
안녕하세요
팀 분석 프로젝트로 돌아온
브라이틱스 서포터즈 3기 이상민입니다 :)
이번 주부터 4주 동안은
브라이틱스 서포터즈 3조로서
팀원들과 함께 데이터분석 팀 프로젝트를 진행하게 되었는데요.
분석 결과를 바탕으로
영상 제작도 진행할 예정이니 다들 기대해주세요!!

저희 3조가 진행할 팀 분석 프로젝트는
텍스트 데이터로 MBTI 예측하기입니다.

MBTI란 정신분석학자 카를 융(Carl Jung)의 심리 유형론을 토대로
만든 성격 유형 검사인데요.
네 가지의 상대적인 선호 지표를 조합해
사람의 성격 유형을 16가지로 분류합니다.
이런 MBTI를 텍스트로 분류해보면 어떨까요??
데이터는??
MBTI별 포스팅 : https://www.kaggle.com/code/mercurio117/mbti-500/data
국가별 MBTI 비율 : https://www.kaggle.com/datasets/yamaerenay/mbtitypes-full
reddit mbti별 발자취 : https://www.kaggle.com/datasets/michaelkitchener/mbti-type-and-digital-footprints-for-reddit-users
kaggle에 있는 데이터를 통해 MBTI를 분류해보고자 합니다.
데이터는 MBTI유형을 가진 사람이 포스팅한 글인데요.
텍스트마이닝 기법을 활용해 특정 단어의 빈도나, 어투 등을 활용하여
MBTI를 예측하는 모델을 브라이틱스를 활용해 진행하고자 합니다.
분석 진행 계획은 ??
먼저 텍스트 데이터는 컴퓨터가 인식할 수 있도록
데이터를 정제하고 숫자로 변환해주는 과정을 거쳐야 하는데요.
불용어나 URL등 불필요한 단어들을 처리해주고
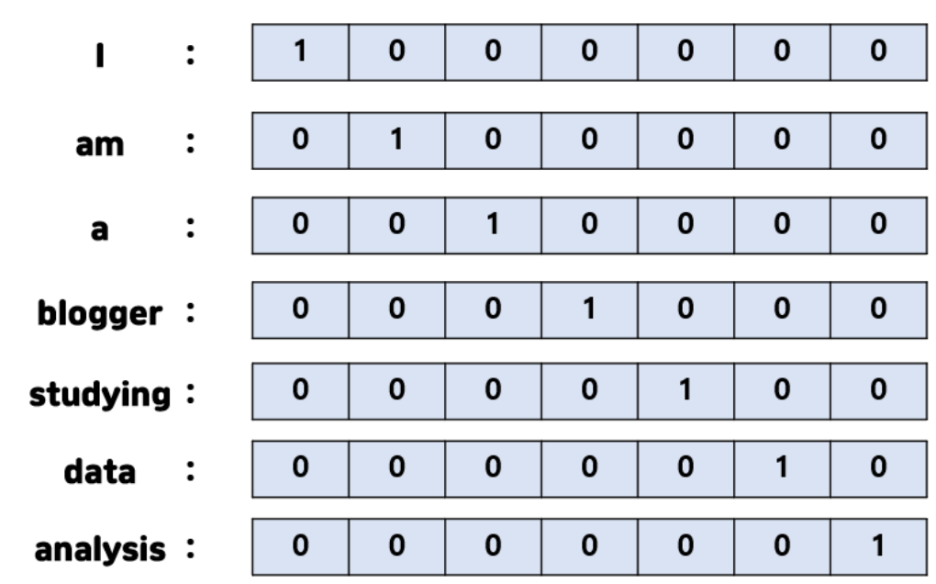
Embedding기법을 통해 단어를 숫자로 변환해주고자 합니다.
그 다음 브라이틱스 안에 있는 머신러닝 및 딥러닝
분류 알고리즘을 통해 각각의 MBTI로 분류하는데요.
이 때 제가 맡은 부분이 바로 이 머신러닝 및 딥러닝 분류 알고리즘 파트입니다!
그 후 시각화를 통해 빈출 단어, 포스팅 길이, 맞춤법 및 특수문자 비율이
MBTI별로 어떻게 분포되어 있는지 확인하면 끝!
정말 재밌을 것 같지 않나요??

저희 조는 ZOOM으로 회의를 진행하고
Notion으로 프로젝트 일정을 관리하고 있는데요.

앞으로 4주동안 진행될 분석 프로젝트!!
많이 기대해주세요 :)
지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.

최근댓글