
안녕하세요 저는 브라이틱스 서포터즈 3기
이상민입니다 :)
저번 포스팅에는 변수 생성에 대해
간단히 설명 하였는데요.
이번 포스팅은 Modeling의 전 과정을
EDA부터 변수 생성까지
모두 압축해서 설명하겠습니다!
데이터 탐색
제주 테크노파크 제주도 도로 교통량 예측
앞선 주제는 제주도 도로 교통량 예측이었는데요.
먼저 다운받은 데이터를 브라이틱스의
Load Data 함수를 통해 불러와줍니다.

위와 같이 데이터를 불러와줬습니다!

그리고 위와 같은 여러 변수들이 있었습니다.
저는 target변수인 평균속도에
영향을 줄만한 변수들을 살펴보았는데요.
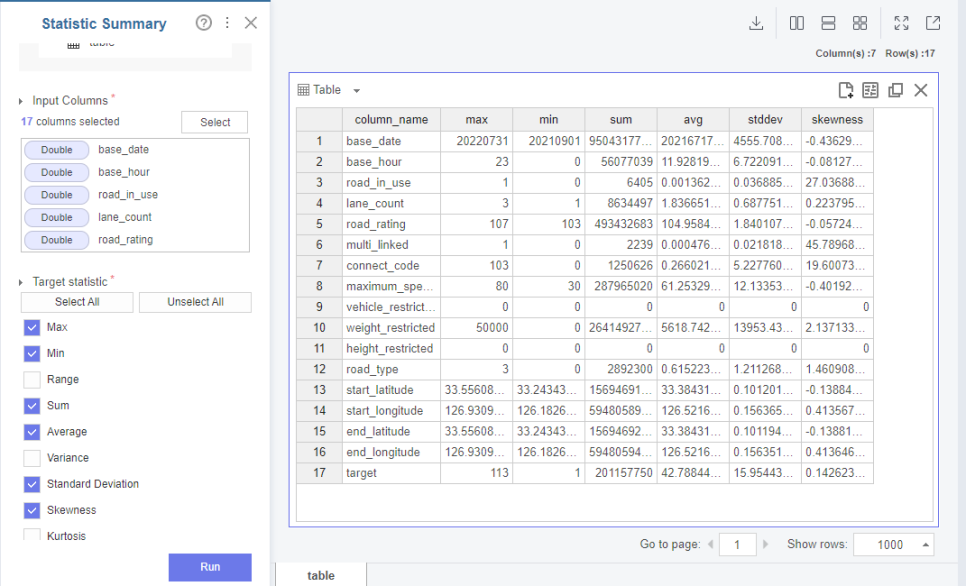
먼저 통계지표를 뽑아보며
0이나 이상치 값들이 있는 것을 볼 수 있습니다.
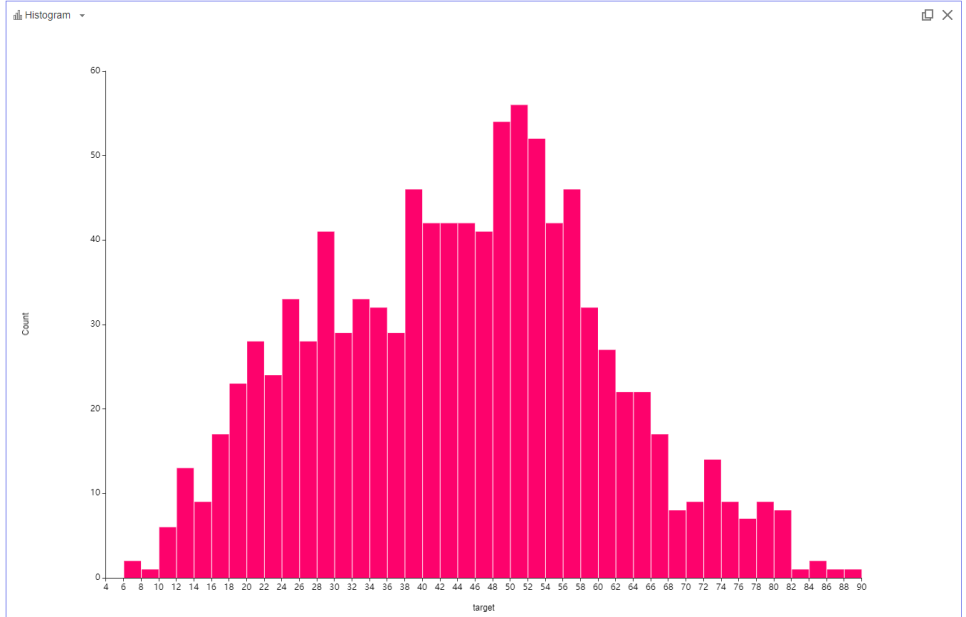
그 다음은 target(평균속도)인데요.
50정도에서 높은 빈도를 가지고 있고
대체로 정규분포를 띄는 것을 볼 수 있습니다.
70이상 구간보다 40이하 구간이 더 많다는 것을 확인할 수 있었습니다.
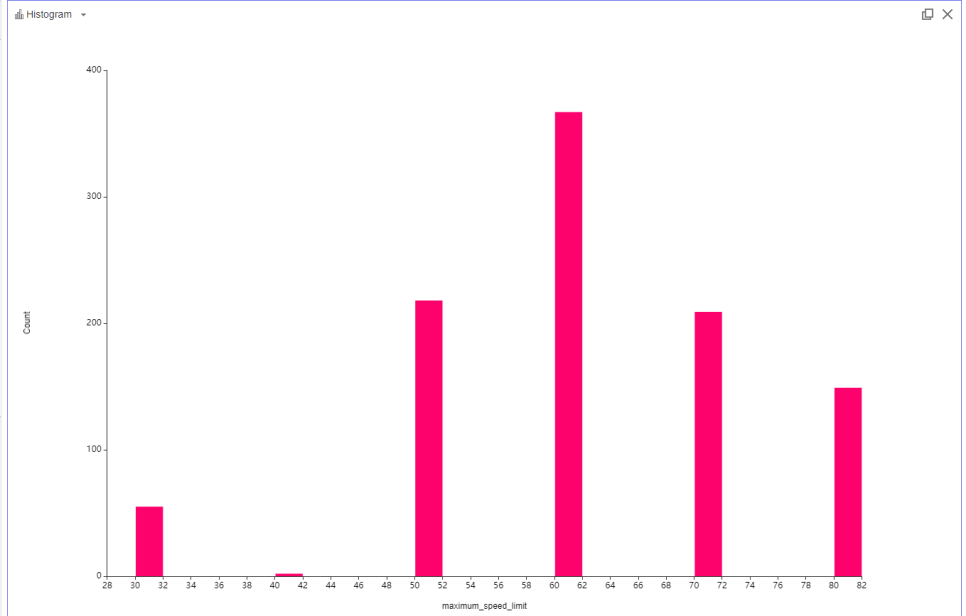
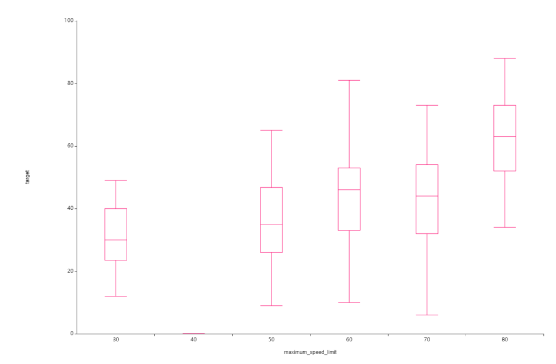
다음 maximum_speed_list(최대제한속도)인데요.
60제한속도가 압도적으로 많고, 40의 제한속도는 매우 희미하게 존재합니다.
40이라는 제한속도가 매우 적어
이를 이상치로 보아 제거해주기로 했습니다.
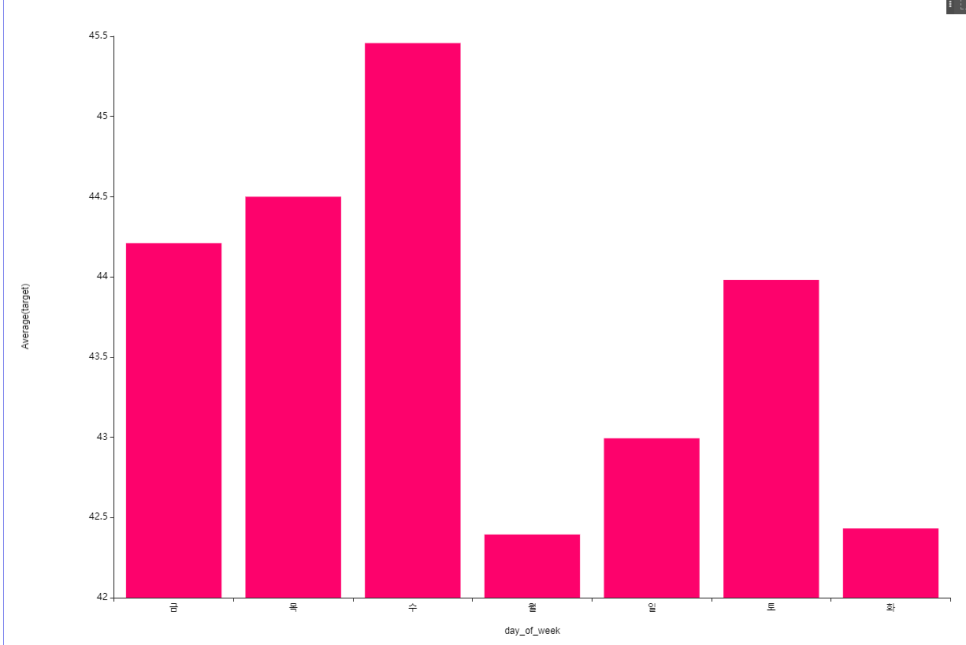
그 다음은 요일별 평균주행속도를 살펴봤을 때,
월요일이 대체로 적고 수요일이 높은 것을 볼 수 있습니다.

다음 시간대별 평균 주행속도입니다.
대체로 23~6(새벽)이 오전, 오후보다 주행속도가
긴 것을 볼 수 있습니다.
이렇게 시간대와 요일별로
평균 주행속도가 유의미하게 다르다는 것을 파악했습니다.
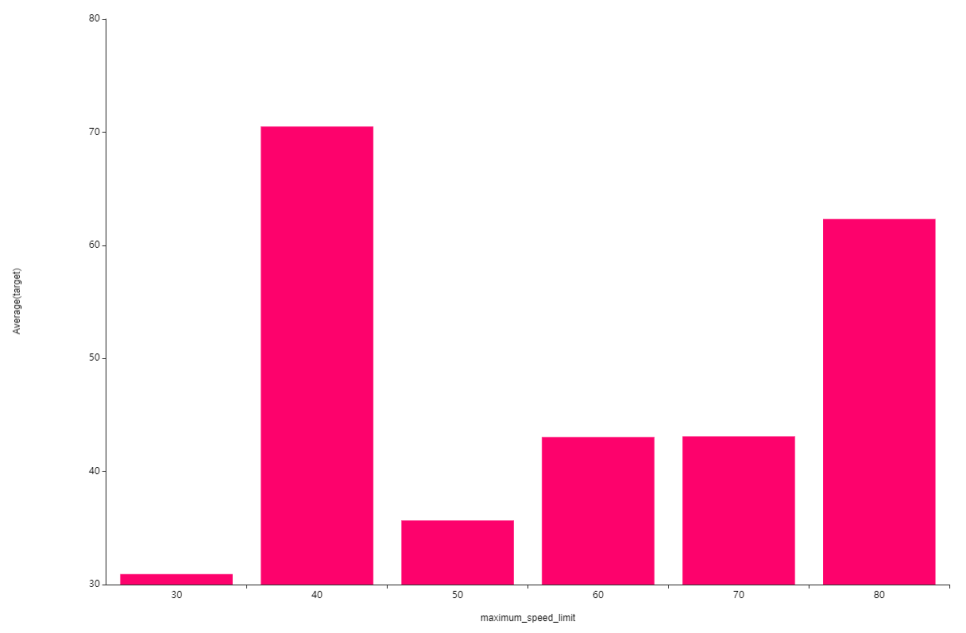
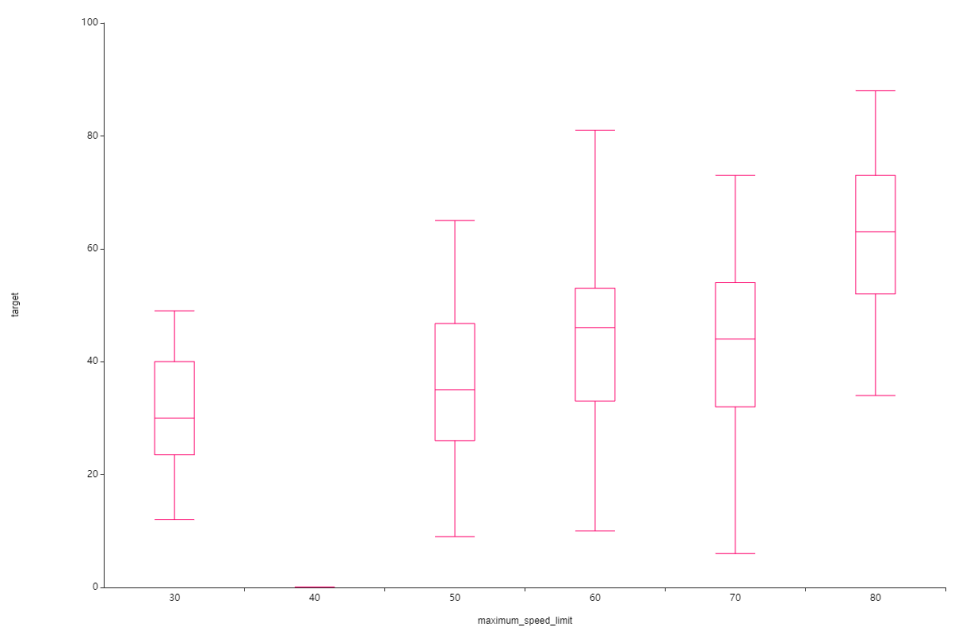
다음은 제한속도별 평균주행속도인데요.
제한속도가 클수록 평균주행속도가 낮은 것을 볼 수 있고
40에서 값이 매우 큰데
이는 앞에서 40변수의 값이 매우 적어
이상치로 값이 튄 것으로 파악됩니다.
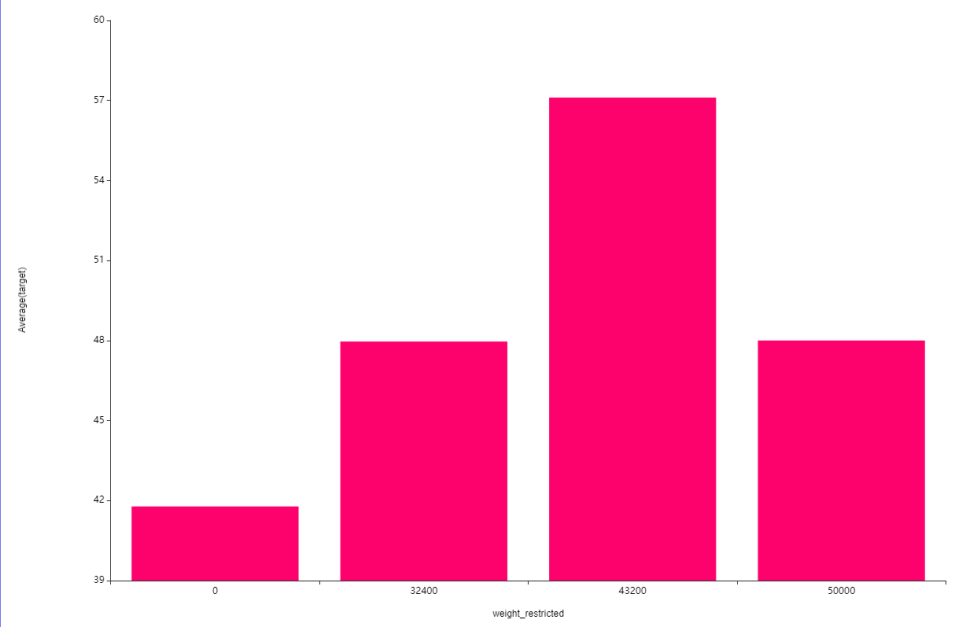
다음은 무게 제한별 평균주행속도인데요.
4xxxx에서 평균주행속도가 가장 큰 것을 볼 수 있습니다.
해당 차 유형의 속도가 어떤 특징을 가지고
운행하고 있을수도 있다고 생각됩니다.
이렇게 제한속도와 무게 제한별 평균 주행속도가 달라
이를 구간화시키고자 했습니다.
Feature Engineering
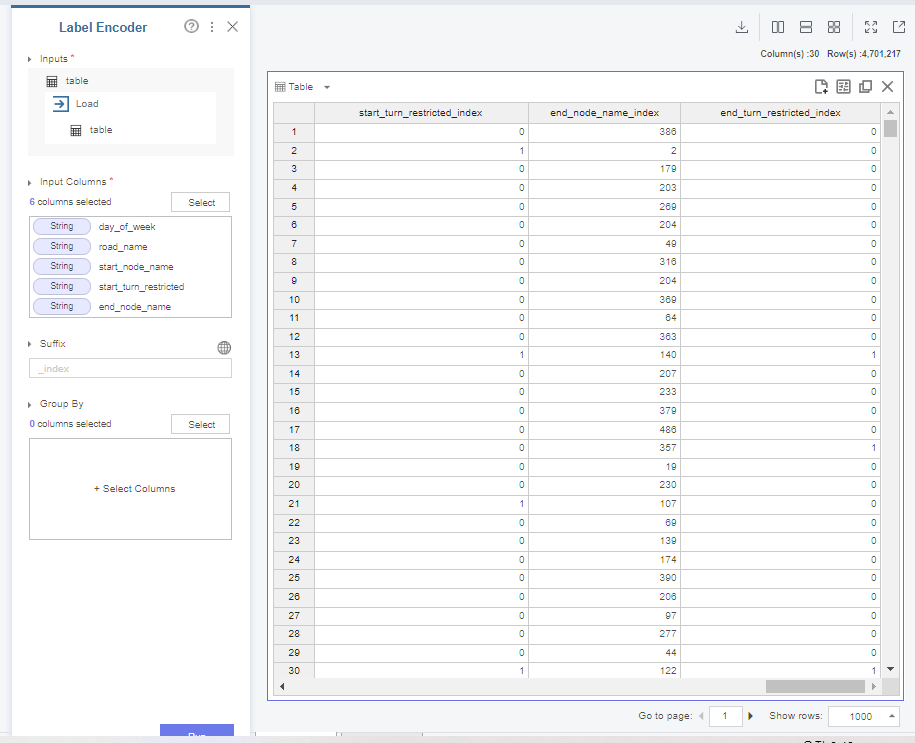
위 사진처럼 명목형 변수를 입력받아
숫자로 변형해주는 과정을 거칩니다.
사실 label encoding의 단점으로는
0,1과 같이 숫자로 변형해버리면
컴퓨터는 1이라는 숫자에 더 큰 가중치를 부여해버리는
문제점이 생기는데요.
이를 해결하고자 나온 것이 one-hot encoding이고
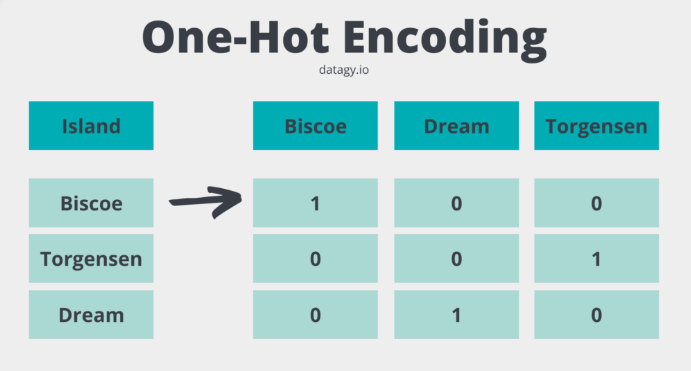
출처 : https://datagy.io/sklearn-one-hot-encode/
위 사진과 같이
값이 큰 변수에 더 큰 가중치를 부여하지 않도록
label마다 column을 새로 생성하여
해당 label에만 1을 부여하는 것을 뜻합니다.
이 기법은 서열이 없는 명목형 변수를
동등한 위치로 처리해주는 효과를 가지게 됩니다.
one-hot encoding이 브라이틱스 상에서
연산량 폭발로 처리를 하지 못해서
python에서 대신 처리해줬습니다.
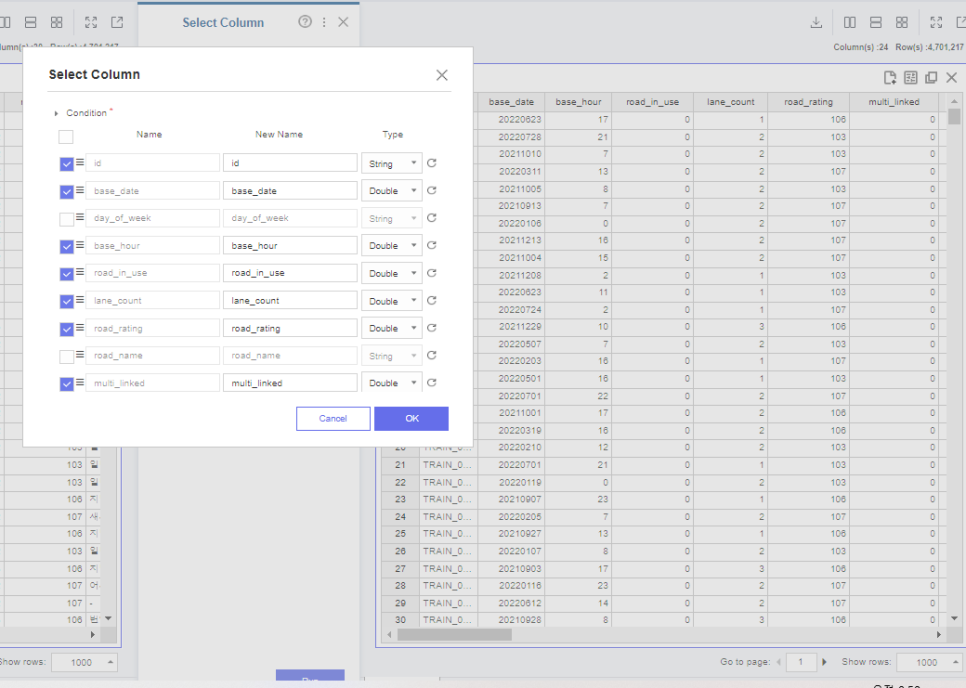
그 다음 기존 명목형 변수는 제외하고
새롭게 처리한 변수들을 추가해서 데이터로 가져옵니다.
그리고 저번 EDA때
최대속도제한이라는 변수에서
40이라는 값의 이상치를 발견했었죠
이는 target값에 노이즈가 낀다고 판단하여
제거해주고자 했습니다.
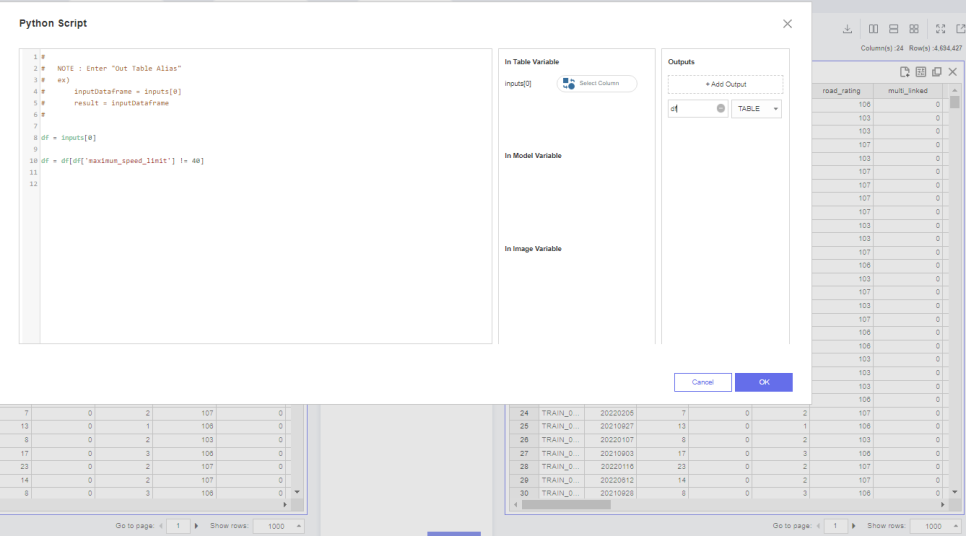
해당 방법은 python script를 사용했고
40이라는 값을 제외한 데이터만 가져오는 형식으로
처리해줬습니다.
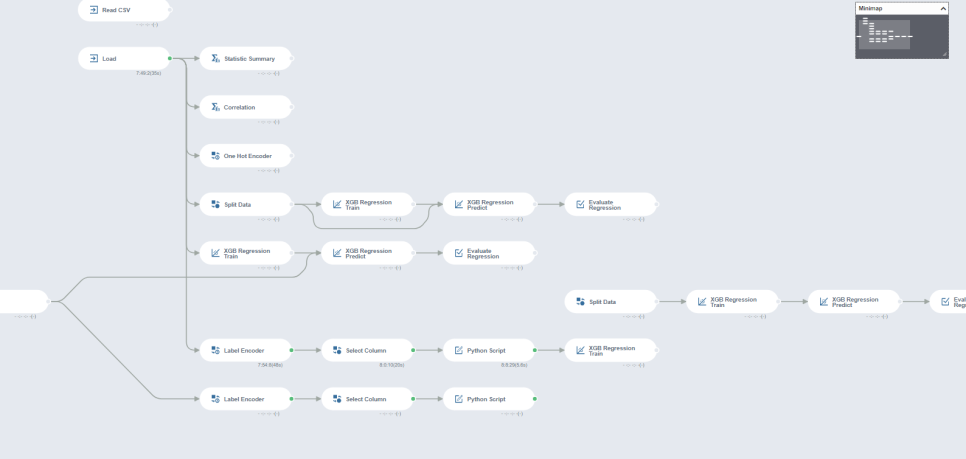
전처리 과정을 모두 거친
브라이틱스 작동화면입니다!
Modeling
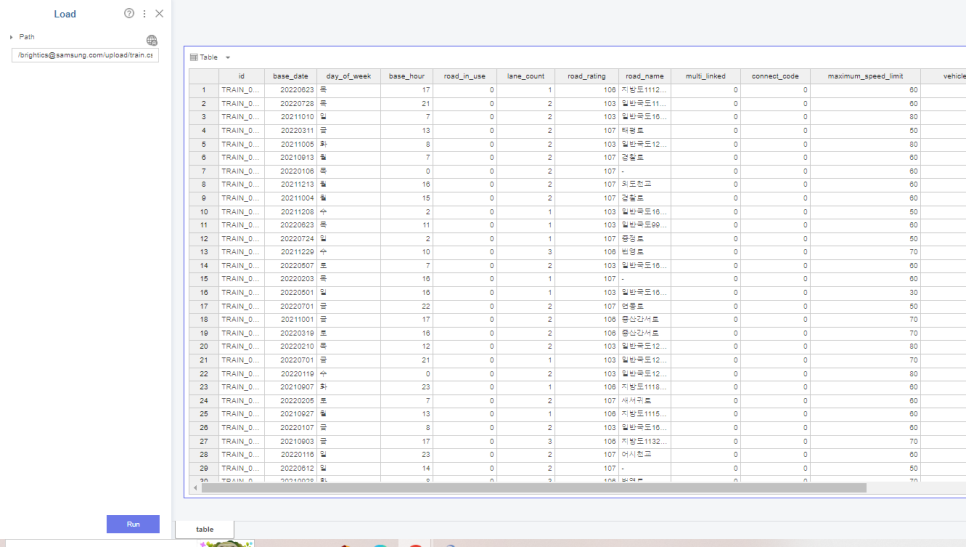
먼저 저번 포스팅때처럼
data를 load해줍니다!
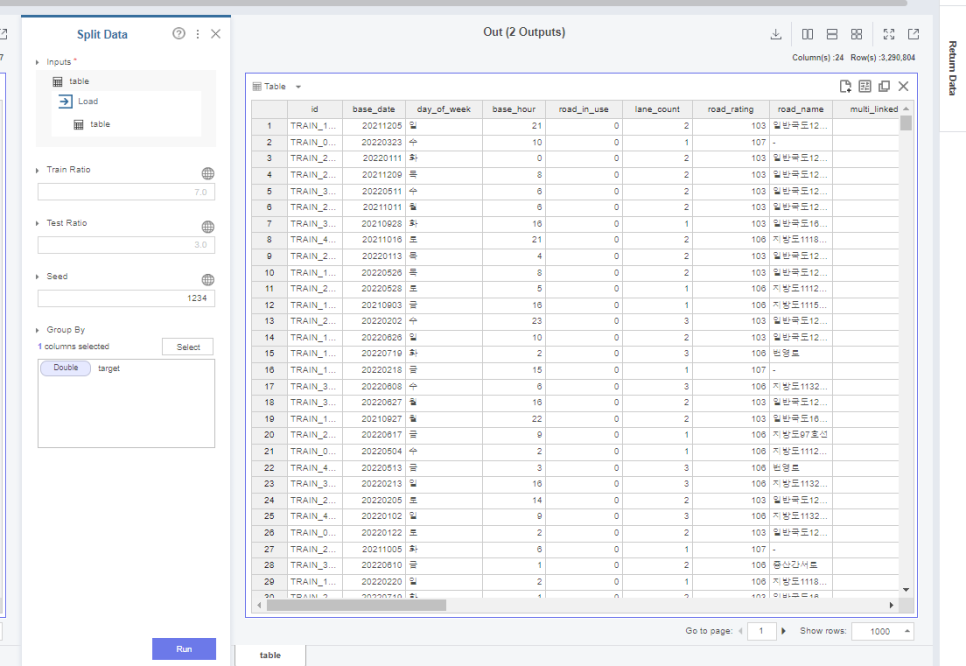
그 다음은 split data 함수를 통해
데이터를 train과 test로 분리해줍니다.
여기서 seed를 고정해주는데요.
이는 추후 실험을 반복할 때,
똑같은 데이터셋으로
성능적인 면의 변화를 보기 위해
고정해줘야 합니다.
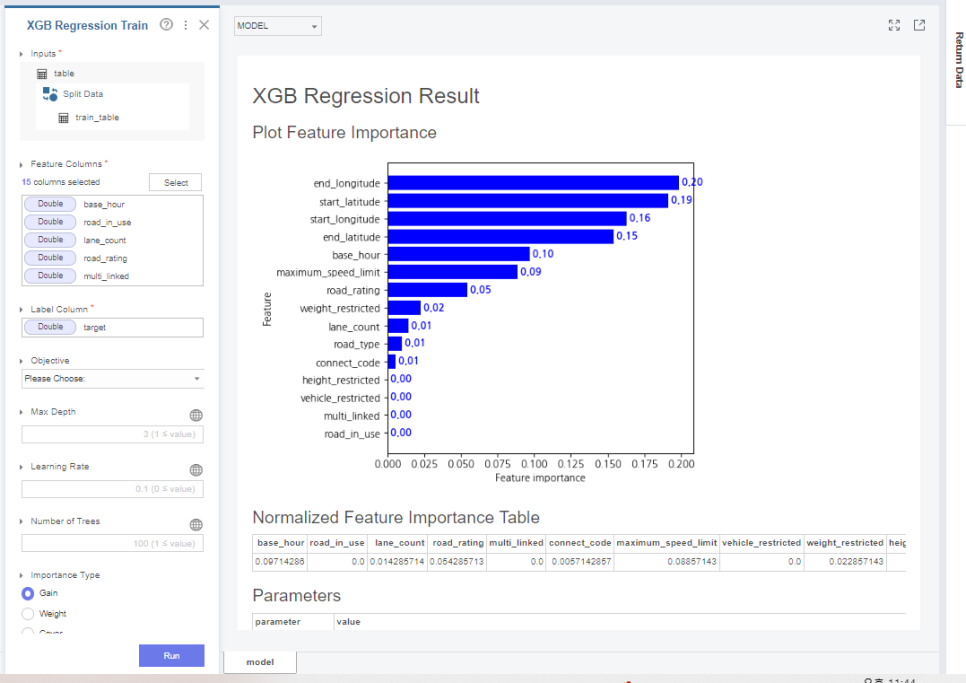
그 후 xgboost regression함수를 통해
train data를 학습해줍니다.
여기서 변수는 numerical한 변수만 사용해줬는데요.
baseline model이기 때문에
categorical한 변수는 사용하지 않았습니다.
추후 encoding과정을 통해 변환한 후,
데이터셋에 붙인 다음
categorical한 변수만 사용했을 때 비해
얼마나 성능향상이 이뤄졌는지 확인해보려고 합니다.
추가적으로 하이퍼 파라미터도
기본값으로 설정해줍니다.
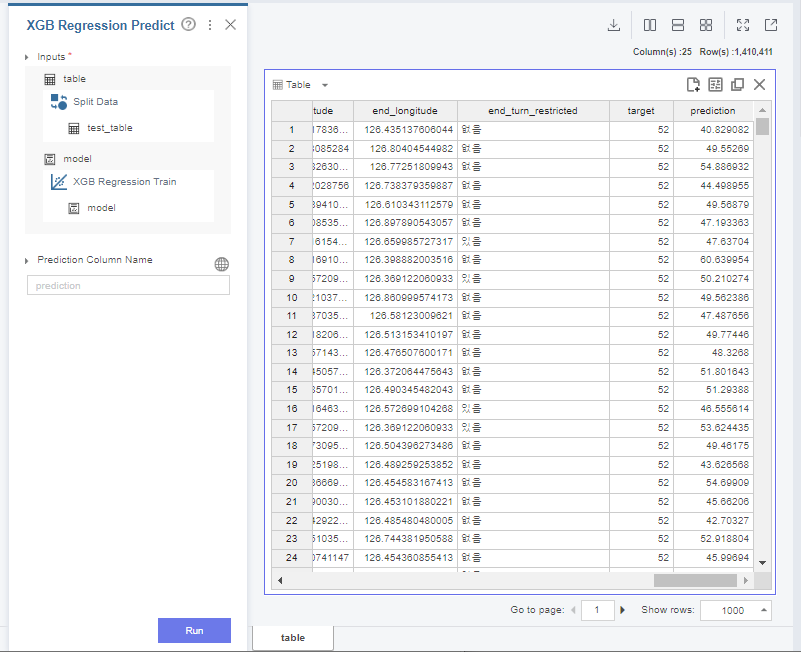
그 다음 predict 함수를 통해
test data를 예측해줍니다.
이 때 사용한 model은
train data로 학습한 xgb regression 모델입니다.
데이터를 보시면
predict라는 변수가 생성된 것을 볼 수 있는데,
이는 바로 predict에서 예측한 값입니다.
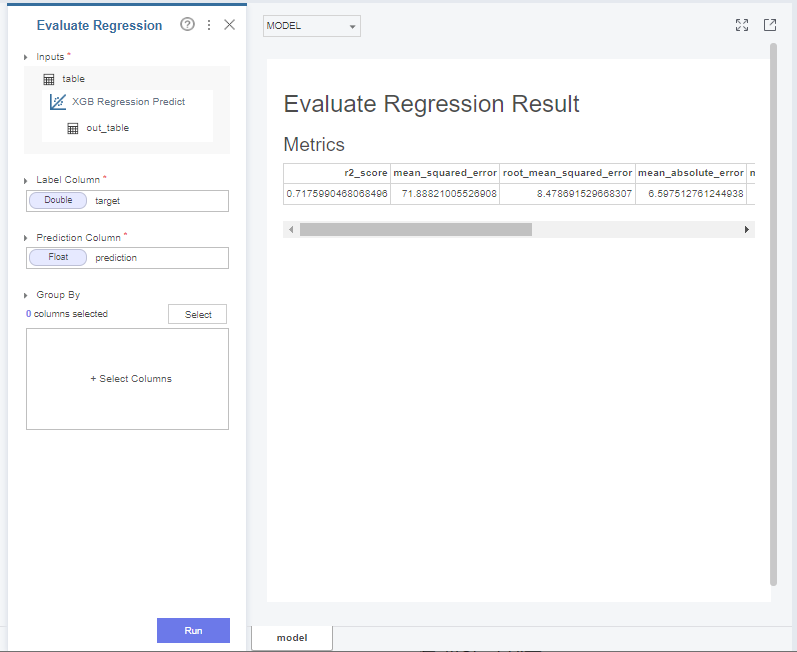
마지막으로 모델이 제대로 평가를 진행했는지
확인하기 위해 evaluation을 해줘야하는데요.
브라이틱스에는 regression, classification 태스크에 맞게
자동적으로 평가지표를 측정해줍니다.
label과 prediction column만 올바르게 부착만 해주면
되기 때문에 매우 편리한 함수입니다!
test 데이터 검증 진행
이렇게 학습과정을 거치고
실제 test데이터를 바탕으로 평가를 진행해봐야 되겠죠?

도로교통량의 test데이터를 불러오고,
이번에는 data를 나누지 않고
full data로 학습을 진행해줍니다.
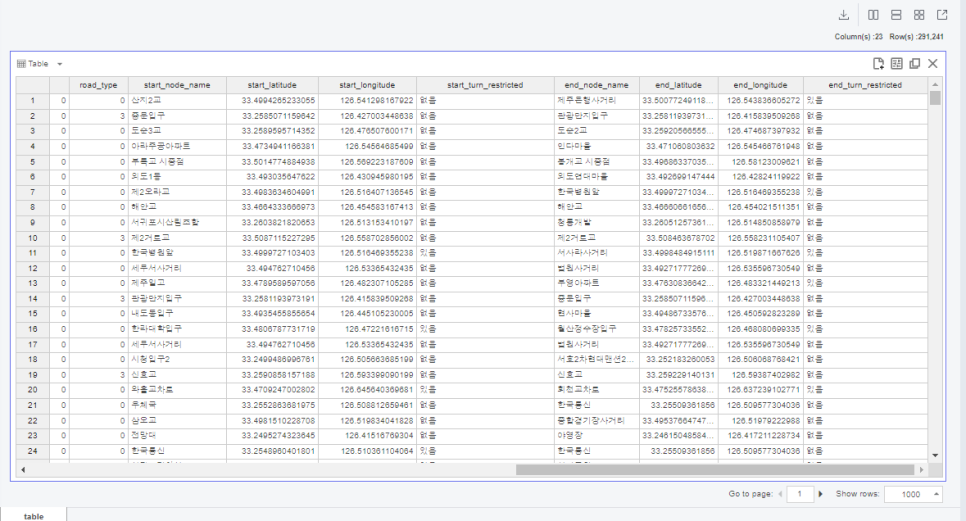
test 데이터는 위와 같은데요.
말 그대로 검증을 위한 데이터이니
label인 target변수가 없는 것을 볼 수 있습니다.
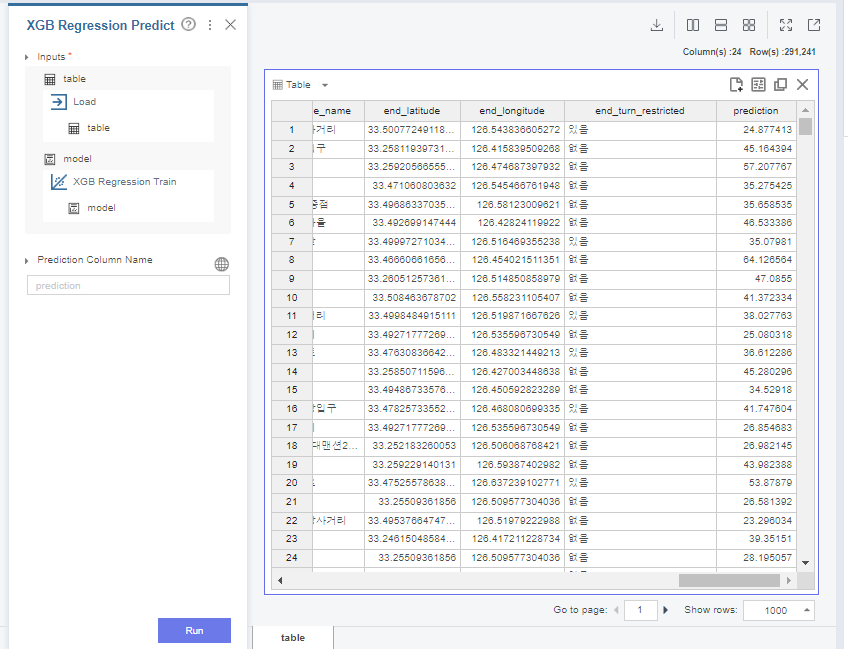
train인 full data로
학습을 다시 진행해주고,
test data로 prediction을 진행하여
label을 부착해줍니다.
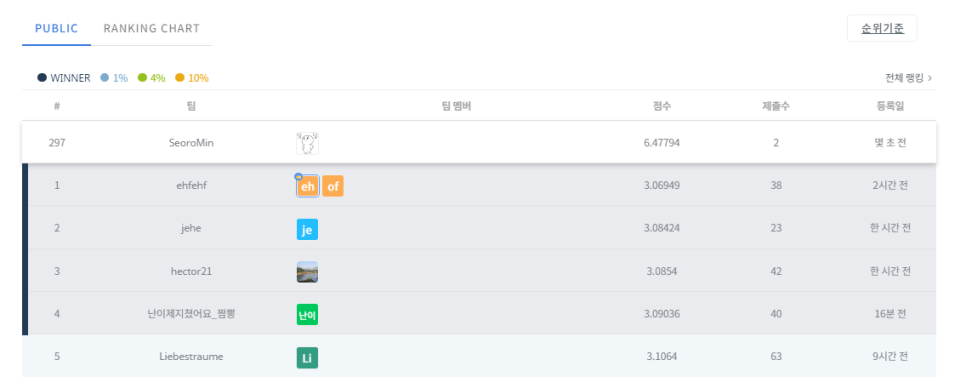
부착해주고 나서 csv형태로 dacon에 제출했습니다!
정리
많은 데이터분석가와
분석가를 꿈꾸는 분들이
dacon을 자주 이용하시는데요.
브라이틱스를 활용해서도
좋은 모델을 구현할 수 있다는 점을
보여주고 싶었습니다.
수많은 분석과 모델링을 진행할 때
코드 없이 편리하게 사용할 수 있는
브라이틱스를 다들 활용해보세요 :)

지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.

최근댓글