
안녕하세요 :)
저번주에 머신러닝/딥러닝 모델로 MBTI분류하기에 이어
1주만에 다시 돌아온
브라이티스 서포터즈 3기 이상민입니다.
이번주는 지금까지 진행한 팀프로젝트를
총집합하여 정리하였습니다.
어떻게 브라이틱스로
MBTI를 예측하고 분석했는지
한 번 알아보러 갈까요??

저희팀은 3~4주동안
MBTI예측하기 프로젝트를 진행했는데요.

엠브레인 통계조사에서 MBTI에 대한 관심도는
무려 76.1퍼센트라고 합니다.
그만큼 MBTI에 대한 관심도가 많아,
저희는 MBTI 데이터셋들을 구해 진행했습니다.
데이터셋 설명

총 3가지의 데이터셋을 사용했습니다.
첫 번째는 MBTI별로 포스팅한 데이터셋이고,
두 번째는 국가별 MBTI 비율
세 번째는 MBTI별로 Reddit이라는 외국사이트를 이용한 내역입니다.
이 데이터셋을 가지고
저희는 텍스트마이닝 기법으로 MBTI를 예측하는 모델을 만들고
MBTI가 국가별로 얼마나 분포하는지, 어떤 MBTI가
글을 길게 쓰고 짧게 쓰는지 분석하였습니다.
데이터 전처리
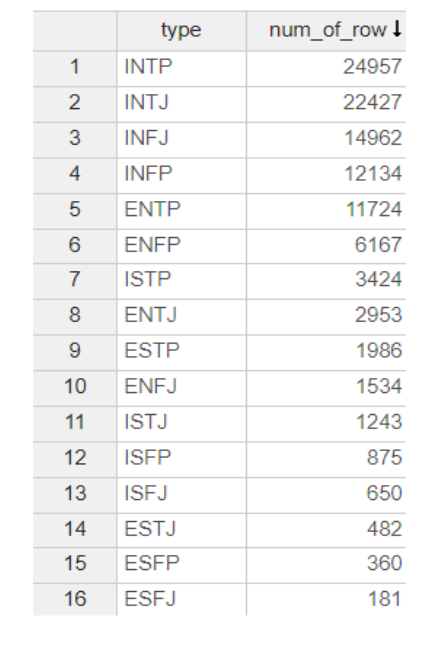
mbti별로 포스팅한 데이터셋을 봤을 때,
class 불균형 현상이 매우 심했는데요.
class 불균형 현상이 일어나면 한 쪽으로 편향되어
학습이 일어날 수 있기 때문에,
아래와 같이 downsampling을 진행해줬습니다.
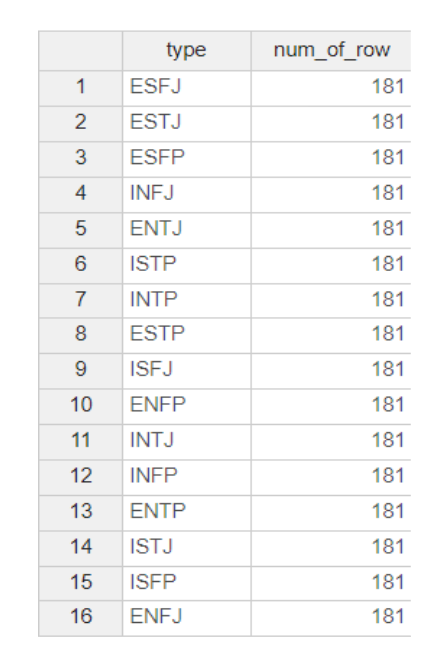
위와 같이 가장 적은 class 개수로 맞춰주었습니다.

다음은 regular expression이라는
함수를 사용하여 bias가 될 수 있는
특수문자를 제거해줬습니다.

그 후 captialize variable을 통해
대문자와 소문자를 모두 소문자로 변환해줬는데요.
make와 MAKE를 컴퓨터가 다르게 인식하기 때문에
make라는 하나의 문자로 통일해줬습니다.

다음 토큰화 기법을 통해 문장들의 단어를
각각의 배열 내 원소 형태로 변환해줬습니다.
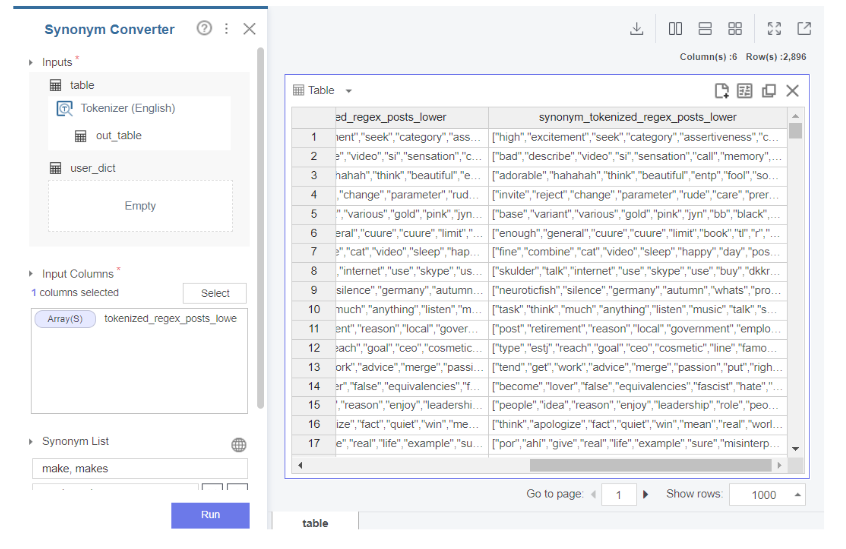
또한 make와 makes 같이
단수 복수 형태 단어들을
동의어로 처리해주고
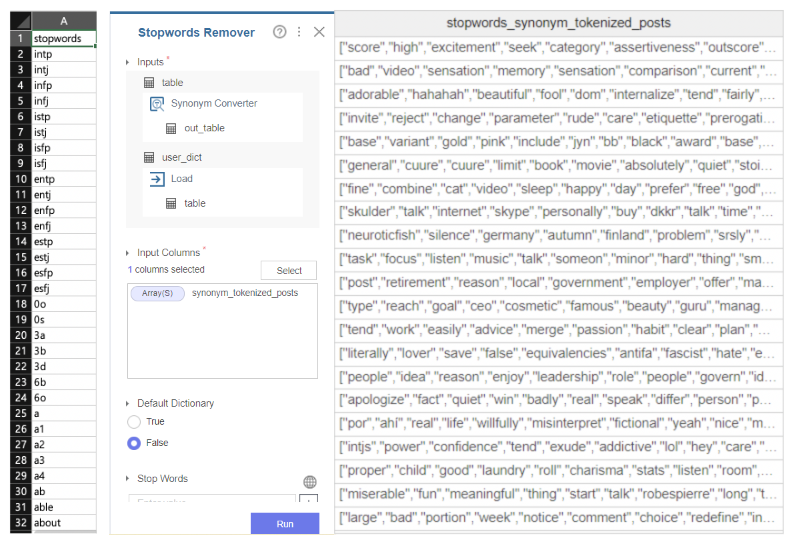
nltk에 있는 불용어 사전을 바탕으로
불용어를 처리해줬습니다.
또한 포스팅에는 mbti를 나타내는 글이 있는데요.
이 mbti가 포스팅 내에 있으면 학습 시 올바른 예측이 안 되기 때문에
이 또한 제거해줬습니다.
임베딩
다음은 임베딩 기법입니다.
먼저 임베딩이란 컴퓨터가 알아들을 수 있도록
텍스트를 숫자(벡터)로 변환해주는 작업인데요.
저희는 bag of words, tf-idf, word2vec(cbow, skip-gram)을 사용하였습니다.
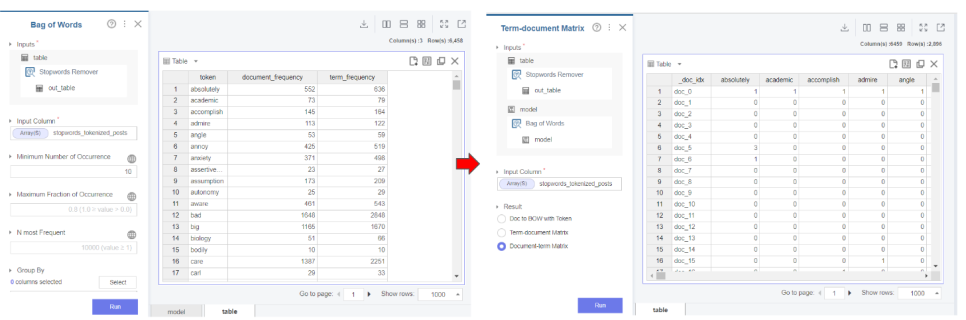
먼저 bag of words란 단어들의 빈도수를
각각의 벡터로 변환해주는 기법입니다.
브라이틱스 내 bag of words함수를 사용하여 수치화해주고
term-document matrix를 통해 행렬처리해줬습니다.
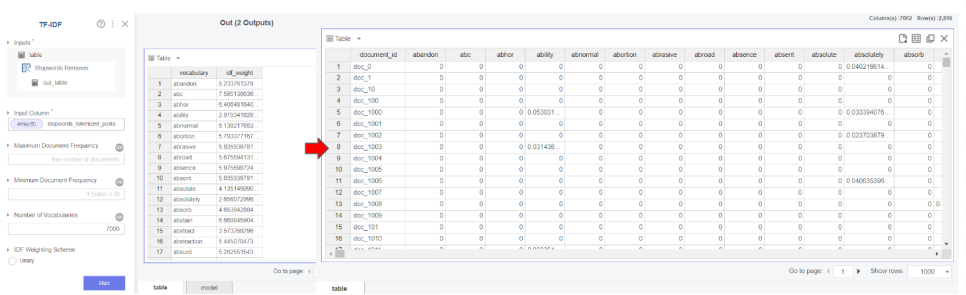
그 다음 tf-idf기법을 사용하였는데요.
먼저 tf란 term frequency로 문서 내에 단어 빈도
idf란 inverse document frequency는 다른 문서 내에 단어 빈도를
역수 취한 값으로
이 둘을 곱하여 특정 문서 내에서만 유의미하게 나타나는 단어 값을
구할 수 있습니다.
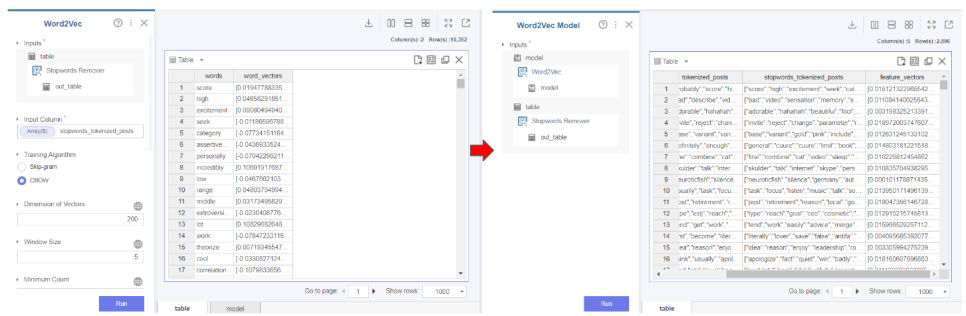
다음 word2vec는 cbow와 skip-gram으로
나눠지는데
cbow는 주변에 있는 단어들을 입력으로 중간에 있는 단어를 예측하고
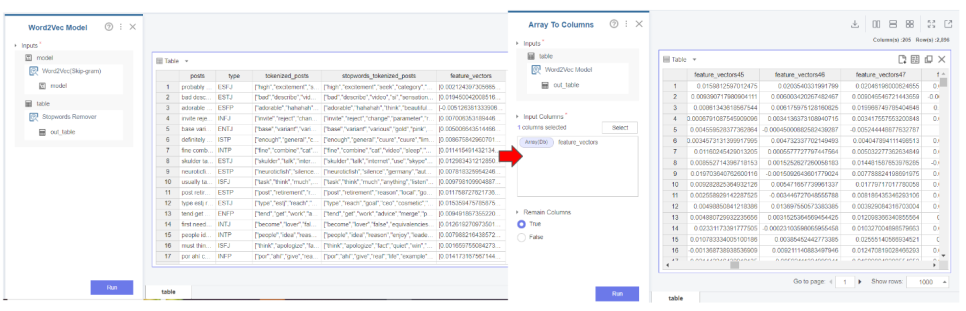
skip-gram은 중간에 있는 단어를 가지고 주변에 있는
단어를 예측하는 기법입니다.
이렇게 총 4가지의 기법을 비교한 결과
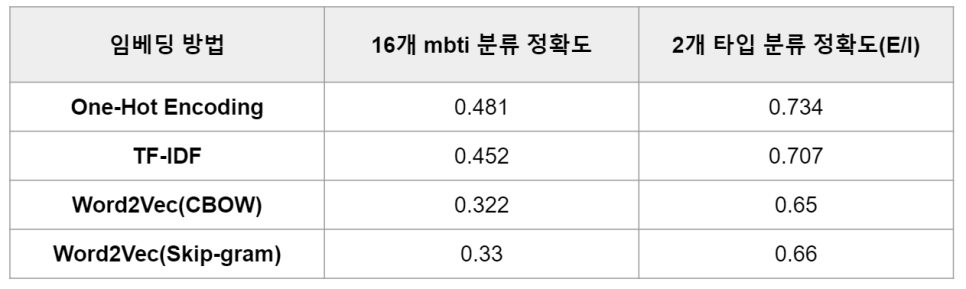
위와 같은 결과를 낳았는데요.
가장 베이직한 bag of words기법을 통해
one-hot encoding한 것이 높게나와
bag of words를 가지고 모델 비교를
진행하였습니다.
모델링
다음 모델링입니다.
모델링은 먼저 mbti 16개를 분류하는 모델과
2개를 분류하는 모델(EX - E/I)을 선정하였는데요.
일단 둘 다 분류모델이기 때문에
분류모델인 ml기법 중 xgboost와 adaboost를 실험하였고
dl은 mlp를 실험하였습니다.
그리고 2개를 분류하는 모델은
logistice regression을 사용하였습니다.
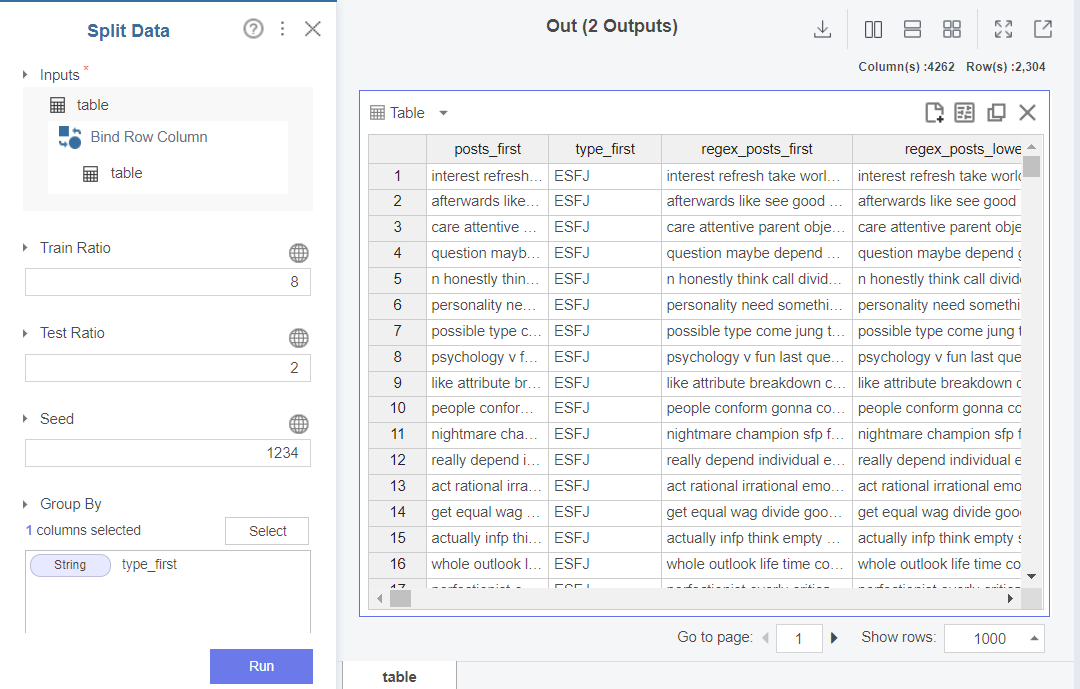
먼저 train과 test로 분리하기 위해
split data 함수를 사용하여 분리해줍닏.
이 때 똑같은 데이터셋의 실험 비교를 위해 seed를 1234로 고정해주고
test의 비율은 데이터가 크지 않기 때문에 0.2로 설정해줍니다.
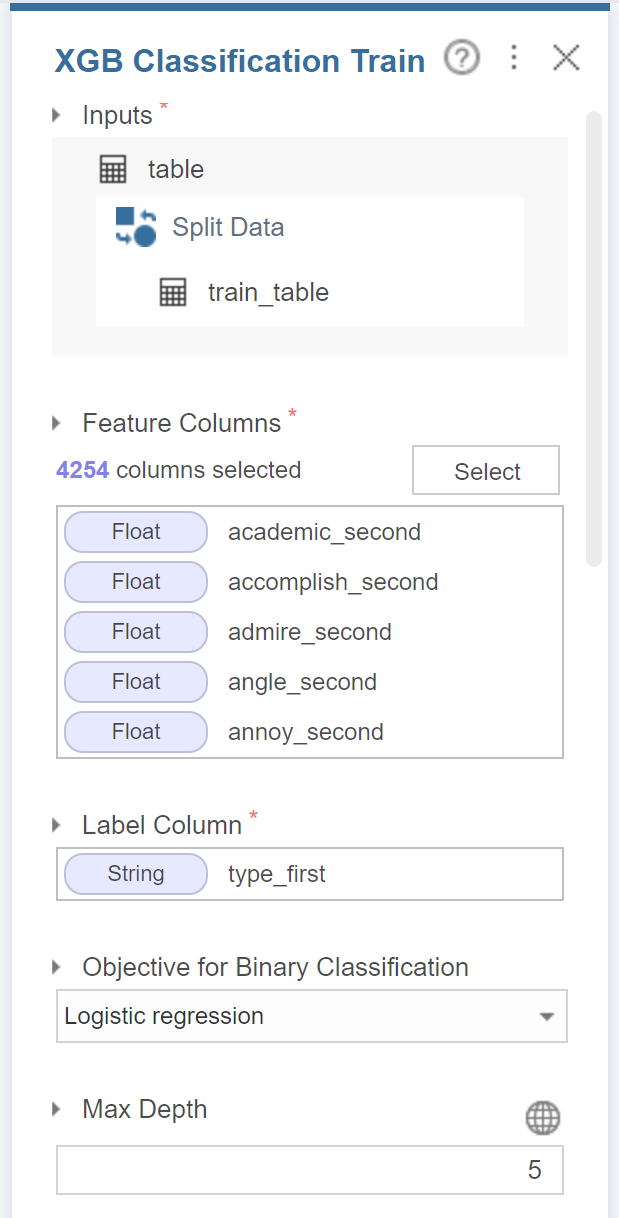
그 후 xgboost의 변수는
기존 bag of words에서 구한 값으로 설정하고
모델의 복잡도를 설정하는 파라미터인 max depth를 5로 설정해줍니다.
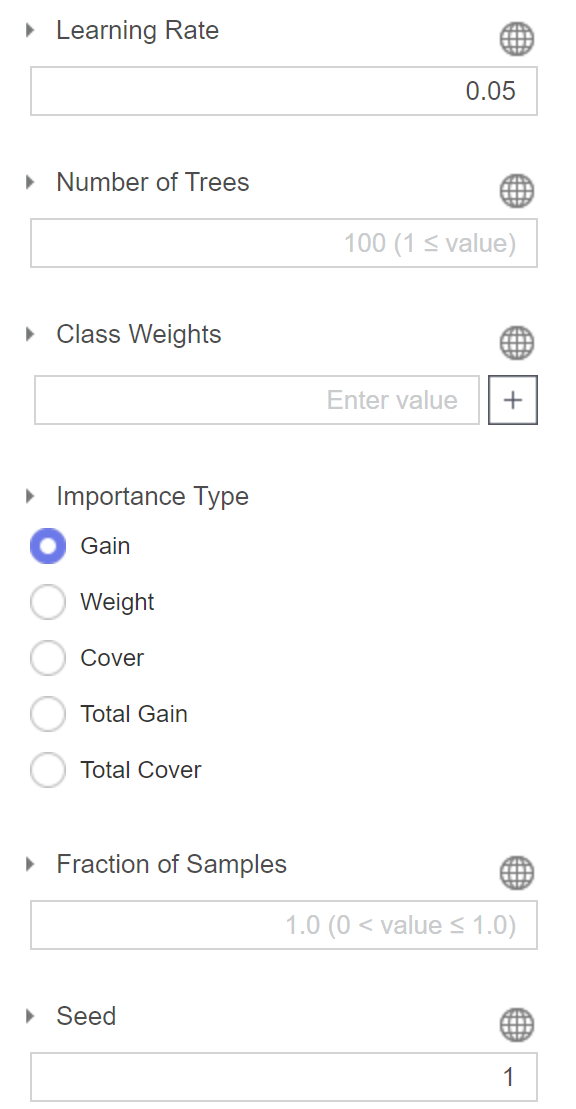
다음 gradient descent를 진행하는
즉 local minima로 수렴하기 위해
학습률을 0.05로 설정해줍니다.
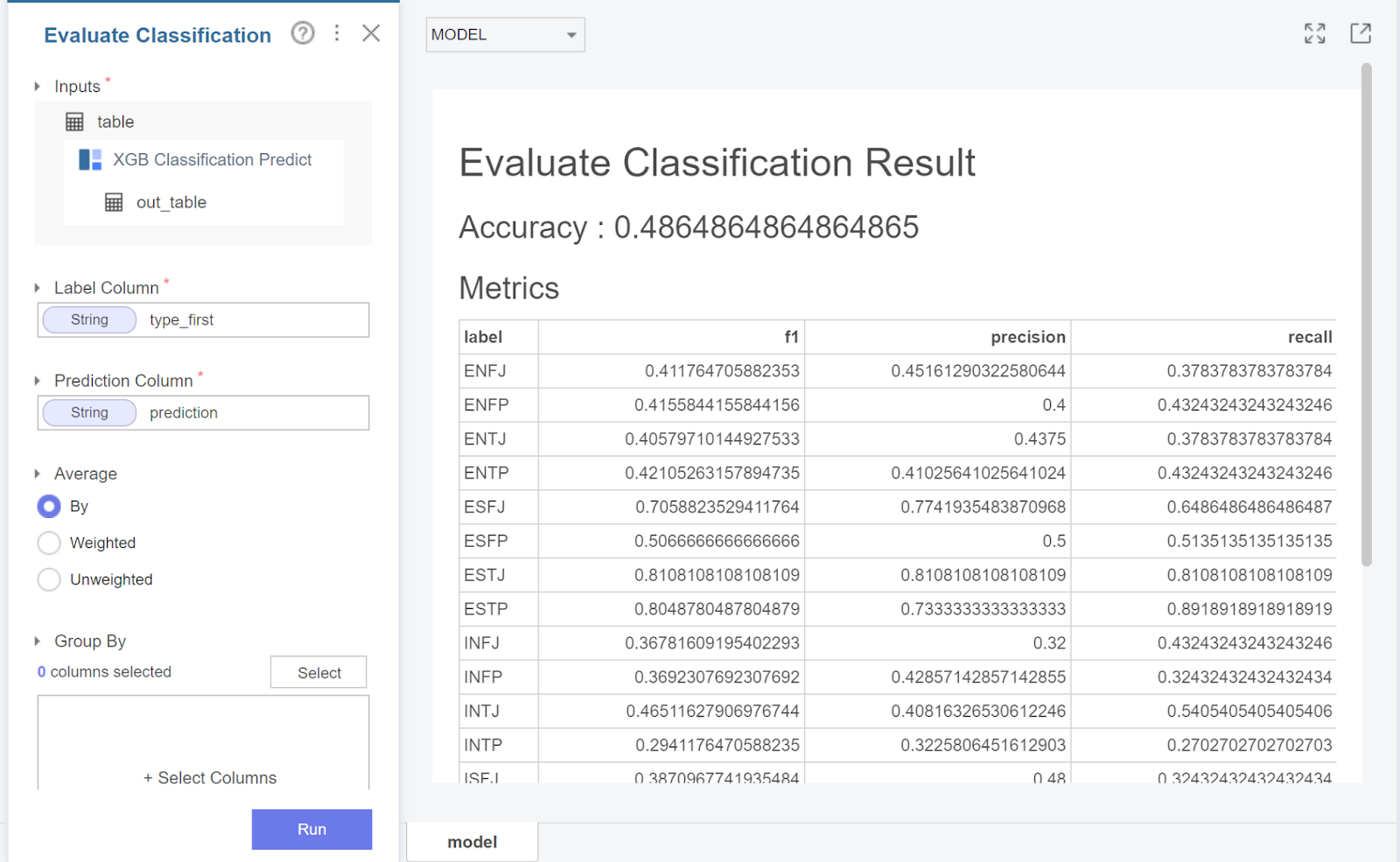
학습 결과 0.486이 나왔는데요.
label이 16개이고
데이터가 비교적 적다보니 0.5를 넘기지 못한 것 같습니다.
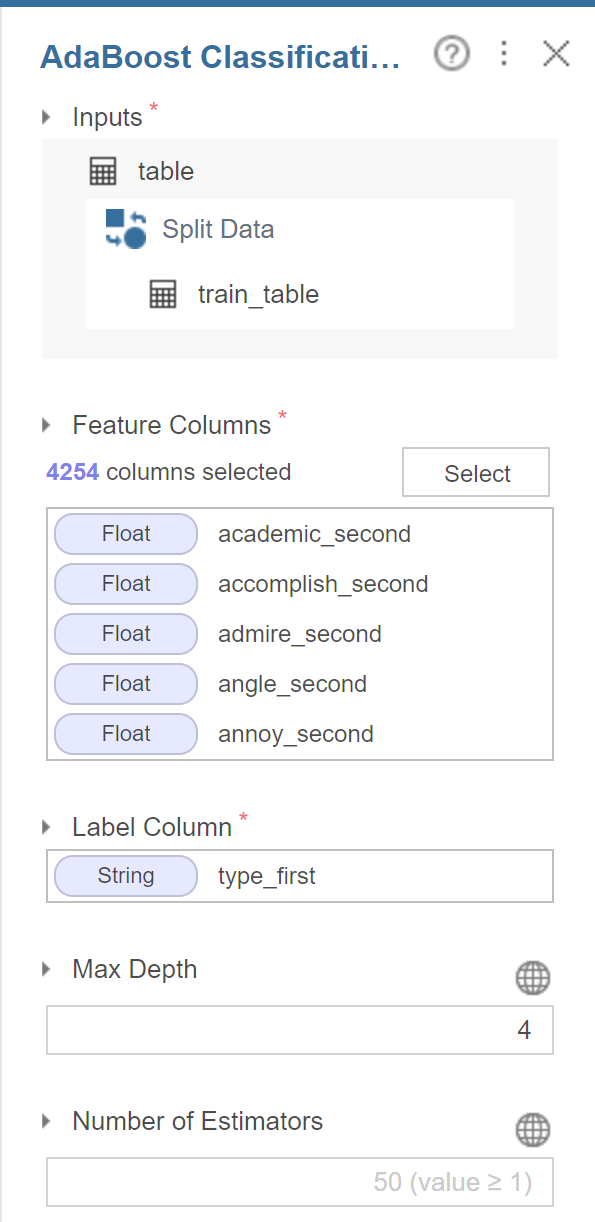
다음은 adaboost입니다.
변수는 xgboost와 마찬가지로 설정하였고
학습 반복횟수인 estimators를 조정할 수 있기에
50으로 설정하였습니다.
위와 같이 하이퍼 파라미터를 설정하고
실험을 진행합니다.
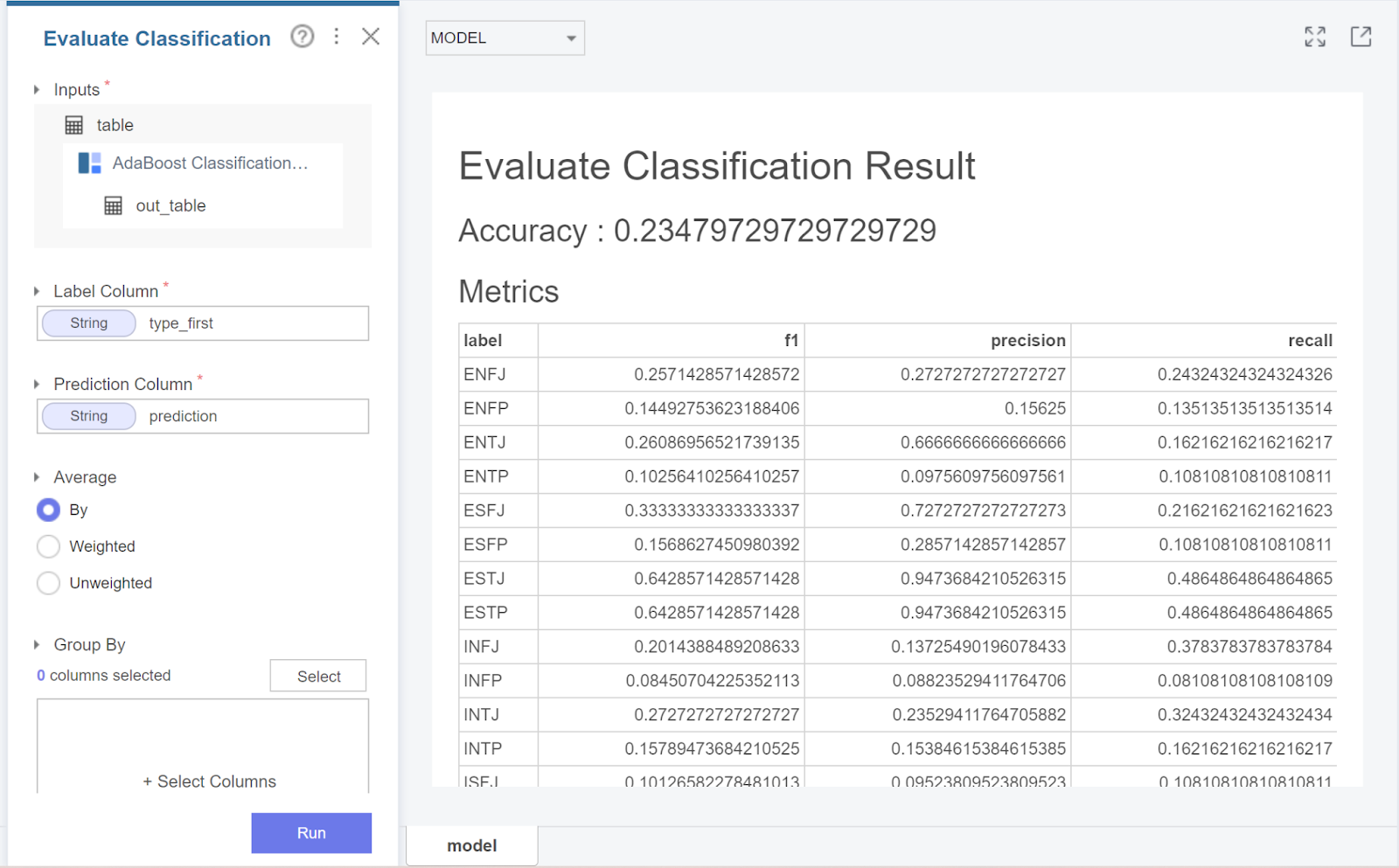
adaboost는 0.234가 나왔는데요
xgboost에 비해 결과가 현저히 낮은 것을 볼 수 있었습니다.
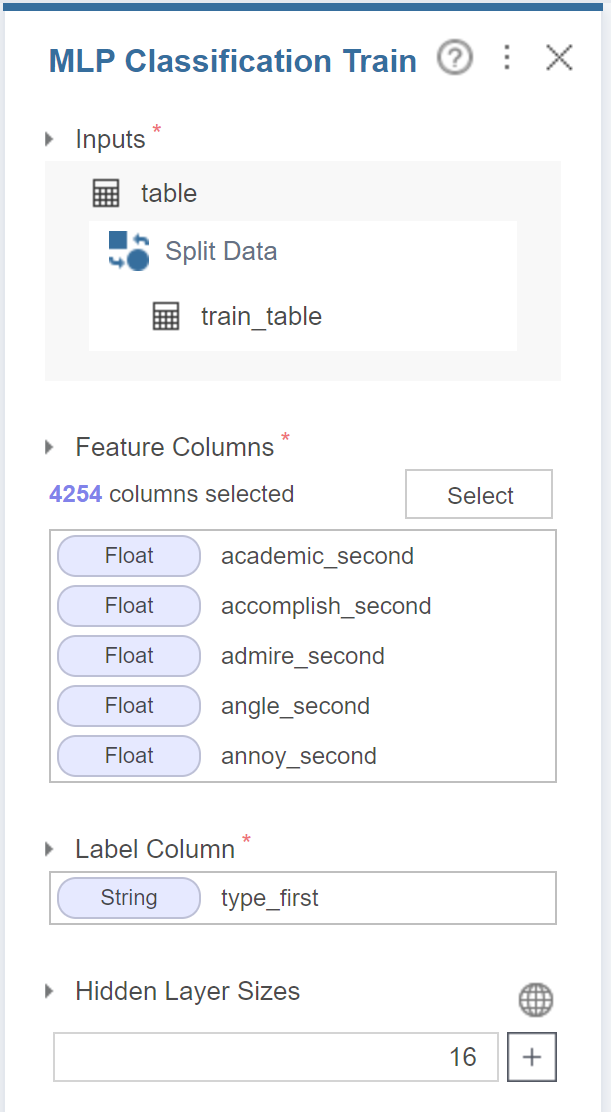
다음은 딥러닝 기법 중 하나인
MLP를 통해 실험해봤는데요.
모델의 용량을 늘리는 Hidden layer sizes를 16으로 설정하고
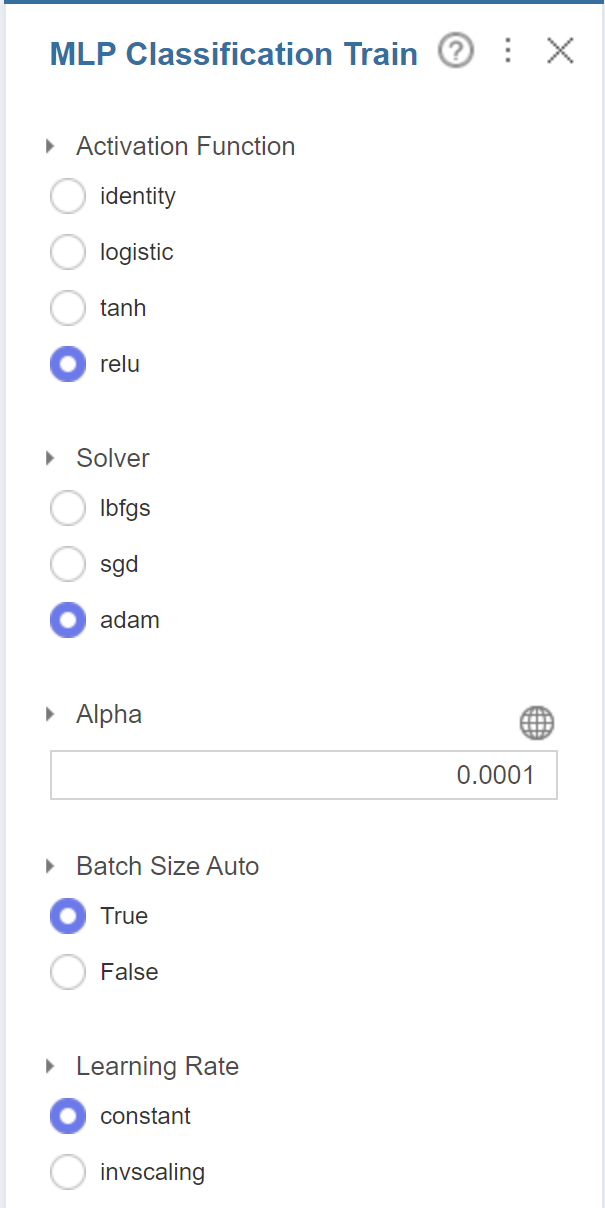
activation function과 optimizer를
각각 relu와 adam으로 설정해줬습니다.
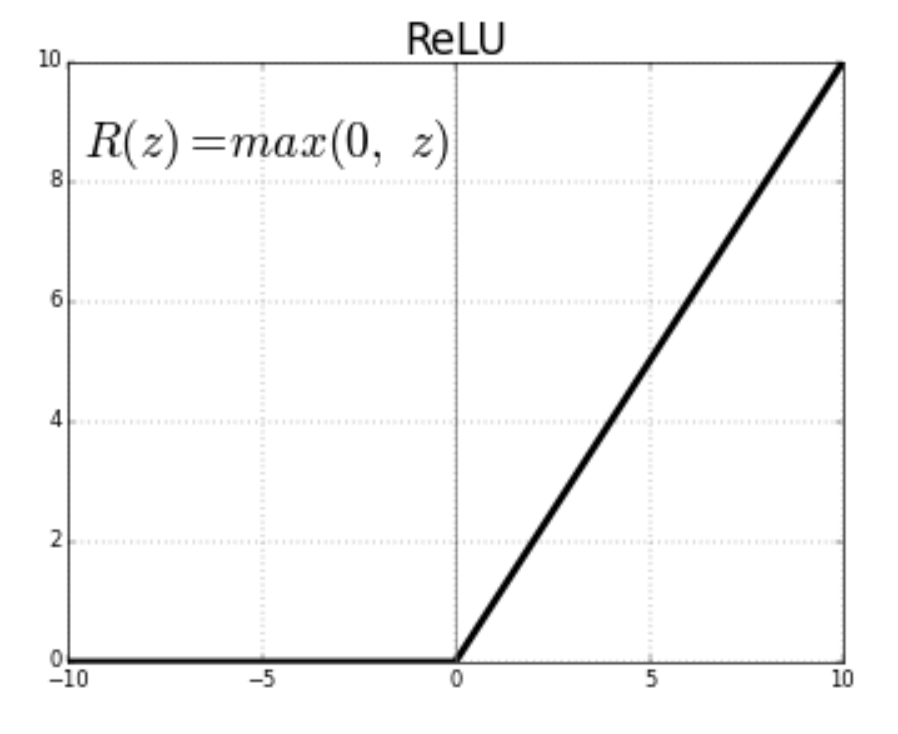
여기서 relu함수란 위와 같은 형태를 띄고 있는데요.
위 함수가 역전파 시 값을 미분할 때,
비교적 온전히 보존하는 특성이 있어
좋은 성능을 가져와준다고 합니다.
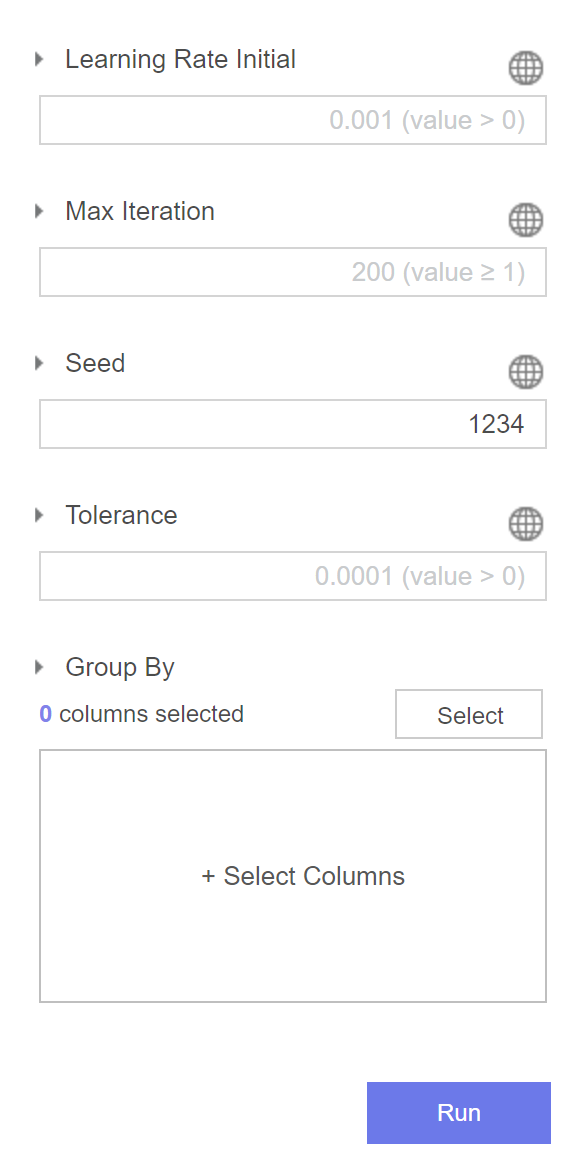
다른 하이퍼 파라미터들도 위와 같이 설정해줬습니다.
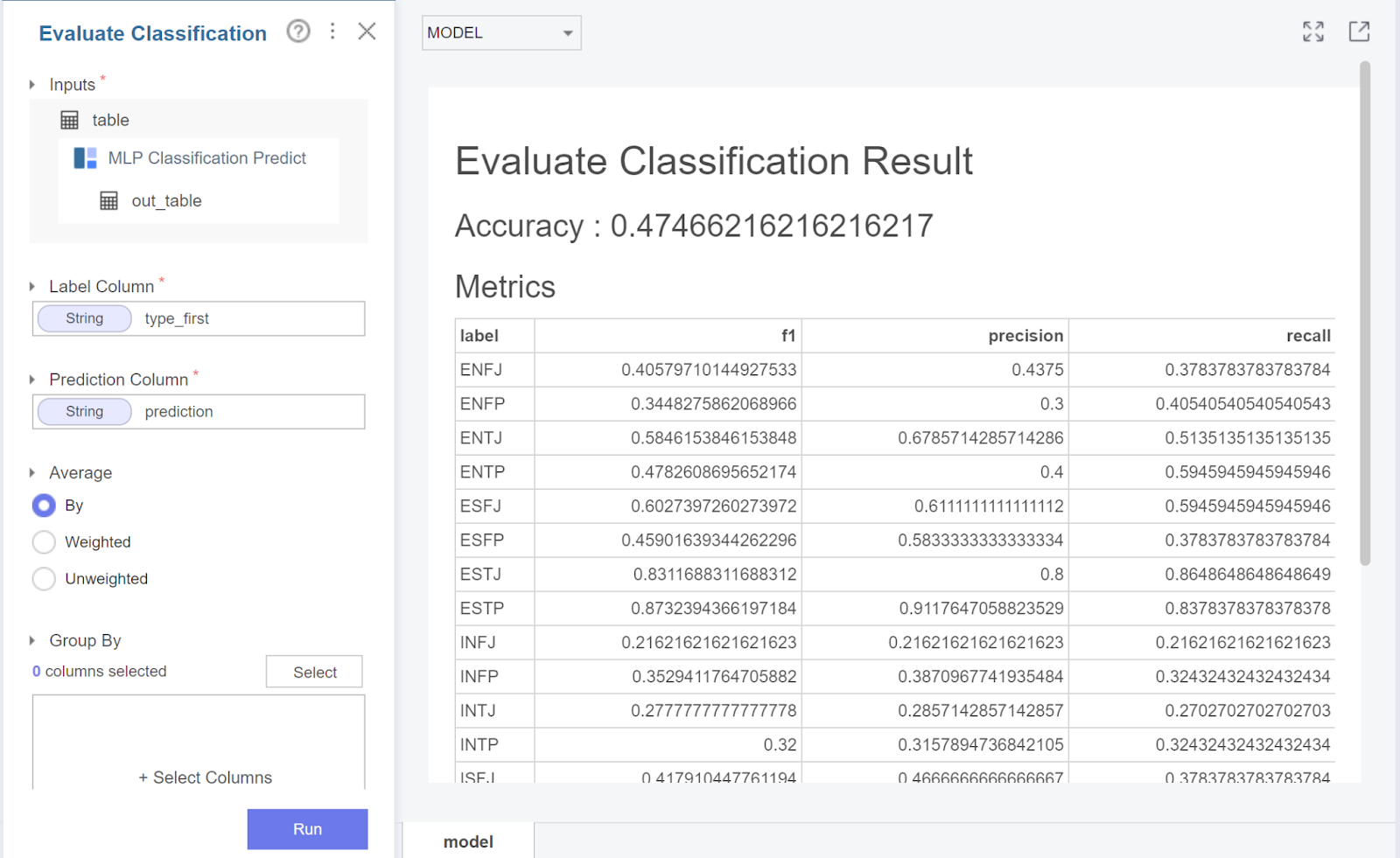
mlp의 결과는 위와 같이 나왔는데요.
adaboost보다는 높지만
머신러닝 기법인 xgboost보다는
못 미치는 결과를 낳았습니다.
label 2개로 변환
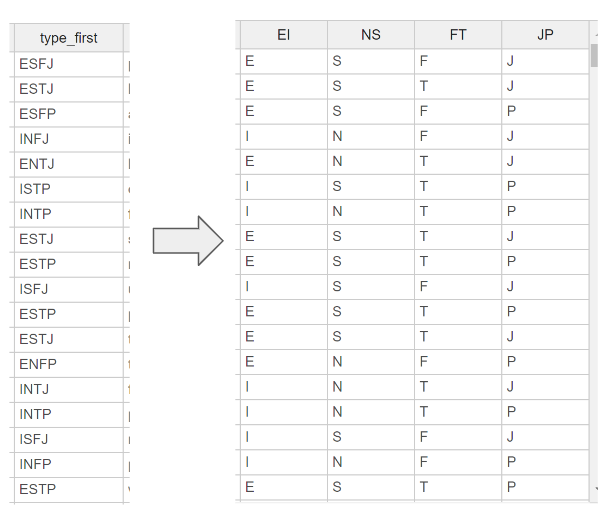
mbti를 보면 16개 말고도
E/I, N/S와 같이 두 가지를 통해서도
유형을 분리하는데요.
저희 팀은 이와 같이 각 2개에 대해서도 실험을 진행했습니다.
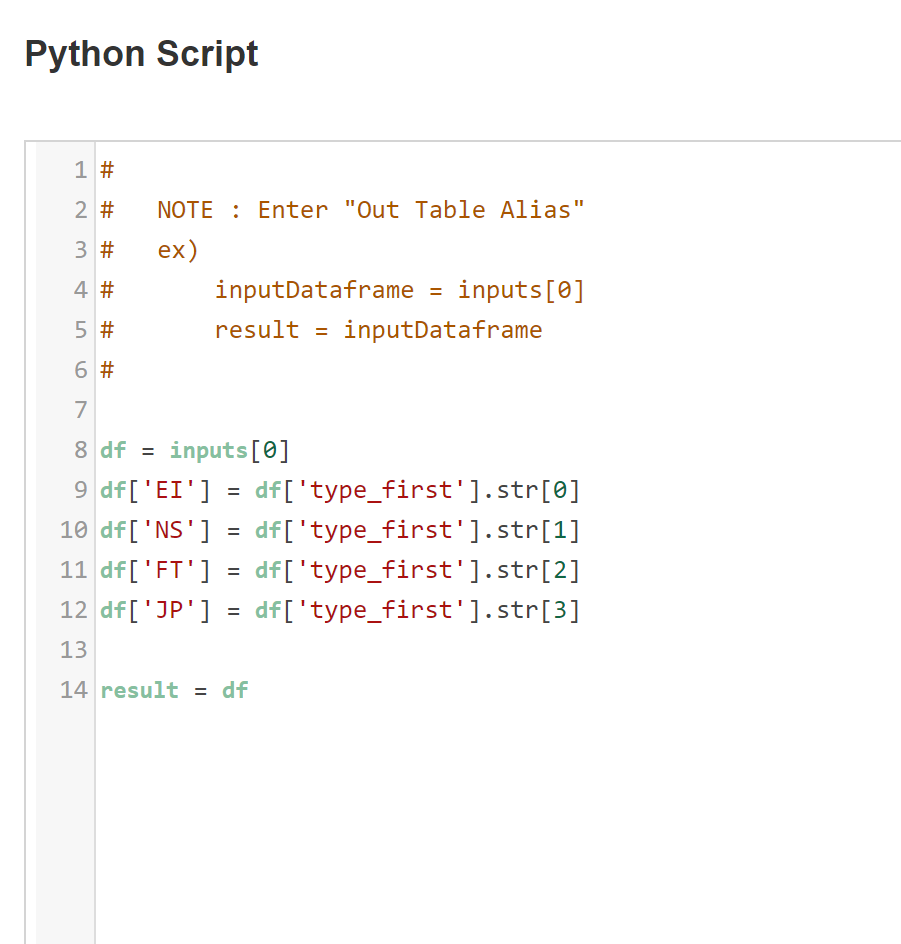
python script함수를 사용하여
각 type을 만들어주고
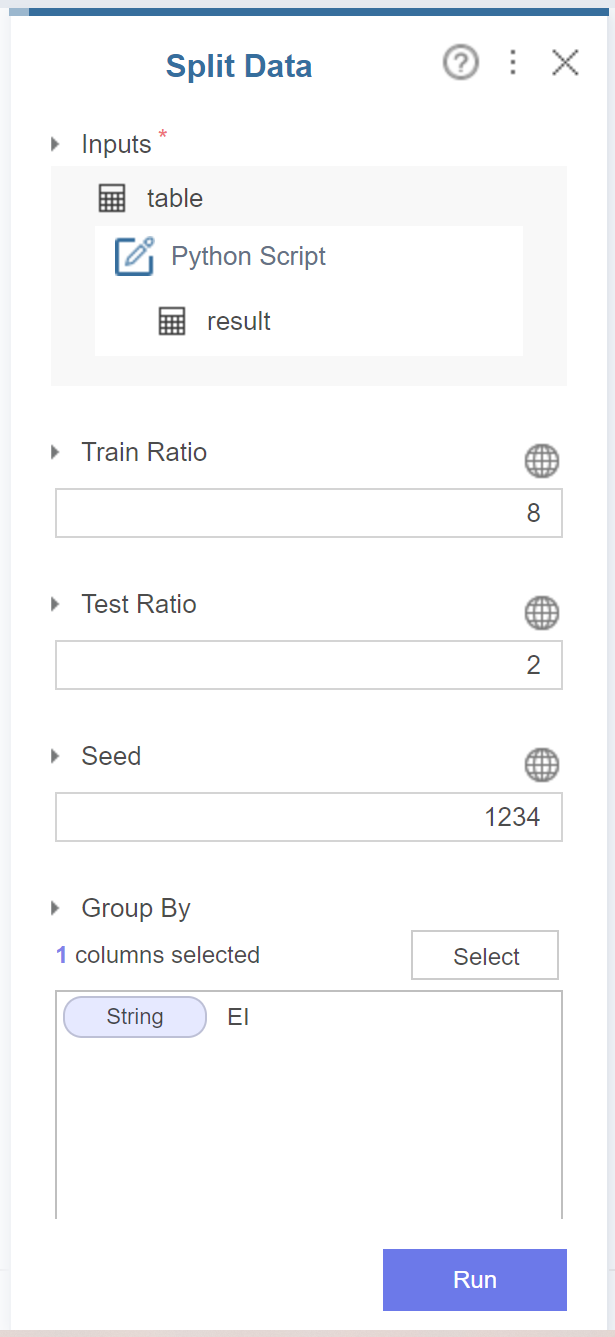
train/test로 split해줍니다.
이 때 데이터를 분할할 때 label비율을 맞춰주기 위해
group by를 분류하고자 하는 class로 해줍니다.
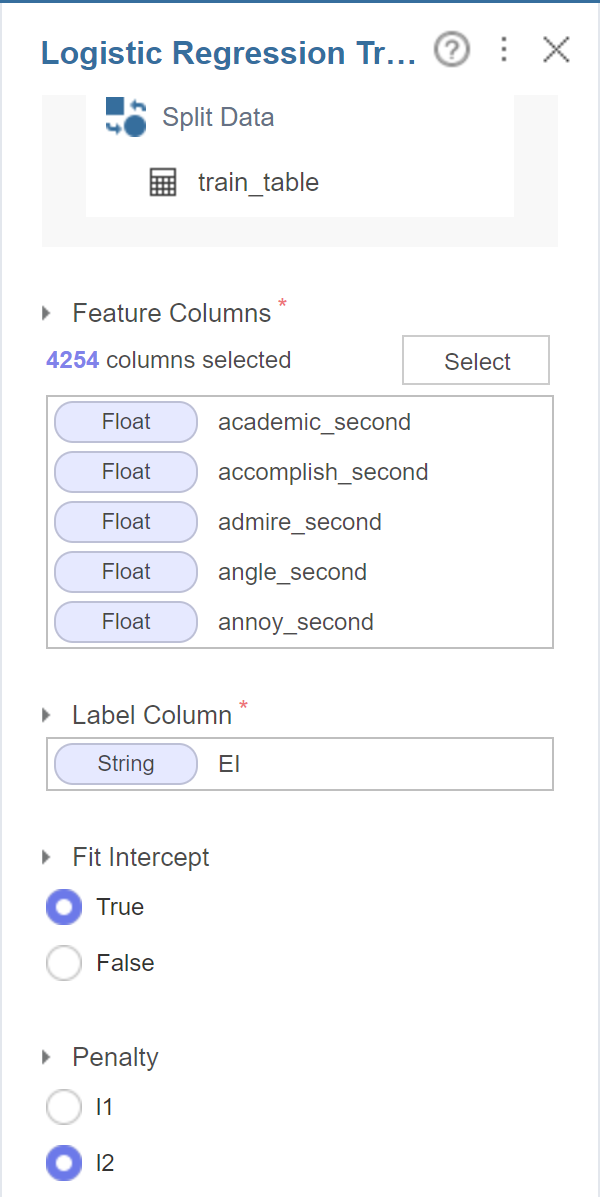
그 후 binary classification에 적합한
logistic regression을 사용하여
분류를 진행해줍니다.
이렇게 총 4개 각각 진행했을 때,
아래와 같이 결과가 나왔는데요.
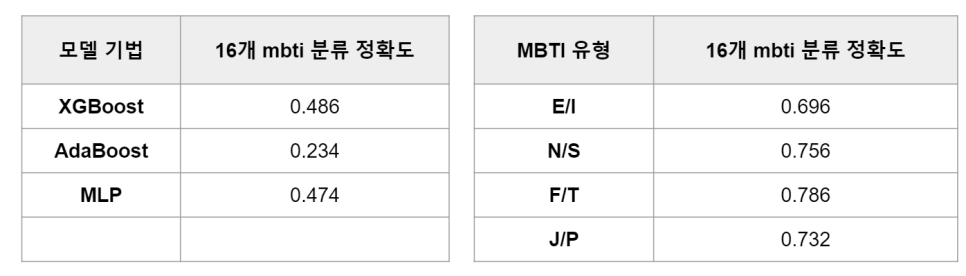
16개에 대해서는 트리기반의 부스팅 기법인
xgboost가 가장 높게 나왔습니다.
이에 대해 해석해봤을 때, 학습시간과 변수의 제한 때문에
차원을 줄여 머신러닝 기법인 xgboost가 높게 나왔고
변수를 늘릴수록 MLP가 높게 나올 것이라고 생각합니다.
그 다음 2개 label에 대해서는
F/T가 가장 높게 나오고 E/I가 가장 낮게 나왔는데요.
이 결과를 해석해보자면
F/T가 쓰는 단어가 포스팅할 때 유의미하게 구분되어져
값이 높게 나오고
E/I는 인터넷상에서 글을 쓸 때는
다른 유형들에 비해 나타나지 않는다고 해석했습니다.
MBTI 시각화
MBTI예측말고도 간단한 시각화를 진행해봤는데요.
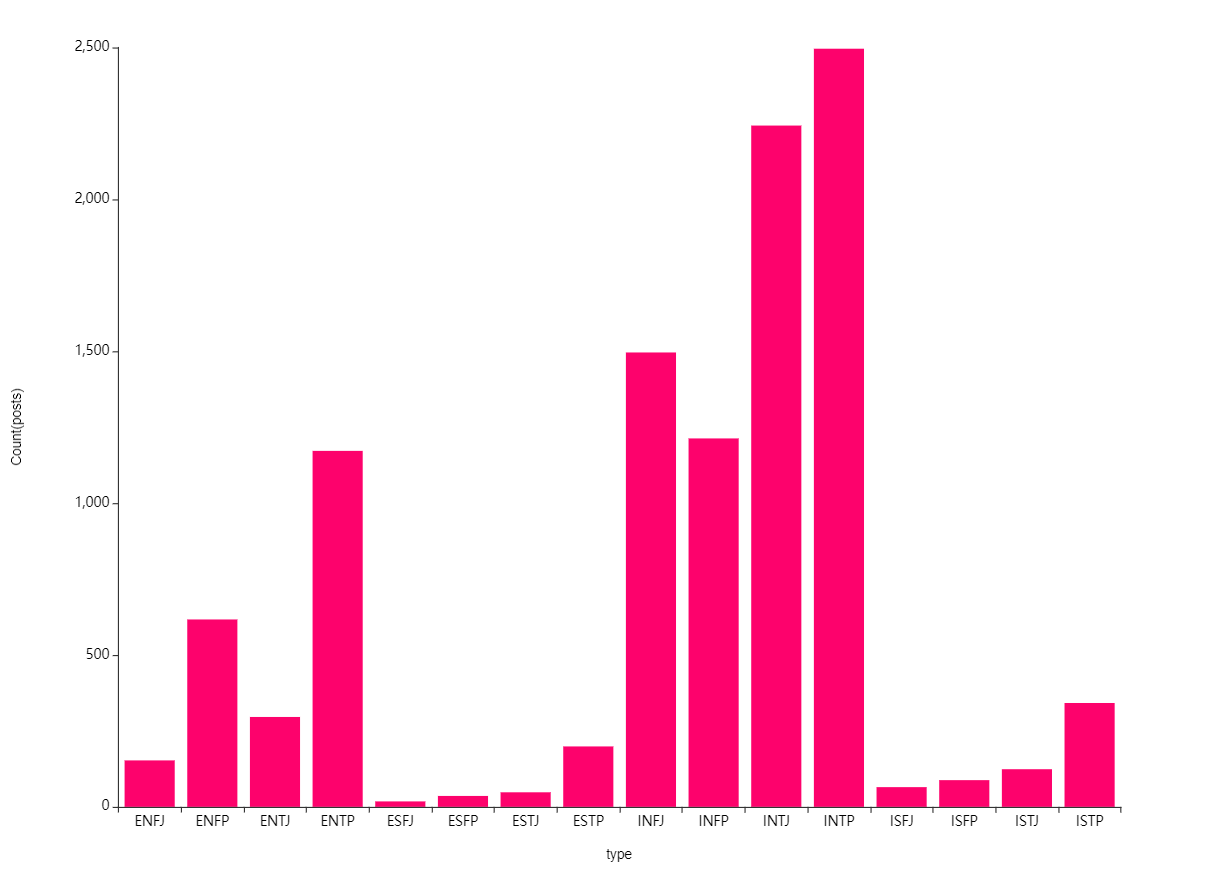
먼저 MBTI별 포스트 개수입니다.
위 막대차트를 봤을 때는
N유형이 압도적으로 글을 많이 쓴다고 볼 수 있고
N이 상상과 직관을 의미하는데
이에 따라 인터넷 상에서 글로 많이 표현하는 것으로
해석을 했습니다.
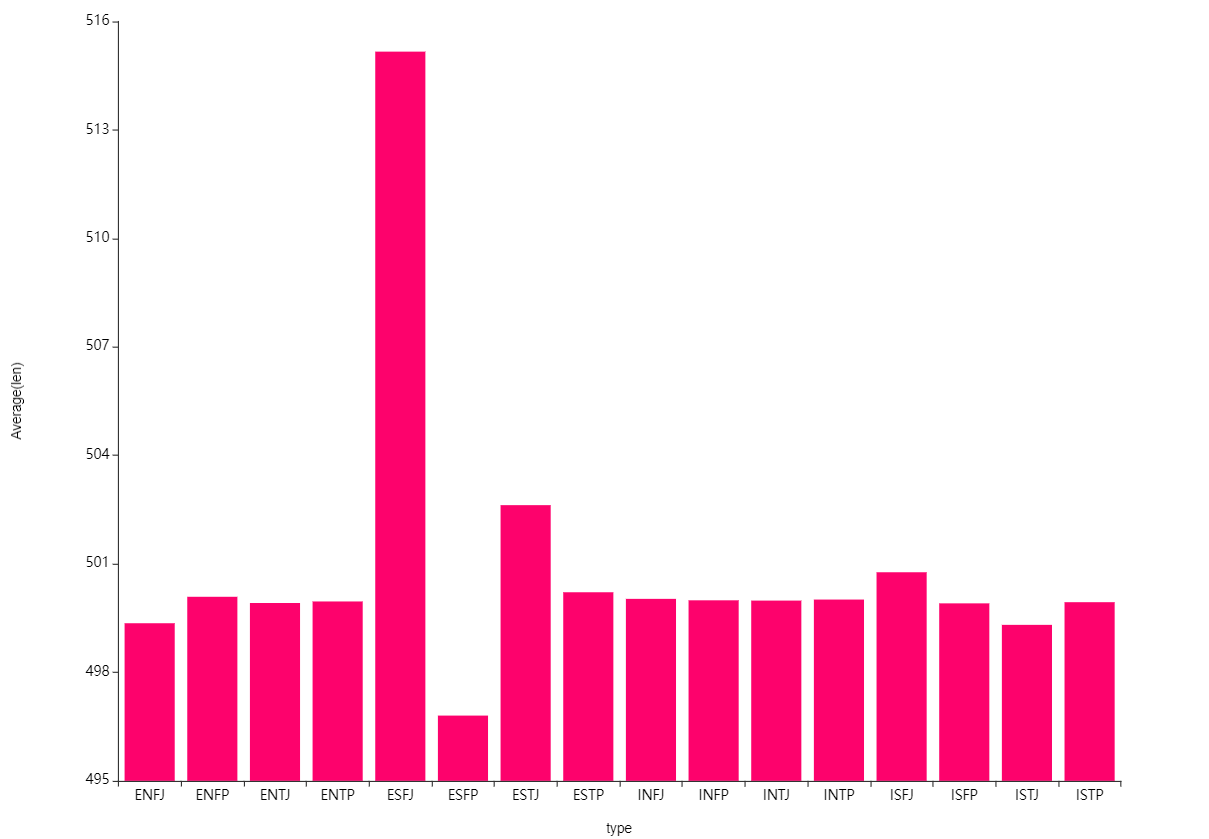
다음은 포스팅 길이입니다.
포스팅 길이는 대부분 비슷한 것을 볼 수 있는데
ESFJ유형이 한 번 쓸 때 길게 쓰는 것을 볼 수 있었습니다.

또한 각각의 MBTI유형마다
많이 나타나는 단어들을 시각화해봤는데요.
E에서는 day, start와 같이 활발한 단어
I는 live, care와 같이 삶에 대한 단어들이 많이 나타났습니다.
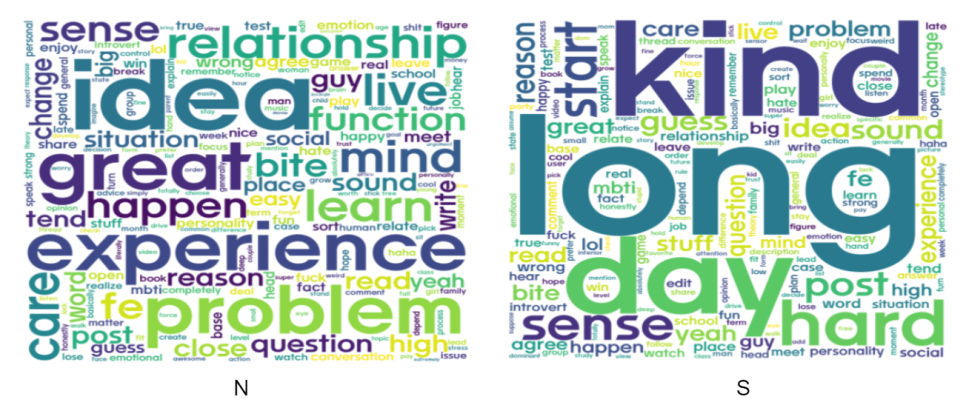
N에서는 idea, mind, learn과 같이 생각을 하는 단어
S는 long, hard, kind와 같이 현실적인 단어들이 나타났습니다.

T에서는 sure, point와 같이 확신과 주장을 하는 단어
F는 probably, kind, maybe와 같이 가정을 하는 단어와 공감 단어가
주로 나타났습니다.

마지막으로 J는 앞에서 나온 단어들이 많이 나왔는데요.
bad, day, sense, experience와 같은 단어
P는 idea, live와 같은 단어들이 나타났습니다.
총정리
MBTI예측하기 뿐만 아니라
저희팀은 국가별 MBTI비율과
reddit 분석도 진행하였는데요.
해당 분석은 다른 팀원의 블로그를 링크로
달아놓겠습니다.
국가별 mbti :
reddit 분석 :
총 3~4주동안 팀원들과
브라이틱스를 사용하여 mbti예측하기
프로젝트를 진행하였는데요.
요즘 가장 핫한 mbti를
어떻게 하면 브라이틱스를 사용하여
재밌게 표현할 수 있을까를
중점적으로 고민해보았고
브라이틱스 내 텍스트마이닝 관련
함수들을 대부분 사용하고자 노력했습니다.
하면서 느낀 건
정말 브라이틱스 기능들이
자동화 시스템이 잘 되어있고
편리하다라는 점인데요.
기존 파이썬이나 R로 분석을 진행하면
구글링도 해야하고
코드도 짜야하고
코드에 맞게 파라미터도 조정해야하는데
브라이틱스 위 모든 기능들을
함수라는 ui로 만들어
버튼만 클릭하면 진행된다는 점이
매우 흥미로웠습니다.
앞으로도 많은 브라이틱스의 기법들을 소개하며
다음주는 영상제작으로 찾아뵙겠습니다.

지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
'삼성 SDS Brightics' 카테고리의 다른 글
| [Brightics Studio] # 팀 미션 - 홍보 영상 제작 02 (MBTI 과몰입 소개팅 촬영 현장) (0) | 2022.09.21 |
|---|---|
| [Brightics Studio] # 팀 미션 - 홍보 영상 제작 01 (MBTI 과몰입 소개팅) (0) | 2022.09.15 |
| [Brightics Studio] # 팀 분석 프로젝트 - 03 분류모델로 MBTI 예측, 텍스트 데이터로 MBTI 예측하기 (0) | 2022.08.30 |
| [Brightics Studio] # 팀 분석 프로젝트 - 02 업무분배 및 주제구체화, 텍스트 데이터로 MBTI 예측하기 (0) | 2022.08.23 |
| [Brightics Studio] # 팀 분석 프로젝트 - 01 기획 및 구상, 텍스트 데이터로 MBTI 예측하기 (0) | 2022.08.17 |

최근댓글