이번 ICLR 2023에 있었던 <Adaptive Budget Allocation For Parameter Efficient Fine-tuning> 논문에 대해서 리뷰를 진행한다. (https://arxiv.org/abs/2303.10512)
이 논문은 최근에 많이 다뤄지는 LLMs(Large Language Models)을 Computational Efficient하게 Fine-tuning하는 방법에 대해서 기존에 있던 LoRA(Low Rank Adaptation)의 기법을 보완한 AdaLoRA를 제안하는 논문이다.
이 포스팅에서는 AdaLoRA에 대해서 살펴본다. (추후, 이것의 Reference가 되는 LoRA에 대해서도 다룰 예정이다.)
Abstract
기존의 LoRA는 좋은 성능을 보였으나, parameter budget을 incremental update에 균등하게 분배했다. 하지만, 쓸모 없는 것에 incremental matrix를 크게 가져가는 것은 낭비일 뿐만이 아니라, 오히려 모델의 성능을 저해하기도 한다.
AdaLoRA, which adaptively allocates the parameter budget among weight matrices according to their importance score.
기본적으로 AdaLoRA는 Singular Value Decomposition의 개념을 활용하고 새로운 importance Score를 제안한다.
Introduction
LLMs(Large Language Models) 혹은 PLMs(Pre-trained Language Models)가 최근 Chat-GPT부터 시작을 해서, 여러 모델들이 등장하고 있다. 그에 따라 이 대규모 모델들을 사용자들의 도메인에 특화되도록 Fine-tuning을 하려는 시도들이 있었다. 하지만, 모델들의 파라미터 수가 70억개(7B), 130억개(13B) 등의 몇십억개를 가지고 있으며, 7월 19일에 Meta에서 발표한 Llama v2 모델은 700억개의 파라미터를 가지고 있는 모델들도 존재한다.
이런 엄청난 수의 파라미터를 가진 모델들을 기존에 모든 파라미터를 추가적인 데이터 셋을 사용하여 Fine-tuning 하는 방식(Full Fine-tuning)으로는 기업 단위가 아닌 개인 단위에서 거의 불가능하다고 볼 수 있다. 따라서, Full-Fine-tuning을 하지 않고도 Fine-tuning을 할 수 있는 방법에 대한 연구들이 진행되고 있다.
따라서, Adapter라고 하는 Fully connected Layer 몇 개를 모델 구조 사이(특히, Transformer 기반의 모델의 경우에는 Transformer block 사이에) 추가하고, 이들만을 trainable parameter로 설정하여 Fine-tuning을 하는 데에 computational cost를 줄이려고 하였다.
또 다른 방법으로는 LoRA 이전에, 모델 구조를 변경하지 않고, incremental하게 Layer를 추가하여 이들만을 학습시키는 방법이 있었다. 하지만, 이들 또한 문제를 가지고 있었고, 이를 해결하기 위해 LoRA가 제안되었다. 하지만, LoRA 역시도 다음과 같은 Limitation을 가지고 있다.
- LoRA ignores the fact that the importance of weight matrices varies significantly across modules and layers when fine-tuning pre-trained models.
즉, LoRA가 Weight matrix들의 중요도를 판단하지 않고, 균등하게 weight update를 진행하므로, 동일한 trainable parameter 개수를 가지고 있다고 할 때 최적이 될 수 없는 것이다('Suboptimal하다' 라고 표현한다.).
따라서, 본 논문에서 풀고자 하는 문제는
이것에 대한 해답으로 본 논문에서는 AdaLoRA를 제안한다. 이것은 유동적으로 parameter budget을 할당하여 fine-tuning을 할 때에 더 중요한 weight matrices들에 더 많은 파라미터를 분배할 수 있는 알고리즘이다.
How can we allocate the parameter budget adaptively according to importance of modules
to improve the performance of parameter-efficient fine-tuning?
기존에 LoRA는 사용자가 미리 정한 $ r $차원의 Dense Layer를 사용하였다. 하지만, 최적의 $ r $을 설정하기 위해서는 SVD(Singular Value Decomposition)의 방법을 사용하기도 한다.
그럼 AdaLoRA는 SVD를 사용한 것인가? 그렇지 않다. 이 논문의 초점은 모델의 Fine-tuning에 사용할 수 있는 parameter의 개수가 유한하다고 할 때, 최대한 빠르게, 최대한 효율적으로 추가적인 parameter가 어디에 배치되어야 할 지를 결정한다.
이 점에서 볼 때 SVD는 목적에 부합한 방법이기는 하지만, 계산 과정이 너무 복잡하다는 단점을 가지고 있다. 따라서, 본 논문에서는 SVD와 비슷한 방식을 거치고, addional penalty를 training loss에 더함으로써 SVD의 구성 요소인 P와 Q Matrix의 orthogonality를 규제한다.
AdaLoRA는 Incremental matrix (기존 Model Architecture가 아니라 LoRA 혹은 AdaLoRA를 통해서 추가된 Layer들을 의미)를 세가지 요소 $ (P, \Lambda, Q) $로 나눈다.
- $ i $번째 singular Value
- 이에 해당하는 singular vector 2개
$ i $번째에 해당하는 세가지 요소(triplet)이 얼마나 중요한 지 정량화하기 위해서 본 논문에서는 새로운 impoartance metric을 제시한다. 이 score는 model performance에 대한 triplet의 모든 요소의 기여도를 고려한다.
낮은 중요도를 가진 triplet은 singular value가 0이 되고, 높은 중요도를 가진 triplet은 fine-tuning에 이용되기 위해서 값이 그대로 유지된다.
또한, Global budget schedular라고 하는 것도 위의 모델에서 사용하는데, 이 Global budget schedular가 training stability와 model performance를 향상시킬 수 있다고 한다. 이 방법은 초기 parameter budget은 사용자가 설정한 budget보다 조금 더 많게 설정한다(ex> 1.5배). 이후에, iteration을 돌면서 이 budget을 조금씩 줄여나가고, 최종적으로는 사용자가 설정한 budget에 맞춰지도록 한다.
AdaLoRA Method
이 방법은 중요한 2가지 요소들이 있다
- SVD-based adaptation
- Importance-aware rank allocation
SVD-based Adaptation
$$ W = W^{(0)} + \Delta = W^{(0)} + P \Lambda Q $$
P와 Q는 (left/right) singular vector를 나타내고, Lamda는 singular value를 가지고 있는 대각행렬을 나타낸다.
실제로는, Lambda 행렬이 대각행렬이기 때문에, 이것을 2차원 행렬로 저장을 하는 것이 아니라, 1차원 행렬로 저장할 수 있다. P와 Q는 Gaussian 초기화를 진행하게 되고, Lambda는 0으로 초기화가 진행이 되어 LoRA처럼 초기 값 결과는 0이 될 수 있도록 한다.
$$ R(P, Q) = ||P^TP - I||_F^2 + ||Q^TQ - I||_F^2 $$
Lambda 함수는 각 gradient descent step을 거치면서 점점 pruning 된다. P, Q를 SVD를 통해서 직접적으로도 계산을 해 줄 수 있지만, 이것이 computation cost가 매우 크기 때문에, 이렇게 설정을 한 것이다. 다르게 생각을 하면 AdaLoRA를 사용하지 않고, 'LoRA에서 그냥 A와 B의 행과 열을 삭제해주면 되는 것 아닌가?' 라고 생각할 수도 있다. 하지만, 이 방법은 몇가지 단점을 가지고 있다.
- 이것은 실수로 인해서, 나중에 다시 복구를 해야하는 경우, 처음부터 다시 돌려야 한다.
(AdaLoRA는 ,Singular Value만 없앤 것이기 때문에, 이것만 다시 설정하거나 학습하면 된다는 의미인 것 같다.) - 또한, A와 B는 서로 Orthogonal한 것이 아니기 때문에, 이것을 삭제하는 것은 다른 행과 열에도 영향을 줄 수 있다.
따라서 AdaLoRA에서는 P, Q가 계산이 되는 것이 아니라, trainable한 parameter로 설정하고 규제항을 통해서 두 Matrix가 Orthogonality를 가지도록 만들어준다. .
Importance-Aware Rank Allocation
Budget을 통제하기 위해서 training하는 과정 동안 importance score에 따라서 singular value들을 제거하는 작업을 iteratively하게 거친다.
Training objective
$$ L(P, E, Q) = C(P, E, Q) + \gamma \sum^n_{k=1}R(P_k, Q_k) $$
t-th step에서 먼저 stochastic gradient step을 거쳐서
$$ P_k^{(t)}, \Lambda_k^{(t)}, Q_k^{(t)} $$
를 업데이트 한다.
특히 Lambda의 경우에는
$$ \tilde{\Lambda_k^{(t)}} = \Lambda_k^{(t)} - \eta\nabla_{\Lambda_k}L(P^{(t)},E^{(t)}, Q^{(t)}) $$
Importance Score인 $ S_k^{(t)} $가 주어지게 되면, singular value들은 다음과 같이 pruning하는 과정을 거치게 된다.
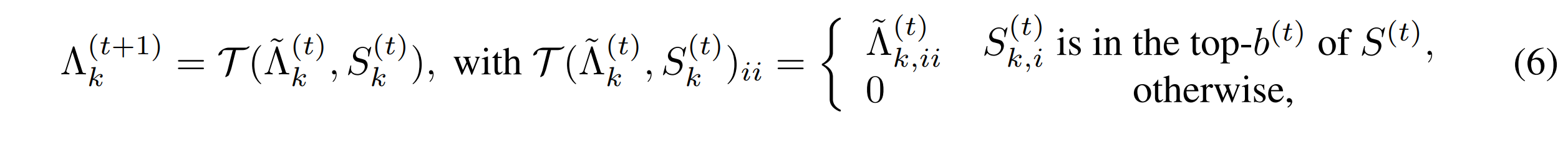
$ S^{(t)} $는 모든 세가지 요소들의 중요도를 포함하고 있다.
$ b^{(t)} $는 t-th step에서 남을 수 있는 singular value들의 개수이다. 그렇다면, Importance Score는 어떻게 정할 수 있을까?
Magnitude of singular values
이 방법은 매우 직관적인 방법이지만, model performance에 대한 기여도를 측정하는 데에 있어서는 정확하게 표현하지 못한다는 것을 발견하였다.
Sensitivity-based importance
Training Loss에 대해서 파라미터들의 민감도를 scoring 할 수 있는 방법을 고안하였다. 이 방법은 모든 객체들의 sensivity가 모델 performance에 대한 세가지 요소들의 기여도를 정량화 하는데에 전부 적절하게 융합되어 고려되어야 한다.
$$ S_{k, i} = s(\lambda_{k, i} + \frac{1}{d_1} \sum^{d_1}{j=1}s(P{k, ji}) + \frac{1}{d_2} \sum^{d_2}{j=1}s(Q{k, ij}) $$
S가 parameter 크기에 영향을 받지 않도록 P와 Q의 평균 중요도를 계산한다. 여기에서 s(.)는 각각의 객체에 대한 특정한 importance function이다.
$ s( ) $ 함수는 magnitude of the gradient-weight product라고 정의된 함수를 사용할 수 있다. 그 정의는 다음과 같다.
$$ I(w_{ij}) = |w_{ij}\nabla_{w_{ij}}L| $$
이것은 parameter가 0으로 되었을 때 Loss의 변화를 근사한다. 만약에, parameter를 제거했을 떄 큰 영향을 가지고 있다면, 모델은 이것에 민감할 것이며, 이것을 유지해야 할 것이다. 하지만, 다른 연구에서는 이것이 충분하게 reliable하지 않다는 것을 밝혔다. Stochastic sampling과 복잡한 training dynamic이 위의 식에서 sensitivity를 측정하는 데에 high variability와 large uncertainty를 가진다고 말한다. 따라서, 이것을 해결하기 위해서 sensitivity smoothing과 uncertainty quantification을 진행함으로써 이것을 해결하였다
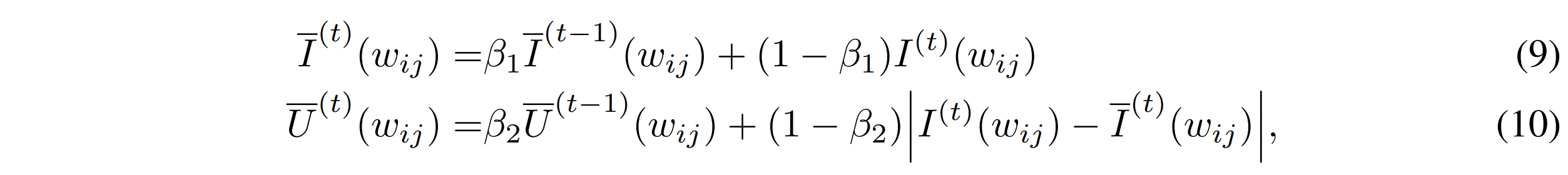
각 beta들은 전부 0에서 1 사이의 값을 가지게 된다.
$ \bar{I}^{(t)} $는 exponential moving average에 의해서 smoothed sensitivity를 나타내고, $ \bar{U}^{(t)} $는 $ I^{(t)} $와 $ \bar{I}^{(t)} $ 사이의 local variation을 정량화 한 uncertainty term이라고 볼 수 있다. 따라서 이것을 가지고
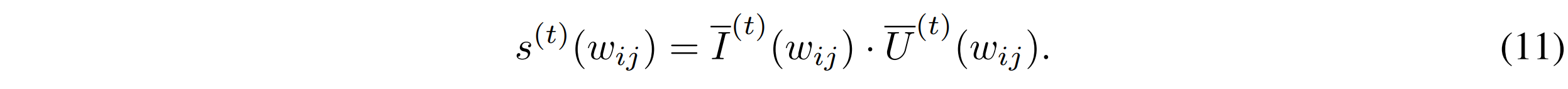
(11)번 식을 가지고 위의 $ S_{k,i} $를 정의하는 식에 적용하였을 때 일반적으로 가장 좋은 성능을 내는 것을 볼 수 있었다.
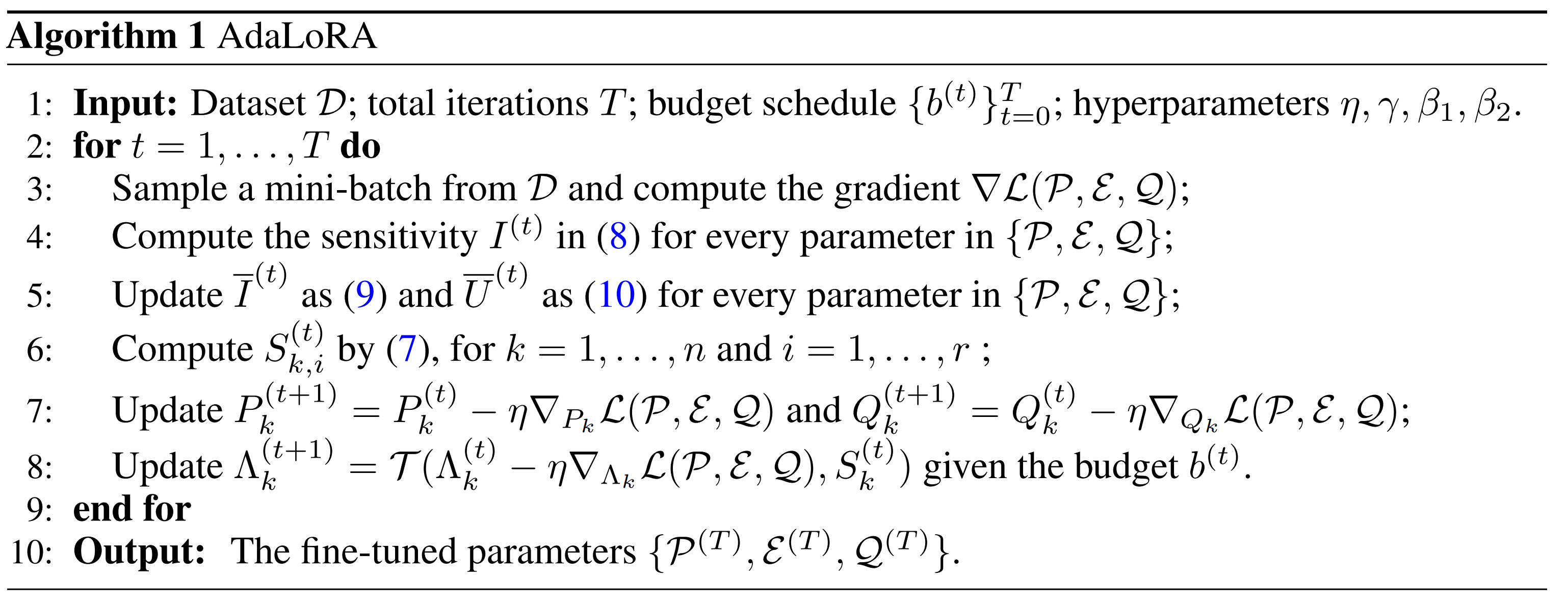
Global Budget Scheduler
본 논문에서는 budget이라고 하는 b^(t)를 모든 incremental matrices의 rank를 전부 합한 것(즉, total singular values)라고 볼 수 있다.
Training을 용이하게 하기 위해서, global budget scheduler를 사용했다.
학습 초기에는 실제 설정한 budgt보다 약간 많은 수의 budget을 가지고 실행한다. 우리는 각각의 incremental matrix의 initial rank를 초기 budget을 n으로 나눈 값으로 설정한다. 그 다음에 cubic schedule을 통해서 budget을 설정한 데까지 줄인다. 이것이 AdaLoRA가 초기에는 parameter space를 먼저 탐색하고, 나중에 important weights에 집중하도록 만든다. Cubic Schedule이라는 것이 정확하게 나와있지는 않지만, 식을 봤을 때는 처음에는 budge을 감량하는 속도를 낮게 하고, 갈수록 많은 budget을 삭감하는 것을 의미하는 것으로 보인다.
낮은 중요도를 가진 triplet은 singular value가 0에 가까워지고, (0이 된다고 보면 될 거 같다.)
높은 중요도를 가진 triplet은 fine-tuning에 이용되기 위해서 값이 그대로 유지된다.
또한, Global budget schedular라고 하는 것도 위의 모델에서 사용하는데, 초기 parameter budget은 사용자가 설정한 budget보다 조금 더 많게 설정한다.(예를 들어 1.5배 정도?) 이후에, iteration을 돌면서 이 budget을 조금씩 줄여나가고, 최종적으로는 사용자가 설정한 budget에 맞춰지도록 한다.
이렇게 하여 Global budge schedular는 training stability와 model performance를 향상시킬 수 있다고 한다.
Reference
- Zhang, Qingru, et al. "Adaptive budget allocation for parameter-efficient fine-tuning." arXiv preprint arXiv:2303.10512 (2023).
'딥러닝' 카테고리의 다른 글
| [ICLR 2023] Token Merging : Your ViT But Faster 논문 리뷰 (0) | 2023.07.26 |
|---|---|
| AttnCAT: Explaining Transformers via Attentive Class Activation Tokens (0) | 2023.05.07 |

최근댓글