
안녕하세요!!
저번주에 MBTI 예측 기획 및 구상에 이어
1주만에 다시 돌아온
브라이티스 서포터즈 3기 이상민입니다.
이번주는 업무분배 및 주제구체화
그리고 간단하게 브라이틱스를 이용하여
MBTI예측 프로젝트를 진행했는데요.
그럼 어떻게 했는지
함께 알아보러 가실까요??

저희가 정했던 프로젝트 주제는
텍스트 데이터로 MBTI예측하기였는데요.
MBTI별 포스팅 : https://www.kaggle.com/code/mercurio117/mbti-500/data
국가별 MBTI 비율 : https://www.kaggle.com/datasets/yamaerenay/mbtitypes-full
reddit mbti별 발자취 : https://www.kaggle.com/datasets/michaelkitchener/mbti-type-and-digital-footprints-for-reddit-users
이 3개의 데이터를 가지고
MBTI와 관련된 분석을 진행하여 예측하기로
기획했었습니다!
주제를 좀 더 구체화하고 체계적으로 진행하고자
회의를 한 번 더 진했었는데요.
분석 계획은 다음과 같이 의논하여 정했습니다.
분석계획
분석과정1) 텍스트 데이터로 MBTI 예측하기
1.1 데이터 전처리
- URL 제거
- accented character 제거
- 축약어 → 원래 형태로 변환
- 모든 단어 원형화(lemma)
- 불용어 제거
1.2 토큰 대체
- MBTI가 적혀있는경우 <MBTI> 토큰 대체 (일종의 Masking)
- url이 있는 자리에 제목을 넣은 뒤 <hyptertext>라는 토큰으로 대체
- 이미지나 gif가 있을시 alt tag 내용물(html태그)을 대신 넣어줌
1.3 임베딩
- one-hot-encoding 내장함수 사용
- countvectroizer sklearn함수 비교
- min, max df 하이퍼 파라미터 조정
- word2vec, doc2vec 모델 비교
1.4 분류 알고리즘(머신러닝)
- 브라이틱스에 있는 모든 머신러닝 알고리즘
- 스태킹 앙상블 하는 법도 추가
분류 알고리즘(딥러닝)(C)
- MLP, layer를 쌓고 하이퍼 파라미터를 조정하는 법 소개
16개로 분류 하는 것 vs (e, i), (s, n), (f,t), (p,j)로 분류하는 것
1.5 시각화
- 각 mbti에서 자주 나타나는 단어
- 영향을 주는 단어
- 포스팅 길이
- 맞춤법, 특수문자 사용 비율
분석2) - 국가별 mbti 비율 시각화
- 국가별로 어떤 국가에 어떤 mbti가 많이 나타나있는지 시각화
- 막대, 파이, 지도 다양한 시각화 기법을 소개
분석3) - reddit mbti 발자취
- reddit 사이트를 이용한 기록 패턴 분석
- 좋아요 누르는 비율
- 포스팅 길이
- 각종 변수를 통해 간단한 분석 진행
이렇게 분석 과정을 구체화 했는데요
MBTI데이터에 관한 모든 것을
브라이틱스에 있는 기능들을 통해 파헤쳐보고자 했습니다 :)
팀들이 각자 자신있는 파트를 하나씩 고른다음
해온 결과를 피드백하여 결합하면서 진행!!
저는 여기서 머신러닝 및 딥러닝 알고리즘 파트를 맡았고
이번주는 간단한 데이터 처리와 알고리즘 전까지
데이터 변환을 진행했습니다.
데이터 추출
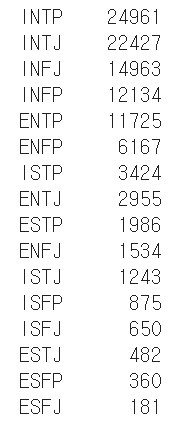
먼저 데이터의 클래스별 개수를 보자면
불균형 현상이 매우 심한 것을 볼 수 있었습니다.
문제점을 해결하고자 가장 적은 개수인 ESFJ로
데이터 개수를 맞추는 다운샘플링을 진행하였는데요.
각각 모든 MBTI 데이터를 181개씩 맞춰 데이터를 합쳤습니다.
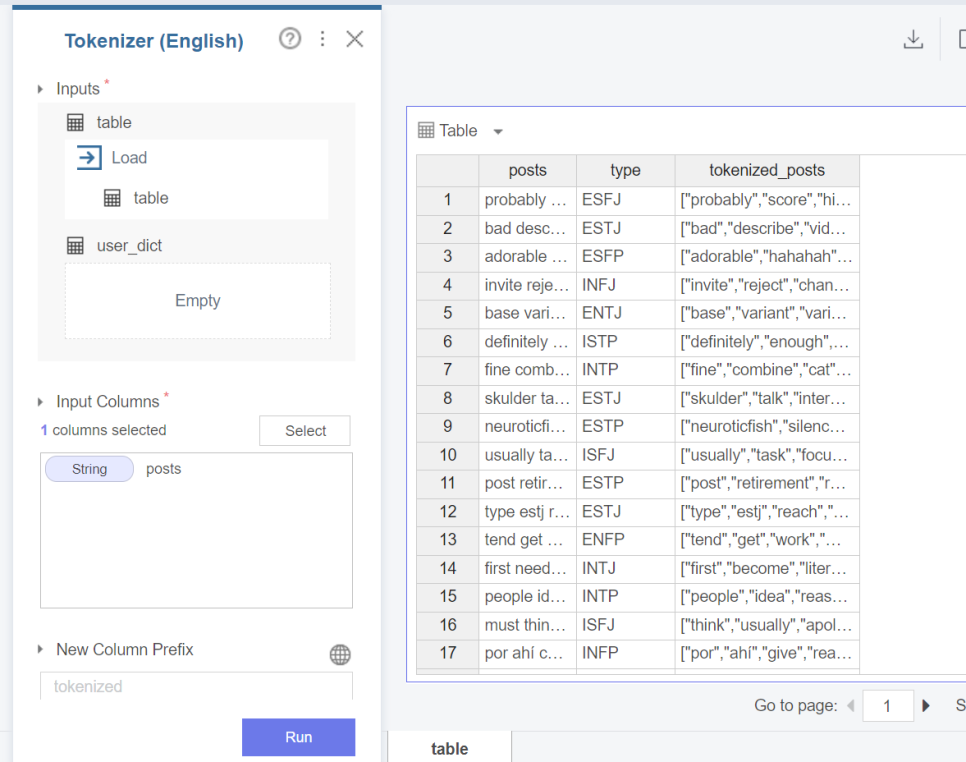
먼저 데이터에는 MBTI별 포스팅한 글이랑 MBTI의 type이 있는데요.
이 문장들을 각각의 단어로 분리하는 토큰화를 진행했습니다.
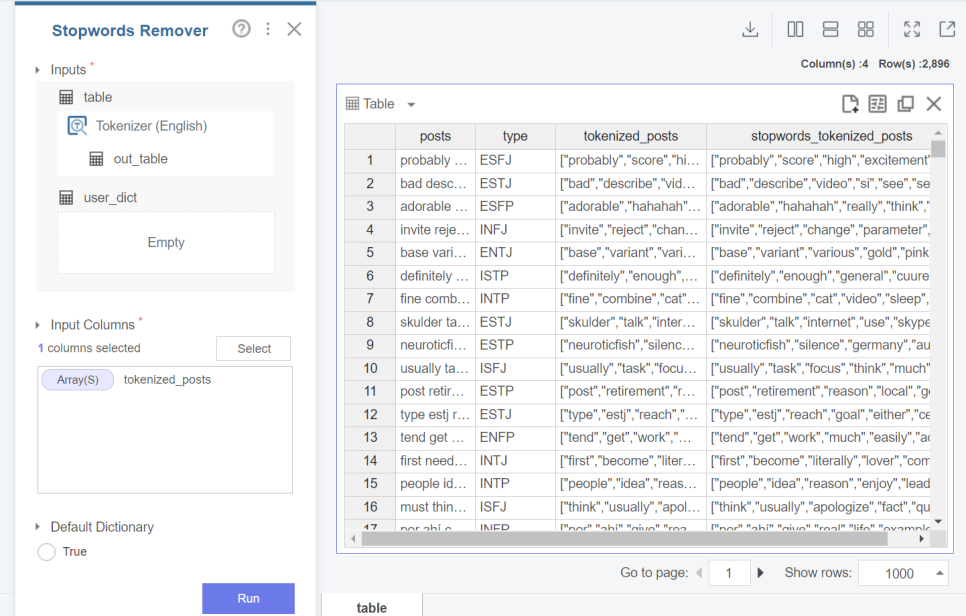
그 후 i,my,me,mine과 같은 불필요한 단어가 들어갔을 시
학습 성능이 저하될 수 있기에 불용어처리를 진행해줬습니다!
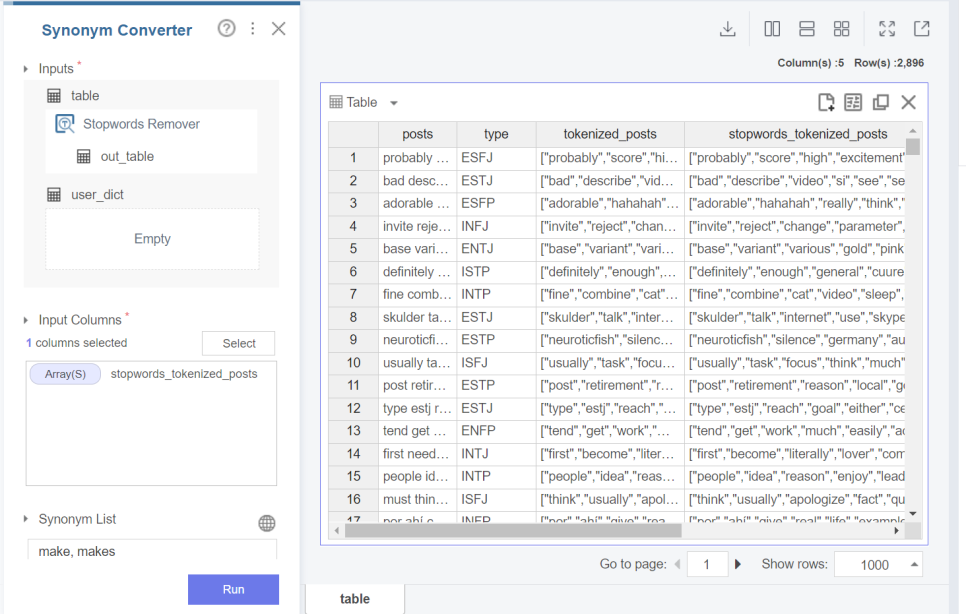
또한 브라이틱스에는 동의어를 처리해주는 함수까지 있는데요.
저는 이 함수가 굉장히 유용한 것 같습니다.
동의어를 사용자가 지정하여 같은 단어로 변환해주고
최종적으로 텍스트를 기계가 이해할 수 있는 숫자로 변환해주기 위해
embedding과정을 진행합니다.

마지막으로 layer를 여러 겹 쌓은 MLP모델을 진행하여
분류를 완료!
이번 포스팅은 대략적인 분석 과정에 대해
소개했는데요.
다음 포스팅에는 각 과정을 좀 더 깊게 소개하고
다양한 기법을 비교하여 실험을 진행하고자 합니다.
다음주도 많이 기대해주세요 :)

지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
'삼성 SDS Brightics' 카테고리의 다른 글
| [Brightics Studio] # 팀 분석 프로젝트 - 04 MBTI 예측하기 최종 (0) | 2022.09.06 |
|---|---|
| [Brightics Studio] # 팀 분석 프로젝트 - 03 분류모델로 MBTI 예측, 텍스트 데이터로 MBTI 예측하기 (0) | 2022.08.30 |
| [Brightics Studio] # 팀 분석 프로젝트 - 01 기획 및 구상, 텍스트 데이터로 MBTI 예측하기 (0) | 2022.08.17 |
| [Brightics Studio] #02-3 영화 리뷰 데이터를 분석하기 - Modeling and Text Analysis (0) | 2022.07.12 |
| [Brightics Studio] #02-2 영화 리뷰 데이터를 분석하기 - Data Preprocessing (0) | 2022.07.05 |

최근댓글