이번 포스티에서는 시계열뿐만 아니라, 전반적인 데이터 분석에서 최근 많이 사용되는 앙상블 기법들이 어떤 의미를 갖는 지에 대해서 설명할 것이다.
앙상블(Ensemble)
앙상블이란, 하나의 데이터 모델을 학습하여 예측하지 않고, 여러 데이터 모델들을 생성하여, 각각 학습을 진행하고, 예측을 하여, 예측 결과들을 통해서 최종 예측 결과를 도출하는 기법을 의미한다.
단순하게 생각하면, 여러 데이터 모델들을 이용하여 예측을 하는 기법이라고 생각하면 된다.
앙상블 기법과, Bagging, Boosting의 기술적인 내용은
https://dsbook.tistory.com/165?category=761052
와 그 후속 포스팅에 자세하게 나와있으니 이것을 참고하자.
Bias-Variance Trade-Off
데이터를 분석하여 예측한다는 것은 결국 High Bias & High Variance 에서 Low Bias & Low Variance인 방향으로 진행해나간다는 의미로 해석할 수 있다.

하지만, 다른 데이터 분석을 진행하면 이미 많이들 알고 있는 내용이겠지만,
Bias와 Variance를 동시에 줄일 수 있는 방법은 Data set의 Quality, 즉, 학습에 사용되는 Data set이 변하지 않는 이상, 현실적으로 존재하지 않는다.
따라서, Variance를 줄이기 위해서 Bagging을, Bias를 줄이기 위해서 Boosting을 사용한다.
Bagging
Bagging은 Bootstrap + Aggregation 두 글자를 합친 것이다.
대표적인 알고리즘은 Random Forest이다.
Random Forest란?
대표적인 앙상블 러닝 모델의 하나로, 여러 의사결정 나무(Decision Tree)를 제작하고, 예측을 할 때, 각 모델들의 예측 결과를 취합하여 최종 예측을 내놓는 모델이라고 볼 수 있다. 이 때, 각 트리 모델은 전체 훈련 Data set에서 복원 추출로 일부를 뽑아서 생성한다. 이렇게 생성되어진 모델들은 약간씩 다른 모델들이 된다. (Random_seed를 변경하는 것 이상으로 변화를 주고 싶을 때 사용한다.)
또한, 단순히 각 모델들의 결과만을 사용하는 Hard Voting과, 해당 예측 결과의 확률을 사용하는 Soft Voting기법등을 Random Forest와 함께 사용할 수 있다.
Bagging을 사용하면, 퍼져있는 여러 값들 (각 모델들의 예측 결과)의 평균을 내어, 예측의 Variance를 줄여주는 역할을 하게 된다. 이것을 잘 생각해보면 중심극한정리(CLT)의 원리를 사용하는 것과 동일하다는 것을 알 수 있다.
(단순히 어떤 기법들이 존재한다는 것을 알고있는 것들보다, 수학적, 통계적인 지식들과 연결하여 이해를 할 수 있고, 이것을 최종적으로 주어진 상황에 맞게 적용할 수 있는 능력이 중요하다고 생각한다. )
중심극한 정리 (Central Limit Theorem) :
동일한 확률 분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규분포에 가까워진다는 정리
Boosting
약한 학습기(Weak Learner) 여러 개를 사용하여, 순차적으로 분석을 진행하고, 제대로 예측하지 못한 오차에 중점을 두면서 반복적으로 학습하여 예측 성능을 높여 나가는 기법.

그림으로 본다면 위와 같이 잔차들에 대해서 예측 선(Support Vector)들을 Tuning해 나가는 것을 의미한다.
Bagging이 중심극한정리와 동일한 원리를 가진 기법인 것 처럼, Boosting은 앞에서 배웠던 '잔차 분석'과 동일한 원리를 가진 기법이라고 볼 수 있다.
이것을 수식으로 표현을 하자면,
Boosting은 약한 학습기(Weak Learner)들로 이루어지므로, f_1()함수를 일반적인 방법으로 학습시킨다.
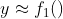
f1함수는 약한 학습기이기 때문에, 잔차(Residual)이 존재할 것이고, 잔차를 수식으로 표현하면,
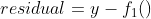
이 된다.
이후에 f2함수를 이 잔차를 예측하는 모델로 지정한다.
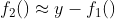
이후 다시 잔차를 계산
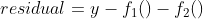
f2함수와 동일한 방식으로 지정한 모델의 개수만큼 반복한다.

최종적으로 f1부터 fn함수까지 모두 더한 결과가 y를 예측하는 모델이 된다.
이 과정에서 f함수들에 대해서 학습률(learning_rate)를 부여할 수도 있고, Early Stopping Condition을 지정하여 Overfitting을 방지할 수도 있다.
Boosting의 여러가지 알고리즘
- AdaBoost : 다수결을 통한 정답 분류 및 오답에 가중치 부여
- GBM : 손실함수(검증 지표)의 Gradient로 오답에 가중치 부여
- XGBoost : GBM보다 자원을 효율적으로 사용하도록 함으로써 성능 향상
- LightGBM : XGBoost 대비 자원 소모 최소화, 대용량 데이터 학습 가능, 근사치 분할(Approximates the Split)을 통한 성능 향상
참고 자료 : 패스트 캠퍼스 시계열 데이터 분석 A - Z
'딥러닝 > 시계열' 카테고리의 다른 글
| [실전 시계열 분석] - chap05 시간 데이터 저장 (0) | 2022.03.22 |
|---|---|
| [실전 시계열 분석] - chap04 시계열 데이터의 시뮬레이션 (0) | 2022.03.22 |
| [논문 Review] 온라인 게임의 주간 플레이어 인구 패턴 2 (0) | 2021.03.27 |
| [논문 Review] 온라인 게임의 주간 플레이어 인구 패턴 1 (0) | 2021.03.26 |
| 정규화 방법론 알고리즘 (0) | 2021.03.24 |

최근댓글