chap05 시간 데이터 저장
시계열 데이터의 가치는 실시간 스트리밍보다는 과거에 축적된 데이터에서 자주 발생한다. 따라서 시계열 데이터를 저장하기 위한 스토리지가 반드시 필요하다.
- 크기에 따른 성능 확장 방언에 대한 중요성
- 데이터 접근에 대한 무작위적인 방식 대 순차적 방식의 중요성
- 자동화 스크립트의 중요성
5.1 요구 사항 정의
시계열 데이터를 위한 스토리지를 고려할 때, 스스로에게 다음과 같은 질문을 해봐야 한다.
- 얼마나 많은 시계열 데이터를 저장해야 하나요? 얼마나 데이터가 빠르게 증가하나요?
- 측정에 대한 업데이트가 끊임없이 발생하거나(예: 계속 이어지는 웹 트래픽 스트림), 측정이 구분되는 개별 사건 단위로 발생하나요(예: 지난 10년 동안 미국의 모든 주요 공휴일에 대한 시간별 항공 교통 시계열)?
- 데이터의 간격이 일정하거나 일정하지 않나요?
- 지속적으로 데이터를 수집할 것인가요? 아니면 프로젝트가 마무리되는 시점이 정해져 있나요?
- 시계열로 하려는 것이 무엇인가요? 실시간으로 시각화가 필요한가요? 신경망이 수천 번 반복적으로 접근할 전처리된 데이터가 필요한가요?
5.1.1 실시간 데이터와 저장된 데이터
모든 모바일 기기에서 특정 웹페이지를 로딩하는 데 걸리는 시간을 기록하는 웹 서버를 구동한다고 가정해보자.

여러 가지 이유로 웹 페이지의 로딩 시간은 별로 흥미로운 데이터가 아니다. 집계 및 통계를 활용해 아래 쪽처럼 변환하면 유의미한 데이터를 뽑아올 수 있다.

개별 사건을 무기한으로 저장하는 것보다, 임시 스토리지를 구축하고 간결하고 쉽게 이해할 수 있게 저장해줘야 한다. 가능한 데이터 중복을 제거하고, 개별 데이터를 모두 저장하기 보다는 종합하는 기법을 사용하여 데이터 스토리지를 간소화하는 것이 좋다.
정보의 유실없이 데이터를 줄일 수 있는 몇 가지 경우
천천히 변하는 변수 : 상태 변수를 저장한다면 값이 변한 데이터만 기록하면 좋다. 5분 단위로 측정된 온도의 데이터 중 반올림된 값만 고려했을 때, 계단함수 형태의 그래프를 띄고 반복되는 값은 저장하기 않아서 저장 공간을 아낄 수 있다.
노이즈가 낀 높은 빈도의 데이터 : 목적에 따라 노이즈의 평가는 달라진다.
오래된 데이터 : 오래된 데이터일수록 활용 가능성은 줄어든다. 데이터 삭제 과정을 자동화할 수 있다면 질의 지연이나 확장성에 대한 중요도를 낮출 수 있다.
5.2 데이터베이스 솔루션
다음과 같은 특성을 가진 솔루션이 필요할 때, 데이터베이스는 좋은 선택이 될 수 있다.
- 여러 서버로 확장 가능한 스토리지
- 저지연의 읽기/쓰기
- 일반적인 지표의 내장된 계산 함수(예: 시간지표에 group-by 연산이 적용 가능할 때 group-by 질의에서 평균을 계산하는 것)
- 시스템의 성능 튜닝 및 병목 문제 분석에 사용되는 문제 진단 및 모니터링 도구
5.2.1 SQL과 NoSQL
관계형 테이블로 묘사될 때는 SQL, 시간 범위가 무한한 데이터의 수용이 가능하도록 확장될 수 있는 개방형 솔루션이 필요하다면 NoSQL를 고려해보는 것이 좋다.
과거 SQL 솔루션은 트랜잭션 데이터에 기반한다. 트랜잭션은 여러 기본키로의 속성들로 구성된다. 시간도 기본키로서 다뤄질 수 있지만, 다른 것들과 마찬가지로 정보축이 되어서는 안 된다.
시계열과는 꽤 다른 트랜잭션 데이터에는 다음과 같은 두 개의 중요한 특징이 있다.
- 이미 존재하는 데이터의 업데이트가 빈번히 발생한다.
- 기본적으로는 데이터가 정렬되지 않아서, 다소 무작위적인 접근이 이루어진다.
시계열 데이터의 특성
- 이력(history)을 상세히 다루며, 업데이트되지 않는 것이 일반젹이며 데이터를 임의의 순서로 쓸 수 있는 작업은 중요하지 않다.
- 읽기 작업보다 쓰기 작업이 빈번하게 발생한다.
- 데이터의 쓰기, 읽기, 업데이트 작업은 일련의 사건이 일어나는 시간 순서에 따라 이루어진다.
- 트랜잭션 데이터보다 훨씬 더 동시성 읽기가 수행될 가능성이 높다.
- 시간 외 변수를 기본키로 두는 경우는 매우 드물다.
- 개별 데이터 삭제보다 데이터 뭉치를 삭제하는 것이 훨씬 더 일반적이다.
이러한 이유로 NoSql데이터베이스가 시계열 데이터에 좀 더 적합하다. 특히 쓰기 작업에서 성능이 뛰어난데, 아래는 sql데이터베이스와 nosql에 시계열 데이터를 삽입할 때의 성능 비교 그래프를 보여준다.
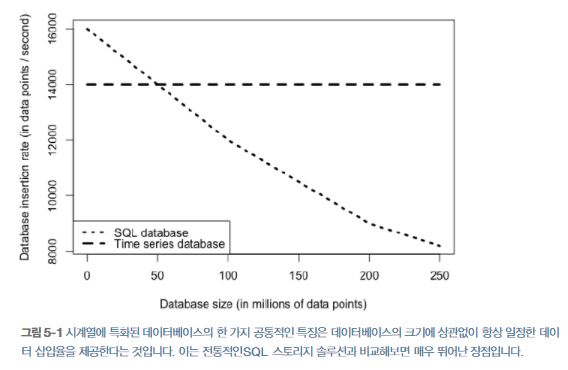
NoSQL, SQL 둘 다 원칙은 같은 시간에 요청되는 경향이 있는 데이터는 같은 위치에 저장되어야 한다는 것이다.
시계열에 대해 SQL의 장점
- 해당 데이터베이스에 이미 저장된 관련성이 높은 다른 비시계열 데이터와 손쉽게 연관시킬 수 있다.
- 계층적 시계열 데이터는 관계형 테이블이 자연스럽게 들어맞는다. SQL 스키마는 계층을 분명히 설명해주고, 관련 시계열들의 그룹화를 가능하게 해준다. 대조적으로 NoSQL 솔루션에서는 낮은 체계성을 가진 채 여기저기 흩어지기 쉽다.
- SQL 데이터베이스에 가장 잘 맞는 트랜잭션 데이터에 기반하여 시계열을 만든다면, 동일 데이터베이스에 저장하여 쉬운 검증 및 상호 참조 등의 이점을 누릴 수 있다.
시계열에 대해 NoSQL의 장점
- 쓰기 속도가 빠르다.
- 미래 데이터를 아직 충분히 알지 못해서 지능적이며 견고한 스키마 설계가 불가능한 경우 유리하다.
- 비전문가도 즉시 사용이 가능할정도로, 수준 높은 스키마를 디자인 할 가능성이 적어서 성능이 보장된다.
5.2.2 인기 있는 시계열 데이터베이스와 파일 솔루션
인플럭스DB : 시계열 특화 데이터베이스 - 타임스탬프, 측정 내용 라벨, 하나 이상의 키/값 필드, 키/값의 쌍으로 구성된 메타데이터 태그 정보
푸시기반 데이터베이스 시스템으로, 데이터를 직접 넣어줘야 한다.
프로메테우스 : HTTP 기반으로 동작하는 모니터링 시스템 시계열 데이터베이스
풀기반 시스템으로 로직을 쉽게 조정하고 검사할 수 있다.
범용 NoSQL 데이터베이스
테이블 구조가 아닌 문서 구조에 기반하고 있으며, 시계열에 특화된 기능을 많이 포함하지 않는다. 하지만 유연한 스키마 덕분에 유용하다. 특히 SQL은 직사각형 형태로 데이터를 유지해야 하나, NoSQL은 누락된 데이터의 특정 값은 누락된 상태 그대로 놔둔다.
ex) 몽고DB
데이터베이스의 장점
- 빠른 읽기 또는 쓰기 능력
- 유연한 데이터 구조
- 푸시 또는 풀기반 데이터 수집
- 자동화된 데이터 제거 기능
5.3 파일 솔루션
결국 데이터베이스는 스크립트 + 데이터 스토리지 -> 단층 파일이 된다. 즉 해당 파일에 안전하고 쉽게 접근할 수 있도록, 파일을 관리해줘야 한다. 다음 중 하나라도 해당 된다면 단층 파일 솔루션을 선택하는 것이 좋다.
- 성숙된 데이터 형식이 완성되어 오랜 기간동안 합리적으로 그 명세를 따를 수 있는 경우
- 데이터 처리가 I/O와 밀접하게 관련되어 있어, 속도의 향상에 개발 시간을 할애하는 것이 합리적인 경우
- 데이터의 무작위적인 접근보다 순차적 접근이 필요한 경우
5.3.1 넘파이
데이터가 순수 수치형으로 구성되어 있을 때, 행렬 및 벡터를 변환하기 유용한 라이브러리이다. 한 가지 단점은 단일 데이터 형식만 존재한다는 것이다.
5.3.2 팬더스
손쉬운 데이터의 레이블링, 시계열 데이터 저장을 가능하도록 한다.
'딥러닝 > 시계열' 카테고리의 다른 글
| [실전 시계열 분석] - chap07 시계열의 상태공간 모델 (0) | 2022.03.29 |
|---|---|
| [실전 시계열 분석] - chap06 시계열의 통계 모델 (0) | 2022.03.22 |
| [실전 시계열 분석] - chap04 시계열 데이터의 시뮬레이션 (0) | 2022.03.22 |
| Bagging & Boosting (1) | 2021.05.17 |
| [논문 Review] 온라인 게임의 주간 플레이어 인구 패턴 2 (0) | 2021.03.27 |

최근댓글