loss function : score에 대해 불만족한 정도를 측정하는 함수
optimization : loss function을 최소화하는 파라미터를 찾는 과정
1. SVM hinge loss

SVM의 loss인 hinge loss는 0과 sj(잘못된 label의 score), syj(제대로 된 label의 score), 1(safety margin)
-> 해석1 : sj - (syj - 1) => correct label의 score보다 큰 incorrect label score가 있다면 loss는 0보다 크게 나타남
-> 해석2 : coreect label의 score가 incorrect label score보다 1이상 크다면 loss는 0이 됨
ex) 고양이로 분류했다면

correct label score(cat) : 3.2
incorrect label score(car, frog) : (5.1, -1.7)
해당 값을 수식에 넣고 sum한다면 2.9 -> 최종 loss
자동차는 4.9로 올바르게 구분했으므로 -> 최종 loss는 0
최종 loss

각 loss들을 전부 더한 다음에 class 개수로 나누어줌 -> 최종 loss는 4.6
q1. if j = y_i 로 연산이 이루어진다면?
-> 최종 loss값이 1씩 증가함(3.2 - 3.2 + 1) 1씩 늘어나기 때문에
q2. score를 구할 때 sum -> mean으로 교체한다면
-> 큰 의미는 없음
q3. 수식에 제곱을 사용한다면?
-> squared hinge loss = 제곱을 해준다는 것은 nonlinear하다는 것
q4. svm loss의 최저값, 최대값
-> min = 0 / max = 무한대
q5. weight를 매우 작은 수로 초기화함 -> score는 0에 가까운 값이 나타남. 이 때의 loss는?
-> 0-0 + 1 => class개수-1 / 위 예시에서는 2라는 값이 나옴
=> class개수-1을 초기 loss값으로 가지게 됨. 이 loss값이 규칙에 맞는지 확인하면 학습이 제대로 됐는지 파악할 수 있음(sanity check)
code로 나타낸다면

x (image column vector)
y (label inter value)
w (weight matrix)
i와 j_y가 같은 경우는 0으로 처리(1의 값을 상쇄하기 위해)
수식으로 나타낸다면
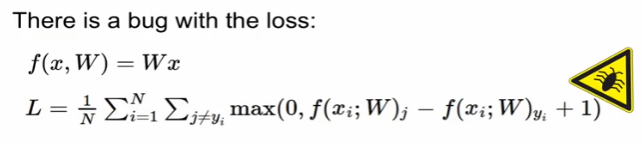
버그 : loss를 0으로 만들어주는 파라미터 값을 발견했다면?
-> loss를 0으로 만드는 값이 유니크 할까? (유니크 하지 않음)
유니크한 값을 결정해주기 위해선?

regularization : w가 얼마나 괜찮은가 측정해주는 것
data loss는 학습용 데이터에 얼마나 최적화해줄 수 있는지 확인해주는 것
regularization loss는 test set쪽에 최대한 일반화해주기 위해 노력하는 것
두 loss항이 서로 완충역할을 하면서 데이터에 fit하고 최적화된 weight값을 추출하게 됨
regularization의 효과는?
- training data에 대한 error는 증가됨
- test set에 대한 퍼포먼스는 좋아짐
- weight가 모두 0에 가깝길 원하기 때문에 data loss와 re loss가 서로 싸움
regularization의 선호 weight

둘다 1인 값을 출력하나 w1, w2중에 w2를 훨씬 선호함
-> 기본적으로 w2가 x vector를 모두 염두해 둠(일반화)
-> weight를 가능한 최대로 spread out해서 모든 input feature를 고려하도록 함
2. softmax classifier (Multinomial Logistic regression)

score의 확률을 최대화하고자함 -> class를 올바르게 맞출 수 있도록
log의 확률을 최대화 = -log 확률을 최소화 => 최종 loss function
log의 장점 : 수학적으로 좀 더 계산이 쉽기 때문에

loss를 구하는 과정
score -> exp를 취한다. -> normalize(확률) -> -log화 => cat에 대한 최종 loss 0.89
q1. loss의 min/max 값은?
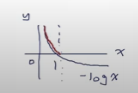
-> - log x의 그래프는 위와 같음. 여기서 x는 확률이기에 x는 [0, 1]에서 머물게 됨
-> 그러므로 min은 0, max는 무한대가 됨
=> 아주 잘 맞추면 확률이 1(loss는 0), 반대는 0(loss는 무한대)
q2. w가 매우작기에 score가 0에 근접, 여기서 loss는?
-> score가 0이기에 exp는 e의 0승은 1, 총 합은 3, 확률은 1/3, -log(1/3)이 loss값
=> -log(1/class개수) 학습 시작 전에 체크
hinge loss VS cross-entropy loss
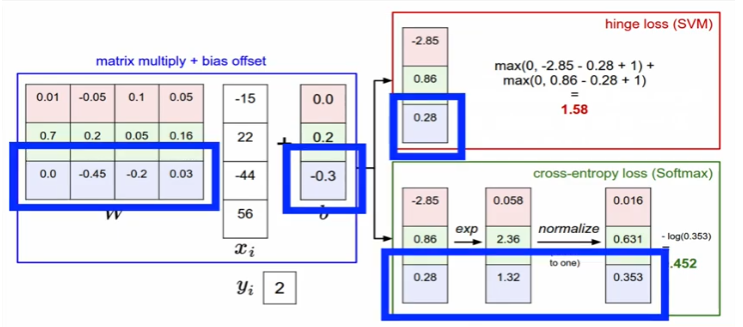
hinge는 1.58 / cross는 0.452
실제로는 softmax loss가 많이 쓰임
softmax VS SVM

score가 변할 때
-> SVM은 수식처럼 뒤에 1을 추가하기에 매우 둔감함
-> Softmax는 확률을 취할 때 모든 데이터를 보기 때문에 매우 민감함
'딥러닝 > Deep Learning' 카테고리의 다른 글
| [cs231n] 4강 리뷰 - backpropagation (0) | 2022.12.28 |
|---|---|
| [cs231n] 3강 리뷰 - optimization (0) | 2022.12.28 |
| [cs 231n] 2강 리뷰 - Image classification pipeline (0) | 2022.12.27 |
| SSH 원격 서버 사용과 도커 연결하기 with pycharm (0) | 2021.05.13 |
| Deep Learning - 신경망과 활성화 함수 (0) | 2021.02.09 |

최근댓글