chap06의 핵심내용
- 자기회귀(AR)모델, 이동평균(MA) 모델, 자기회귀누적이동평균(ARIMA) 모델, 벡터자기회귀(VAR), 계층형 모델
정상성 : 평균과 분산이 시간에 따라 상관관계를 가지지 않는 형태
6.1 선형회귀를 사용하지 않는 이유
선형회귀 분석은 독립항등분포(IID)데이터가 있다는 것을 가정하기 때문에, 시계열 데이터에 해당되지 않는다. 시계열 데이터는 시간에 가까운 데이터일수록 서로 강한 관계를 맺는 경향이 있다. 즉 시계열 데이터에 시간적 상관관계가 없다면 면 미래를 예측하거나 시간의 역동성을 이해하는 등 전통적 시계열 작업을 하기 어렵다.
선형회귀, 최소제곱선형회귀 모델을 다음과 같은 상황일 때 시계열 데이터에 적용해볼 수 있다.
시계열 행동에 대한 가정
- 시계열은 예측 변수에 대한 선형적 반응을 보인다.
- 입력 변수는 시가넹 따라 일정하지 않거나, 다른 입력 변수와 완벽한 상관관계를 갖지 않는다.
오차에 대한 가정
- 각 시점 데이터에 대해 모든 앞뒤 시기의 설명변수에 대한 예상 오차 값은 0이다.
- 특정 시기의 오차는 과거나 미래의 모든 시기에 대한 입력과 관련이 없다. 따라서 오차에 대한 자기상관 함수 그래프는 어떠한 패턴도 띄지 않는다.
- 오차의 분산은 시간으로부터 독립적이다.
위와 같은 가정이 성립된다면 보통최소제곱회귀는 주어진 입력에 대한 계수의 비편향추정량이 된다.
비편향추정량 : 추정치가 과대/과소 평가된 것이 아닌 것
6.2 시계열을 위해 개발된 통계 모델
시계열의 미래 값이 과거 값의 함수라고 정의하는 매우 간단한 자기회귀 모델을 시작으로, 단변량 다변량 시계열 데이터를 위해 개발된 다양한 방법들을 살펴볼 것이다.
6.2.1 자기회귀 모델
자기회귀(AR) 모델은 과거가 미래를 예측한다는 직관적인 사실에 의존한다. 따라서 특정 시점 t의 값은 이점 시점들을 구성하는 값들의 함수라는 시계열 과정을 상정한다.
시계열 이외의 정보가 없을 경우 많은 사람이 첫 번째로 시도하는 방법이 자기회귀이다. 이름 그대로 과거 값들에 대한 회귀로 미래 값을 예측하는 방식이다. 가장 간단한 AR 모델의 수식은 아래와 같다.

시간 t에서 계열의 값은 상수 b0, 이전 시간 단계에서 값에 상수를 곱한 b1 X yt-1, 시간에 따라 달라진느 오차항 et에 대한 함수이다. 여기서 오차항은 일정한 분산 및 평균 0을 가진다고 가정한다. 또한 AR모델은 하나의 원인 변수만 지닌 선형회귀 모델과 동일하게 매핑된다.

b0와 b1값을 알고 있다면 주어진 yt-1 조건에서의 yt의 기대 값과 분산 모두를 계산할 수 있다.

이 표기법을 일반화하면 현재 값이 의존하는 가장 최근 값인 p로 조절할 수 있으므로 AR(p)로 생성할 수 있다. 아래는 전통적인 표기법으로 사용된 ϕ는 자기회귀계수를 나타낸다.

3장에서와 같이 시계열 분석의 핵심은 정상성이다. 정상성을 가정하고 yt에 대해 다시 작성해보자면

위와 같이 나타낼 수 있고, yt의 기대값은 정의에 따라 0이다.

식을 정리하면 위와 같이 평균과 AR계수의 관계를 알 수 있는데, 이와같이 분산과 공분산이 부과하는 방식도 알아볼 수 있다.

위와 같이 일반화된 수식을 구할 수 있으며, 이 수식은 yt에서 평균을 뺀 것은 오차항들에 대한 선형함수라는 뜻이다. 이 결과는 t에서의 et값이 독립적일 때 기대 값과 공분산이 0이라는 결론을 내릴 수도 있으며, 식을 제곱하여 yt의 분산도 계산할 수 있다.

분산량은 위와 같이 0보다 크거나 같아야 한다는 정의에 따라, 위 수식처럼 구할 수 있다. 약한 정상성이 되기 위한 조건은 과정의 평균과 분산이 시간에 따라 변하지 않아야 한다는 것이다.
AR(p)모델의 파라미터 선택
데이터가 AR모델에 적합한지를 평가하려면 먼저 과정과 편자기상관함수(PACF)의 그래프를 그려보는 것이 좋다. AR과정의 PACF는 AR(p)과정의 차수 p를 넘는 부분을 0으로 잘라버리는데, 그 결과 데이터에서 실증적으로 볼 수 있는 AR 과정의 차수를 구체적이며 시각적으로 표시한다. 여기서 p는 시각 p이전에서의 값들을 통해 yt를 예측하는 것이다. p가 1일 대는 yt-1의 수식을 통해 예측값을 구하고, p가 2일 때는 yt-1 + yt-2의 차분을 통해 예측값을 구한다.
륭-박스 검정
- H0 : 데이터가 일련의 상관관계를 나타내지 않는다.
- H1 : 데이터가 일련의 상관관계를 나타낸다.
AR(p)과정으로 예측하기
시간을 n단계 앞서 예측하기
AR모델로 시간을 한 단계 앞서 예측하는 상황을 고려해보고, 지연 -1의 계수가 0으로 제한된 demand 데이터에 대한 모델로 계속 작업을 진행해보자.
모델이 한 기간에서 다음 기간으로의 변화를 잘 예측하는지 확인하려면 원본 데이터의 계열과 예측 모두에 대한 차분을 구해서 비교해야 한다. 차분을 구한 다음에도 예측과 데이터가 유사한 패턴을 보인다면 모델이 의미 있다고 판단할 수 있다.
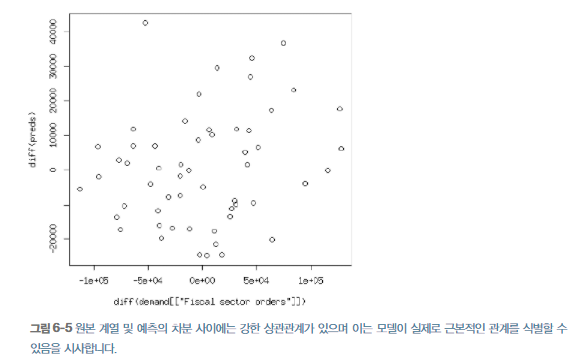
또한 원본 계열의 차분 그래프를 그리고 상관관계를 살펴봄으로써, 동일 시기에 동일한 움직임을 예측하는지 여부를 검정할 수도 있다.
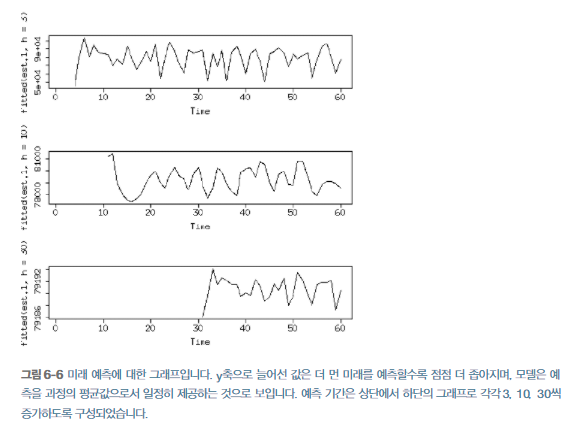
먼 미래의 예측은 단순히 과정의 평균을 예측할 뿐으로, 현재 데이터는 먼 미래 어느 시점을 파악하는 데 유용한 정보를 제공하지 못하기 때문에 예측은 알려진 기준 속성(예 : 평균)으로 점차 회귀한다. 여기서 중요한 점은 AR모델이 단기예측에 가장 적합하다는 것이다. 이 모델은 먼 미래의 예측 기간이 주어지면 그 예측 능력을 상실한다.
이동평균 모델
이동평균(MA)모델은 각 시점의 데이터가 최근의 과거 값에 대한 '오차'항으로 구성된 함수로 표현된 과정에 의존한다. 이동평균 모델은 자기회귀 모델과 유사하게 표현되나, 선형 방정식을 구성하는 항들이 과정 자체에 대한 현재와 과거 값이 아니라 현재와 과거의 오차항을 가리킨다는 점이 다르다. 따라서 차수 q에 대한 MA모델은 다음과 같이 표현할 수 있다.
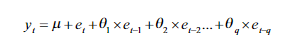
백시프트 연산자
이 연산은 적용될 때마다 한 번의 시간 단계만큼 과거로 이동한다.
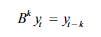
수식은 위와 같으며, 시계열 모델(MA)에 적용했을 때 아래와 같다.
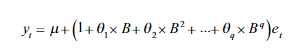
정의상 MA모델은 파라미터에 어떠한 제약 사항도 부여할 필요가 없는 약한 정상을 띄고, 오차항이 독립항등분포라고 가정하여 MA과정의 평균과 분산 모두가 유한하고 시간에 따라 불변한다.
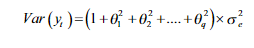
따라서 MA과정의 평균과 분산 모두 파라미터 값에 상관없이 시간에 따라 일정한 값을 가진다. 또한 강한 평균회귀를 보여, 예측이 평균으로 빠르게 수렴하는 특징이 있다. 이유는 자체상관이 없는 백색잡음 함수이기 때문이다.
6.2.3 자기회귀누적이동평균 모델(ARMIA)
AR, MA모델의 역동성을 모두 포괄하는 ARIMA모델을 살펴보자. ARIMA = AR(자기회귀) + I(누적) + MA(이동평균)
차분(I) : 시간에 따른 값의 변화, t - t-1 값

AR이나 MA항을 단독으로 역동성을 충분히 설명하지 못하기 때문에, ARMA모델로 결합될 수 있다. ARMA과정의 정상성은 ARMA를 구성하는 AR 요소로 설명되며, AR모델의 정상성을 제어하는 동일한 특성 방정식으로 제어된다. ARMA에 누적을 넣어 차분이 몇 번이나 구해져야만 하는지를 더하면 ARIMA모델이 된다.
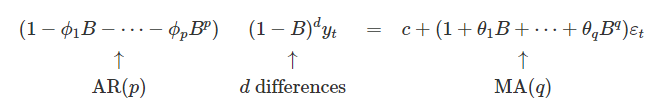
좌변은 AR모델의 차수, 가운데 식은 d 차분, 우변은 MA모델의 차수를 통한 식이 나타난다. 이 식을 통해 각 모델의 적절한 차수를 구하는 것이 중요하다.
6.2.4 벡터자기회귀
실제로 서로 관련성 있는 여러 시계열은 병렬로 존재할 수 있다. 모든 시계열은 자신뿐만 아니라 다른 시계열도 추정하여 예측하므로 변수 한 개당 방정식 한 개를 갖게 된다. 즉 지금까지 다룬 모델은 예측변수 -> 목적 예상변수처럼 단방향 관계의 모델만 다뤘다. 하지만 반대 경우도 허용해야만 하는 경우도 많고, 이러한 feedback realtaionship을 활용하기 위해 벡터 자기회귀가 나오게 되었다.
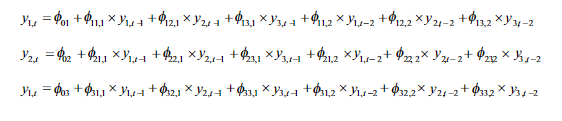
자기회귀 - 나의 과거에만 영향을 받는 모델
벡터자기회귀 - 나의 과거와 다른 변수의 과거에서도 영향을 받는 모델
다른 시계열의 벡터 값들이 매트릭스 형태처럼 영향을 주고, 위 수식들을 전개하여 영향을 분석한다.
6.3 시계열 통계 모델의 장단점
장점
- 통계 모델은 간단하고 투명해서 모델의 파라미터 측면을 보면 명확하게 이해할 수 있다.
- 통계 모델을 정의하는 간단한 수학적 표현 덕분에, 철저히 통계적인 방식으로 관심 속성을 도출하는 것이 가능하다.
- 작은 데이터셋에 적용해도 좋은 결과를 얻을 수 있다.
- 과적합이라는 위험성 없이 좋은 성능을 얻을 수 있다.
단점
- 데이터셋이 커지면 성능 향상을 보장하지 않는다.
- 분포보다는 분포의 평균값 추정에 집중한다.
- 비선형 관계가 많은 데이터를 설명하는 데 적합하지 않다.
'딥러닝 > 시계열' 카테고리의 다른 글
| [실전 시계열 분석] - chap08 시계열 특징의 생성 및 선택 (0) | 2022.03.29 |
|---|---|
| [실전 시계열 분석] - chap07 시계열의 상태공간 모델 (0) | 2022.03.29 |
| [실전 시계열 분석] - chap05 시간 데이터 저장 (0) | 2022.03.22 |
| [실전 시계열 분석] - chap04 시계열 데이터의 시뮬레이션 (0) | 2022.03.22 |
| Bagging & Boosting (1) | 2021.05.17 |

최근댓글