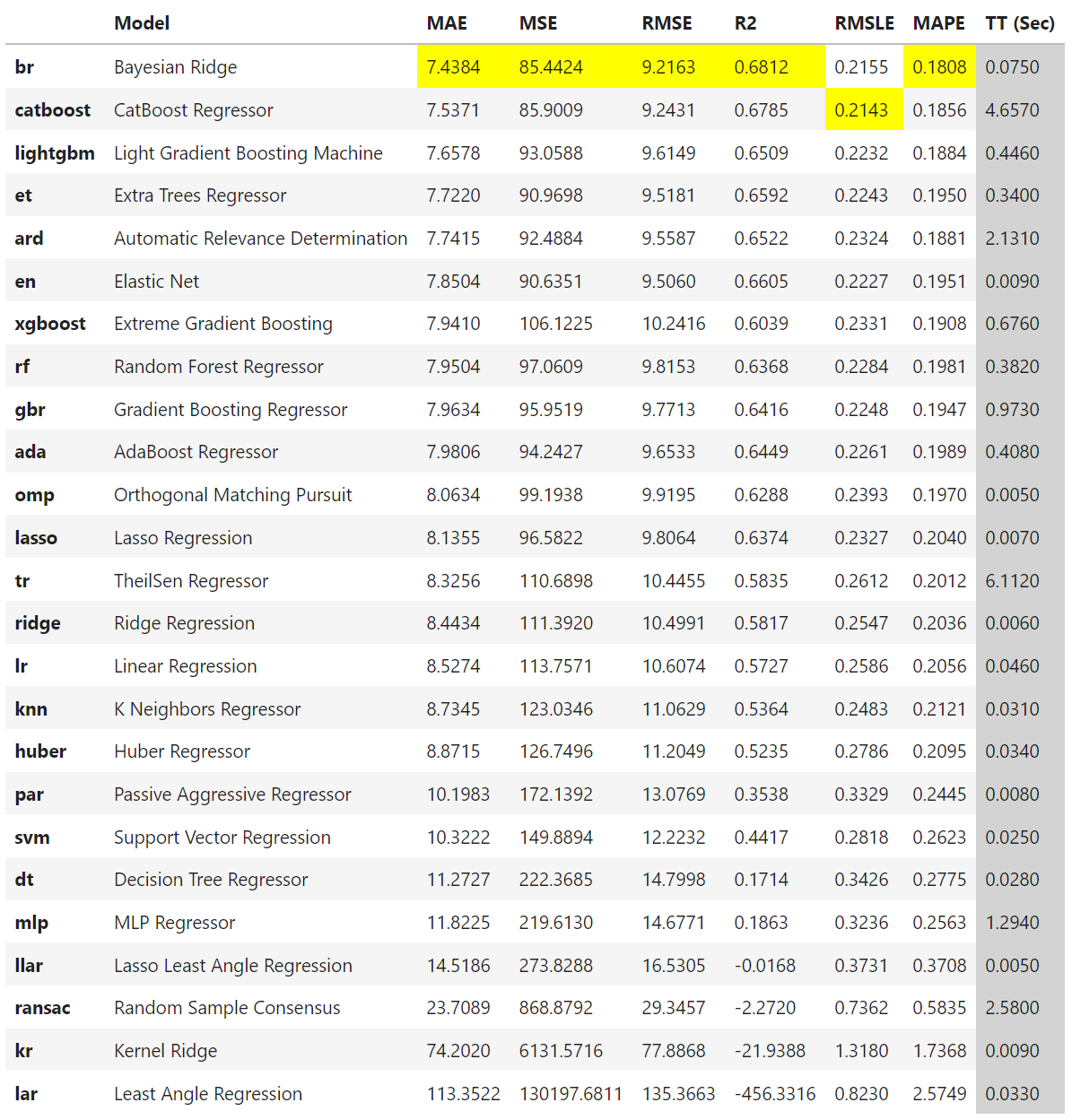
이 결과를 보면 알 수 있듯이, 몇몇 모델은 아주 안좋은 성능을 내고 있는 것을 확인할 수 있다. 이런 모델들은 입력한 data set과 현재 Model의 파라미터 세팅이 서로 맞지 않는 경우가 대부분이므로, Pycaret의 tune_model( ) 함수를 사용하거나, 별도로 manual Tuning이 필요한 작업이다.
또한, 위의 Score Grid를 DataFrame의 형식으로 사용하고 싶은 경우에는 pull( ) 이라는 함수를 통해서 위의 Score Grid를 변수에 저장할 수 있다. pull( ) 을 사용하면, 가장 최근에 Pycaret에서 제공해준 DataFrame을 해당 변수에 저장을 해준다. 이는 compare_models( ) 에서 제공해준 DataFrame 뿐 아니라, 이후에 나오는 모든 메서드에서 제공해주는 Data Frame에도 동일하게 적용된다.
compare_model( )의 return 값을 저장한 pycaret_regression_model 이라는 변수는 총 25가지 학습된 Regressor가 저장이 되어 있는 List이다.
create_model( )
여러 모델이 아닌 하나의 모델에 대해서 setup( ) 의 설정대로 학습을 진행하고, 학습의 결과를 확인할 수 있다. 또한, 세부적으로 각 Fold에 대한 성능을 제시해준다.
lasso_model = create_model('lasso')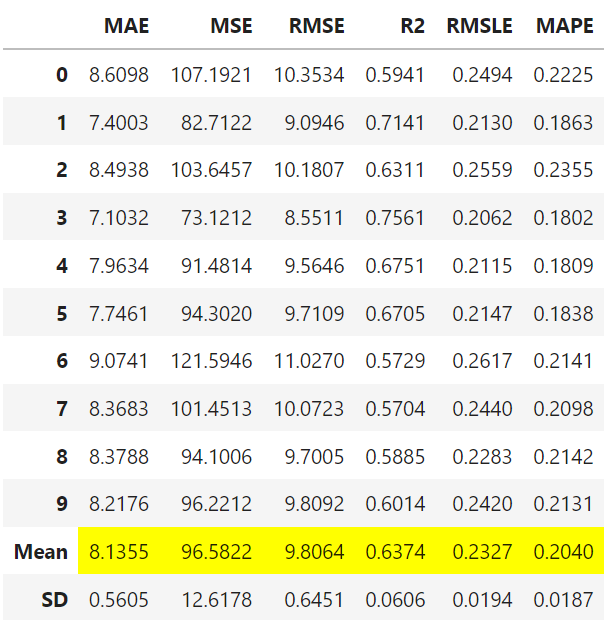
tune_model( )
입력한 모델에 대해서 Hyper-parameter Tuning을 수행한다. 이전에는 Pycaret에서 기본적으로 제공해주는 함수의 ID를 입력해도 되었지만, Version이 업그레이드 되면서, 별도로 지정해준 모델에 대해서 Tuning을 수행해주는 것으로 보인다.
from sklearn.linear_model import *
default_lasso_model = Lasso()
tuned_lasso_model = tune_model(default_lasso_model, n_iter =100, optimize='MAE')- n_iter : Tuning하여 성능을 비교할 후보군의 수를 의미한다. 이 값을 크게 해줄수록 성능이 더 좋아질 가능성은 높지만, 더 많은 시간이 걸리므로, 각 Task에 맞게 적절한 값을 설정해주어야 한다.
- optimize 는 Tuning을 할 때에 어떤 Metric을 기준으로 하여 Tuning 된 모델을 선별할 것인지를 설정하는 하이퍼파라미터이다. ‘MAE’, ‘R2’,’MSE’ 등을 설정해줄 수 있다. (Pycaret의 이전 버전에서는 Default Model과 Tuning된 모델을 비교하지 않아, 오히려 Tuning된 모델이 Default Model보다 더 안좋은 성능을 보이는 경우가 있었고, 이를 위해서는 하이퍼파라미터를 별도로 설정을 해주어야 했는데, 버전이 업데이트 되면서, Default Model과도 성능을 비교하여 가장 좋은 성능을 보이는 모델을 선별해준다. 혹시, Tuning 된 모델이 Tuning하지 않은 모델보다 좋지 않은 성능을 보인다면, Pycaret의 버전이 최근 버전인지 확인해보자.)

create_model( ) 을 수행했을 때는 평균 MAE 값이 8.1정도 였던 것에 비해서, Tuning을 해준 이후에는 7.4로 MAE 값이 줄어든 것을 확인할 수 있다.
save_model( )
학습한 모델을 저장해주는 메서드로, pickle file(.pkl)로 지정한 디렉토리에 저장한다. (디렉토리 경로를 입력하는 경우에는 .pkl 을 써주지 않아도 된다.)
save_model(tuned_lasso_model, './lasso')
load_model( )
위에서 save_model( )을 통해서 저장한 모델을 다시 불러오는 메서드이다. 제대로 Load 되지 않는 경우가 종종 발생하는데, 나의 경우에는
1. 다시 한번 Pycaret을 import 해주는 부분을 실행하면 성공적으로 Load가 되었다.
2. Model을 저장했던 computer와 다른 computer에서 load_model( ) 을 수행하는 것이라면, pandas의 버전이 save했던 computer의 pandas version과 같거나 더 최신 버전이어야 한다.
load_lasso = load_model('./lasso')
나의 경우에는 Tuning 한 모델을 자동적으로 저장을 하고, 이를 다시 불러오는 경우에 save_model( )과 load_model( )을 많이 사용하였다. Load된 모델의 Hyper-parameter setting을 보기 위해서는 'trained_model'을 이용하여 확인할 수 있다.
load_lasso['trained_model']
'소개 및 연구분야 > 한주혁 - NeuroScience' 카테고리의 다른 글
| Pycaret - Feature Importance 뽑기 (0) | 2022.07.24 |
|---|---|
| An Uncertainty-Aware Transfer Learning-Based Framework for COVID-19 Diagnosis - 논문 리뷰 (0) | 2022.01.22 |

최근댓글