이번 ICLR 2023에 있었던 <TOKEN MERGING: YOUR VIT BUT FASTER> 논문에 대해서 리뷰를 진행한다.
(https://arxiv.org/abs/2210.09461)
이 논문은 Transformer의 정확도를 유지하면서도, 연산량을 줄여 모델이 한번에 처리할 수 있는 정보의 양을 늘리기 위해서 ToMe(Token Merging)이라는 기법을 제안한 논문이라고 볼 수 있다.
이 포스팅에서는 ToMe라는 기법에 대해서 살펴보고, 주요한 실험 결과를 정리해 볼 예정이다(모든 실험 결과를 다루지는 않는다!).
Introduction
Transformer가 등장한 이후, NLP, Computer Vision 등 다양한 분야에서 Transformer를 기반으로 한 모델들이 쏟아져 나오고 있다. 특히나, Vision Transformer가 등장한 이후에는 Computer Vision 분야에서도 Transformer가 적극적으로 사용되고 있는데, 요즘엔는 domain-specific transformer들이 많이 나왔다. 이들이 등장하게 된 본질적인 이유는 Efficiency(효율성)에 기인한 것이라고 볼 수 있다.
Transformer의 거의 유일한(?) 단점은 "연산량이 많다."라는 것이다.
따라서 최근에는 ViT의 subfield에서 token이 런타임에서 pruning 되는 기법들을 종종 사용하곤 한다. 하지만, 이런 방법들에는 다음의 단점들이 존재한다.
- Information Loss
- Require re-training
- most cannot be applied to speed up training (대부분은 훈련 속도를 높이기 위해 적용할 수 없다.)
- serveral prune different numbers of tokens depending on the input content, making batched inference infeasible
(입력 내용에 따라 여러 토큰을 제거하여 일괄 처리된 inference를 실행할 수 없다.)
Token Merging에 대한 소개
이 방법은 기존에 있었던 Token pruning 기법 대신에, token을 merging(병합)하는 방식을 사용한다. 이 방법은 pruning만큼 빠르면서도 더 정확하다. 추가적으로 이 방법은 pruning에서는 필수적이었던 re-training 없이도 모델을 inference할 수 있다는 장점을 가지고 있다. ToMe는 training speed를 거의 절반까지도 줄일 수 있다. 또한, Image, Video, Audio의 다양한 모달리티에서 데이터에 어떠한 수정도 가하지 않으면서 대부분의 경우에 state-of-the-Art 모델들과 비견할 만한 성능을 내는 것을 발견할 수 있었다.
Token Merging
이 방법의 목표는 ViT에 token merging module을 넣어서 ViT 모델이 한번에 더 많은 처리량을 가질 수 있도록 하는 것이다.
Strategy
각 transformer block에서 layer마다 $ r $개의 token을 줄인다. 여기에서 $ r $은 비율이 아닌 토큰의 개수를 의미한다. $ L $개의 block을 지나게 되면, 점진적으로 $ rL $개의 토큰을 merge하는 것이다. 이 $ r $을 조정함으로써 speed-accuracy trade-off를 조정할 수 있다.
이 방법의 주요한 점은 Image의 내용에 상관 없이 $ rL $개의 token을 줄일 수 있다는 것이다.
이전의 연구에서는 transformer block의 시작 부분에 reduction method를 적용했었다. 하지만, ToMe는 token merging step을 각 Transformer Block에서 attention module과 MLP 사이에 적용한다. 이렇게 하여 얻을 수 있는 효과는
- information to be propagated from tokens that would be merged
병합될 토큰에서 전파될 정보가 반영이 될 수 있도록 하였으며, - enables us to use features within attention to decide what to merge
어떤 것을 병합할 지를 결정하기 위해서 attention 내부의 feature들을 사용할 수 있도록 한다
위의 두가지 효과는 Accuracy를 증가시키는 데에 중요한 작용을 한다.
Token Similarity
similar token을 병합하기 전에, 어떠한 토큰이 유사한 지를 명확하게 하기 위해서 “Similar”를 정의해야 한다.
Transformer는 이것을 self-attention의 $ QKV $로 해결할 수 있다. 구체적으로 들어가 보자면, $ keys (K) $가 이미 dot-product similarity에서 사용하기 위해 각 토큰에 포함된 정보를 요약한다. 그러므로 $ key $와 각 $ token $이 얼마나 유사한 정보를 담고 있는지 결정하기 위해서 dot product similarity metric을 사용한다.
Bipartite Soft matching
token similarity가 정의가 되었다면, total number를 $ r $만큼 줄이기 위해서 어떤 token이 matching 되는 지를 빠르게 결정할 수 있는 방법이 필요하다. 기존에는 크게 2가지 방법을 사용했었다.
- kmeans clustering
- graph cuts
하지만, matching을 $ L $번 해야 되고, 각 matching마다 몇 천개의 토큰을 계산해야 하므로 실행시간은 거의 무시할 수 있을 정도가 되어야 한다. 이로 인해서 기존의 방법들인 iterative clustering algorithm은 적용하기에 적합하지 않다고 볼 수 있다. 이 논문에서는 더욱 효율적인 솔루션을 제공하는 데, 이 솔루션의 목표는 다음과 같다.
- We want to avoid anything iterative that cannot be parallelized
(병렬 처리를 할 수 없는 iteration을 피하는 것) - We want the changes merging masks to be gradual
(merging mask가 점진적으로 변화하는 것)
이 점들이 clustering이 아닌 matching 기법을 적용한 이유라고 볼 수 있다. 왜냐하면, clustering은 한 그룹에 병합할 수 있는 token의 수에 제한이 없어, 비슷하지 않은 것들끼리도 하나로 묶일 수 있지만, matching의 경우에는 이를 피할 수 있기 때문이다.
Algorithms
- A와 B가 거의 동일한 사이즈가 될 수 있도록 token들을 2개로 나눈다.
- A에 있는 각 토큰에 대해서 하나씩 B에서 가장 비슷한 token인 것으로 edge를 생성한다.
- 가장 비슷한 것을 나타내는 r개의 edge를 유지한다. (나머지는 지운다.)
- 남아있는 edge들에 해당하는 token들을 병합(Merge)한다.
- 2개의 set을 다시 하나로 합친다.
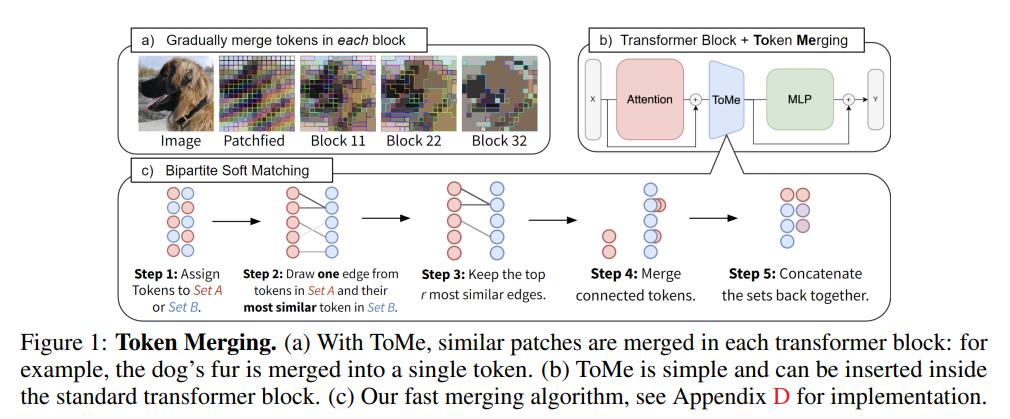
A에 있는 token이 오직 하나의 edge씩 만을 가지고, connected component를 찾는 것은 많은 시간이 필요하지 않다.
신중하게 A와 B를 선택한다면, 정확성에 문제가 없는 모든 토큰 쌍 사이의 유사성을 계산할 필요가 없다. 이것을 실제로 적용을 해보았을 때에는 token을 random하게 pruning하는 것만큼이나 빠르다. 실행시키는 코드 또한, 간단하게 구현할 수 있다고 한다.
Tracking Token Size
토큰이 일단 합쳐지면, 그들은 더이상 하나의 input patch를 의미하지 않는다. 이 점을 무시하고, 기존의 모델에 적용을 하게 된다면, 제대로 된 결과가 나오지 못할 수 있다. 만약, 같은 키를 가진 2개의 토큰을 병합한다면, 그 키는 softmax에서 더 적은 영향을 미치게 되기 때문이다. 따라서 이것을 해결하기 위해서 proportional attetion으로 간단하게 바꿀 수 있다.
$$ A = softmax(\frac{QK^T}{\sqrt{d}} + \log{s}) $$
$ s $는 각 토큰이 포함하고 있는 벡터의 개수를 의미한다. 이것은 키가 하나로 합쳐지더라도 키의 복사본을 가지고 있는 것과 동일한 작업을 수행할 수 있다. 또한, 토큰을 함께 병합할 때처럼 토큰이 aggregate 될 때마다 가중치를 부여해야 한다.
Training with Merging
이전 연구에서는 이미 trained ViT 모델에 token merging을 추가할 수 있도록 설계되었다. ToMe에서 학습이 필수적인 것은 아니지만, accuracy drop을 줄이거나 speed up training을 하는 데에 많은 도움을 줄 수 있다. 학습에서, 토큰 병합을 단순히 풀링 작업으로 처리하고 average pooling을 사용하는 것처럼 merged token을 통해 back propagation을 한다. 또한, 기존의 vanilla ViT에서 사용했던 파라미터 세팅이 ToMe에서도 최적이라는 것을 발견했다.
Image Experiments
ImageNet-1k와 4가지 다른 방식으로 학습이 진행된 ViT (AugReg, MAE, SWAG, DeiT)를 가지고 몇 가지 실험을 진행하였다.
모든 실험에서, 모델을 그대로 가져와서 ToMe를 적용하였고, 추가적으로 2개의 모델(MAE & DeiT)는 학습을 하여 ToMe를 적용하였다. 모든 처리량은 V100GPU + optimal batch size인 fp32의 inference 동안에 측정되었다.
Design Choices
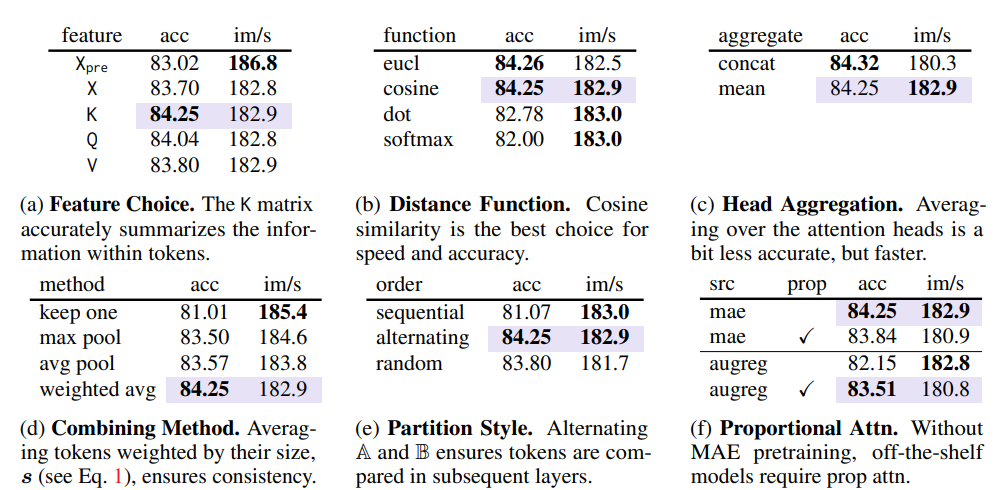
실험은 보라색으로 표시된 부분이 default로 설정되었다. 별다른 표기가 없다면, 모델은 ViT-L/16 MAE model을 training 없이 그대로 가져와 사용하였고, $ r=8 $로 24개의 layer를 거쳐 최종적으로는 98%의 token을 병합하는 방식으로 진행되었다.
Token Similarity (Table 1.a/b/c)
직관적으로 생각할 수 있는 Token’s feature가 가장 좋은 결과를 나타내지는 않았고,
- $ X $ : Moving the merging operation after attention
- $ K $ : using the attention keys
논문에서는 위의 두가지 방법에 대한 정확도를 강조하고자 했다.
Distance function으로는 Cosine similarity가 token distance를 결정하는 가장 좋은 measure인 것이 실험으로 관측되었다. 또한, Aggreation을 할 때에는 concat 대신에 attention head에 걸쳐서 평균을 계산하는 것이 효율적이었다.
Algorithmic Choices (Table 1.d/e)
어떤 토큰을 병합할 지 정한 이후에, token size에 의해서 가중 평균이 되는 방식으로 토큰들을 병합하였다( = 가장 성능이 좋았다.). 또한, Partition style에서는 서로 번갈아 나오면서 A,B 두 부분으로 나누는 것이 가장 성능이 좋았다.
Proportional Attention (Table 1.f)
병합한 이후에, token은 하나 이상의 input patch를 표현한다. 논문에서는 proportional attention으로 이 점을 반영하려 하였다. 놀랍게도, supervised model (AugReg, SWAG, DeiT)에서는 proportional attention이 필수적이라는 것을 알 수 있었지만, MAE 모델에서는 별다른 효과가 없었다.
이 차이는 training 이후 없어지게 되는데, 이것은 MAE가 이미 pre-training에서 token을 제거하였기 때문이다. 그럼에도 불구하고, MAE 모델을 제외한 나머지 모델들에 대해서만 proportional attention을 적용하였다.
Comparing Matching Algorithms
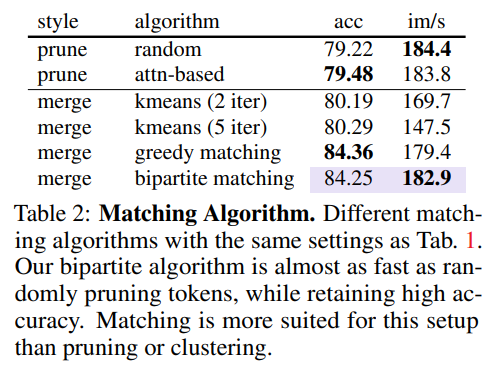
Table 2에서는 bipartite matching을 다른 token reduction algorithm과 비교하는 실험을 진행하였다.
Pruning은 빠르지만, 98%의 토큰을 제거하였을 때에는 중요한 정보가 없어지는 현상이 발생하였다. 이것은 pruning할 것을 랜덤하게 정했을 때와 Attention에서 주목을 받지 못하는 부분을 없앴을 때 모두 공통적으로 발생하였다.
이와 대조적으로, merging token은 서로 비슷하지 않은 토큰들이 병합이 되었을 경우에만 중요한 정보들을 잃어버리는 모습을 보여준다. 이 결과를 통해서 서로 비슷한 토큰들이 병합되도록 하는 것이 중요하다는 것을 알 수 있다.
kmeans는 많은 수의 토큰을 동일한 클러스터에 일치시킬 수 있도록 하여 유사하지 않은 토큰들이 병합될 확률을 높이게 된다. 이 점으로 인해서 training 없이는 10% 이상의 정확도 하락을 줄일 수는 없었다.
kmeans 기법 대신에, 비슷한 토큰들끼리 병합이 되는 matching algorithm을 적용하려고 시도하였다. 가장 유사한 토큰 쌍을 병합한 다음 교체 시간 없이 $ r $번 반복하여 탐욕법으로 이것을 할 수 있었다. 이 방법은 정확하지만, sequential하므로, $ r $이 커질수록 느려질 수 있다는 단점을 가지고 있다.
위 논문에서 제안한 bipartite matching이라는 기법을 통해서 greedy approach의 정확성을 가지면서도, pruning의 속도를 가질 수 있도록 하였다.
Selecting a Merging Schedule
기본값으로는 토큰을 한 layer에서 일정한 수($ r $) 만큼을 줄이는 schedule 방법을 사용하였다. 이 디자인의 최적화를 평가하기 위해서 15,000개의 merging schedules를 표본 추출(?)하였다. 각 schedule에서 AugReg ViT-B/16 모델을 사용하여 정확도와 fp16 (Imagenet-1k val)을 측정하였다.
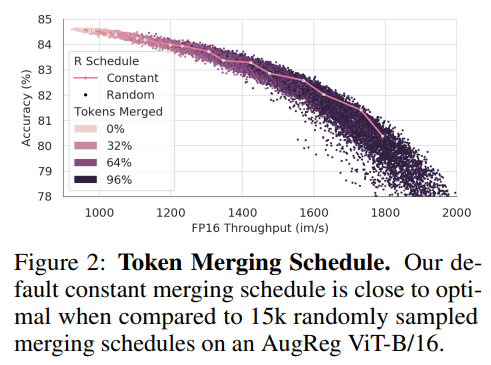
이를 보았을 때, constant($ r $의 값이 중간에 바뀌지 않는 것)가 최적에 가까웠고, 특히 병합된 total token이 클수록 더욱 최적에 가까웠다. 모델이 3배 이상의 처리량을 감당하게 만들기 위해서는 linearly decreasing 방법이 효과가 좋은 것을 알 수 있었다. 처음에는 $ 2r $ 토큰을 첫번째 layer에서 제거하고, 마지막 layer에서는 0개의 토큰을 제거하는 “decreasing” schedule을 정의하였다. 그리고 그 사이에서는 interpolation으로 제거해야 할 토큰의 개수를 정한다. 이것은 동일하게 $ rL $토큰을 제거하지만, 기존보다 더 빠르게 처리할 수 있는 방법이다.
Visualizations

이 논문에서 가장 흥미로웠던 실험으로, ToMe를 적용하였을 때, 마지막 Layer에서 어떤 image patch들끼리 Token이 병합되었는지를 확인하여 이를 시각화하는 실험이었다. ToMe를 적용했을 때 part segmentation과 유사한 token merging이 발생했다는 것을 발견했다. 이는 사람이 인지하는 것과 비슷하게 유사한 의미를 가진 image patch들 끼리 merging이 된다는 뜻이다. 따라서 pruning과 달리, ToMe는 정보를 잃지 않고 background와 foreground 모두에서 수많은 토큰을 병합할 수 있다.
Conclusion
이 연구에서는 ToMe라는 기법을 제안하여 점진적으로 병합되는 토큰의 방식을 통해 ViT 모델의 처리량을 늘렸다. ToMe는 자연적으로 input의 중복된 정보들을 사용하고, 중복성이 있는 모든 modality에 사용할 수 있다.
ToMe는 pure transformer block을 사용하는 “Natural”한 hierarchical model로 볼 수 있다. 이 연구에서는 분류 (Classification)에 초점을 맞췄지만, Visualization part에서는 ToMe가 분할(Segmentation)과 같은 작업에서 높은 잠재력을 가지고 있음을 보여준다.마지막으로 ToMe는 도메인 전체의 대규모 모델에서 잘 작동하고, training time과 memory usage를 줄이므로, 대규모 모델 training의 핵심 구성 요소가 될 수 있을 것이다.
Reference.
Bolya, Daniel, et al. "Token merging: Your vit but faster." arXiv preprint arXiv:2210.09461 (2022).
'딥러닝' 카테고리의 다른 글
| [ICLR 2023] Adaptive Budget Allocation For Parameter Efficient Fine-tuning 논문 리뷰 (0) | 2023.07.26 |
|---|---|
| AttnCAT: Explaining Transformers via Attentive Class Activation Tokens (0) | 2023.05.07 |

최근댓글