2차원 Convolution의 문제점
- contextual information을 확보하기 위해 넓은 Receptive field를 고려할 필요가 있음.
- CNN에서는 이를 확장하기 위해 커널 크기를 키우거나 layer를 쌓는데, 이는 연산량을 매우 크게 증가시킴.
-> 해당 문제점인 연산량을 경량화, 정보 손실이 일어나지 않게 유의미한 정보만을 추출하기 위해 다양한 기법이 나타남.
1. Dilated Convolutions (= astrous Conv)
- 기존 Conv filter가 수용하는 pixel 사이에 간격을 둔 형태 (간격을 조절하면서 다양한 scale 대응 가능)
- 입력 pixel 수는 동일하지만, 더 넓은 범위에 대한 입력 수용
- dilation rate 파라미터 : 커널 사이 간격 정의 (d.r가 2이면 3x3커널은 9개 파라미터 사용. 5x5커널은 동일 view)
- real-time segmentation이나 object detection같은 contextual information이 중요한 분야에 적용 유리 (넓은 view 필요, receptice field를 늘리는 방법)
- 필터 내부에 zero padding을 추가해서 강제로 receptice field를 늘리게 됨. -> 위 그림에서 진한 파란색 부분만 weight 존재. 나머지 부분은 0으로 채워짐
- receptice field는 필터가 한 번 보는 영역으로 사진의 feature를 파악하고, 추출하기 위해서는 넓은 receptice field를 사용하는 것이 좋음. -> why? : dimension 손실이 적고, 대부분 weight가 0이기 때문에 연산 효율이 좋음.

- pooling - Conv - upsampling의 기존 과정은 해상도가 떨어짐. dilated conv를 통해 receptice field를 크게 가져가서 정보 손실을 최소화해서 해상도 큰 output을 얻음.
2. Transposed Convolution

- vs Deconvolution : convolution 과정을 되돌리는 작업.
- Transposed convolution과 deconvolutional layer와 동일한 공간 해상도 생성. (실제 수행되는 수학 연산은 다름. transposed는 정기적인 convolution을 수행하며 공간 변환 수행)

- 일반적인 2D convolution의 연산 과정은 (kernel에 대응되는 sparse matrix) X (transpose된 matrix) -> 16x1 matrix 생성
- 압축된 정보를 또 다른 과정을 통해 up-samping하여 복원

- 기존 sparse matrix를 활용하여 4x1압축이 아닌, 16x1로 up-samping하여 복원
- CNN Encoder-Decoder구조의 Autoencoder에서 사용
- Encoder에서 pooling 등 이미지 축소, 데이터 압축 -> 다시 원래 이미지로 복원하기 위한 up-samping과정에서 transposed convolution 사용 (Super resolution에서도 사용)
- "보간"이라는 Bilinear Upsamping기법도 이미지 크기 복원에서 사용
3. Separable Convolution

- 커널 작업을 여러 단계로 나누는 Conv
- Conv 연산 y=conv(x,k) , k=k1.dot(k2) --> K와 2D Conv을 수행하는 대신 k1과 k2로 1D Conv 하는 것과 동일한 결과
- 커널은 두 개의 작은 커널로 나눈 뒤, 원래 커널로 작업한 결과물과 동일한 효과 (9번 연산 = 각 3번*2) -> 곱셈 연산이 적을수록 계산 복잡성이 줄어들고, 네트워크 실행속도 향상
- 대표적인 Conv연산으로 image processing에서 sobel mask가 있는데, 모든 커널을 두 개의 작은 커널로 분리할 수 없다는 문제가 있음.
4. Depthwise Convolution
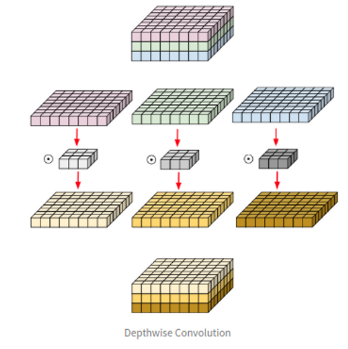
- 일반적인 Conv 필터는 입력 영상의 모든 채널에 영향을 받아, 특정 채널만의 Spatial Feature를 완벽히 추출하는 것은 불가능함. (즉, 다른 채널의 정보가 관여하는 것이 불가피함)
- 이를 해결하고자 Depthwise Conv은 각 단일 채널에 대해서만 수행되는 필터들 사용(MobileNet 구조가 Depthwise Conv을 택하여 연산량을 줄여, 실시간으로 동작 가능하도록 함)
- 8x8x3 matrix -> 채널별 분리 -> 3x3 커널은 8x8 matrix랑 Conv 진행 -> 다시 합침
- 채널 방향의 Conv는 진행하지 않고, 공간 방향의 Conv만 진행
- 각 커널들은 하나의 채널에 대해서만 파라미터를 가짐 -> 입력 및 출력 채널의 수가 동일, 각 채널 고유의 Spatial정보(파라미터)만 사용하여 필터 학습.
- 결과적으로 입력 채널 수만큼 그룹을 나눈 Grouped Conv와 같아짐.
5. Depthwise Separable Convolution
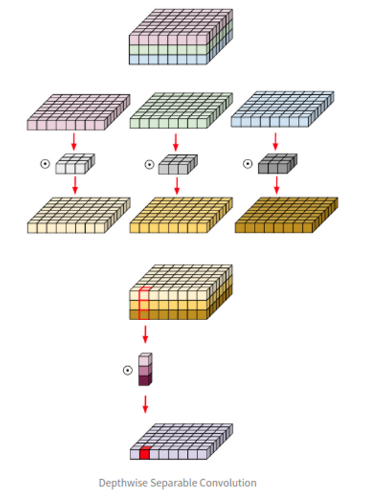
- Depthwise Conv랑 다르게 채널의 출력 값이 하나로 합쳐지는 특징을 가지고 있음. (각 채널을 1개의 채널로 압축하는 추가적인 Conv진행)
- Spatial Feature(공간 특징), Channel-wise Feature(채널 혼합)를 모두 고려하여 네트워크 경량화
6. Pointwise Convolution
- 기존 Depthwise/Sepearable Conv는 각각 공간/채널 방향의 컨볼루션 진행 여부로 나뉨.
- Pointwise Conv는 공간방향 Conv X, 채널방향 Conv만 사용하여 Channel Reduction시에 주로 사용
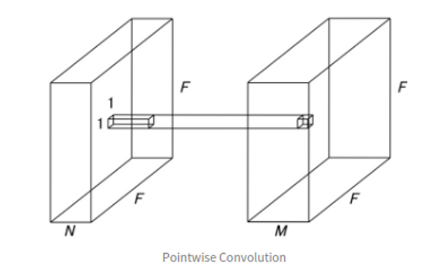
- 커널 크기가 1x1로 고정된 Conv layer -> 입력 영상에 대한 Spatial Feature는 추출 x, 각 채널들에 대한 연산만 수행 (channel만큼 depth가 이루어진 1x1xC layer이기 때문)
- 입력 특징을 1개의 채널로 압축시키는 효과(하나의 필터는 채널 별로 Coefficient를 가지는 Linear Combination을 표현)
- 채널 단위의 linear combination을 통한 채널 수의 변화가 가능하다는 것을 뜻함. (다채널 입력 영상을 더 적은 채널 영상으로 embedding하는 것. 출력 채널 수를 줄임으로써, 계산량과 파라미터를 줄일 수 있음)
- 채널에 대한 Linear Combination을 수행할 시, 불필요한 채널들이 낮은 Coefficient를 가지며 연산 결과에서 희석될 수 있음
- 입력 채널을 압축시키기에 연산 속도가 대폭 향상된다는 장점, but 데이터가 압축되면서 소실되어버리는 문제(속도와 정보손실의 trade-off 존재)
- 해당 기법은 Inception/Xception/SqueezeNet/MobileNet에 적용되어 경량화, 성능 개선이 가능함이 실험적으로 증명됨.
7. Grouped Convolution
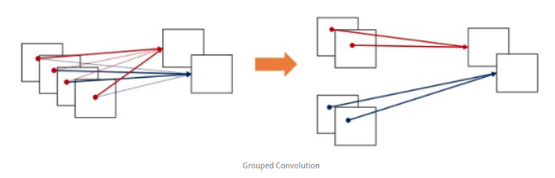
- 입력 값의 채널들을 여러 개의 그룹으로 나누어, 독립적으로 Conv 연산 수행 (병렬 처리 유리)
- 기존 2D Conv보다 낮은 파라미터 수, 연산량을 가지며 각 그룹에 높은 correlation을 가지는 채널이 학습될 수 있다는 장점.
- 각 그룹마다 독립적인 필터의 학습 기대(그룹 수를 조정해 필터 그룹 조정 가능)
- 그룹 수와 파라미터 수는 반비례, 그룹 수가 증가할수록 성능 향상
- 너무 많은 그룹으로 분할하면 성능이 하락될수도 있다.
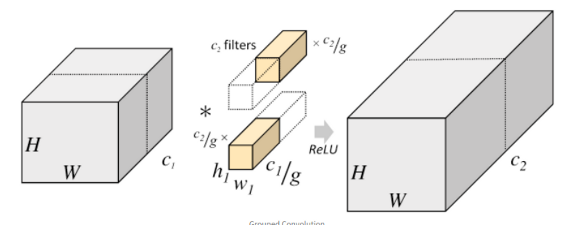
- Grouped Conv 파라미터 수 : 각 그룹 당 채널 수는 C/g
- 총 연산량 : (K*K*C*M*H*W)/g
8. Deformable Convolution
- 변형 가능한 CNN (기존 CNN은 Conv->pooling->roi pooling 등 일정한 패턴 가정. 복잡한 transformation에 유연한 대처 어려움)
- CNN에서 사용하는 Receptice Field의 크기는 항상 같고, object detection에 사용하는 feature를 얻기 위해 사람의 작업 필요
- 기존 논문들은 weight를 구하는 방법에 초점, 이 기법은 어떤 데이터 x를 뽑을 것인지에 초점
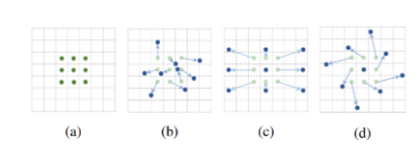
- Conv에서 사용하는 sampling grid에 2D offset를 더하는 것
- (a)가 일반적인 conv의 sampling grid라면 b,c,d처럼 다양한 패턴으로 변형(스케일, 종횡비, 회전)
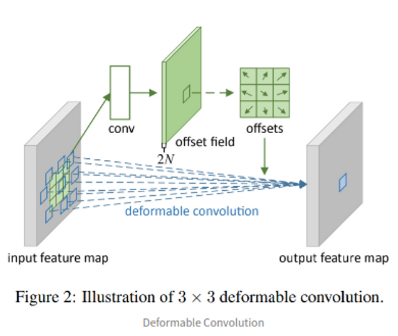
- 3X3 deformable Conv 예시 : 기존 conv layer이외에도 초록색 그림의 conv가 더 존재 -> 각 입력의 2D offset를 학습하기 위한 것.
- 실제 offset 계산은 linear interpolation으로 이루어짐(2차원은 bilinear interpolation = 거리 비를 사용하여 가운데 값을 추정하는 기법)
- filter size를 학습하여 object 크기에 맞게 변화

- train과정에서 output feature를 만드는 conv kernel과 offset을 정하는 conv kernel 동시에 학습 가능
- 위 그림은 conv filter의 sampling위치를 보여주는 예시
- 붉은색 점들은 deformable conv filter에서 학습한 offset을 반영한 sampling location. 초록색 사각형은 filter output의 위치
- 일정하게 sampling pattern이 고정되어 있지 않고, 큰 object에 대해서는 receptice field가 더 커진 것을 확인할 수 있음.
Conv 기법 표 정리
https://www.notion.so/10eefcee989d465bbf31b8133a3924ff?v=ef585ea7a0e2444ebd296904856f4b62
CNN 기법 비교
A new tool for teams & individuals that blends everyday work apps into one.
www.notion.so
'딥러닝 > 컴퓨터비전' 카테고리의 다른 글
| [Computer Vision] Pre-trained Models 정리 (0) | 2023.01.19 |
|---|---|
| [Computer Vision] CNN 정리 (1) | 2023.01.19 |
| Easy OCR 간단하게 사용해보기 (0) | 2021.03.31 |
| Easy OCR 라이브러리 (0) | 2021.03.14 |

최근댓글