optimization이란?
- loss를 minima하는 weight를 찾아가는 과정
loss function 정리

regurization loss는 data랑 상관없이 weight에만 영향을 받음
optimization의 그림 설명

- 산속에서 눈을 가리고 최적의 곳을 찾아가는 과정
optimizatation 전략 1. Random search

1000번을 돌리는데 랜덤하게 선택
-> 절대 쓰면 안 됨
전략2. Follow the slope=gradient(경사)

1차원일 때 수치적으로 미분을 통해 기울기를 구함
수식에 대입한다면?

- gradient가 음수라는 것은 기울기가 내려가는 방향으로 설정됨
- 두 번째 값으로 하면 0.6이 나옴 => 위쪽으로 나오는 기울기
미분(numerical)을 한다는 것은?
- 근사치/정확한 값이 아님
- 평가를 하는 과정이 매우 느림
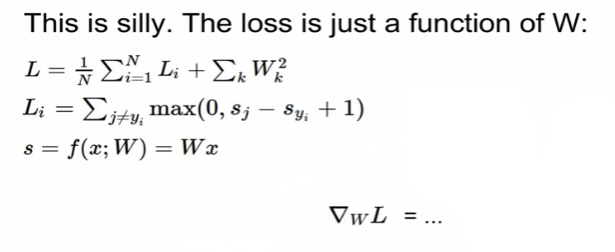
loss는 기본적으로 weight의 function
- weight가 변할 때 loss가 어느정도 변하냐 -> 미분을 사용하는 이유
analytic gradient(언제나 사용함)
- 빠르고 정확함
gradient descent의 코드
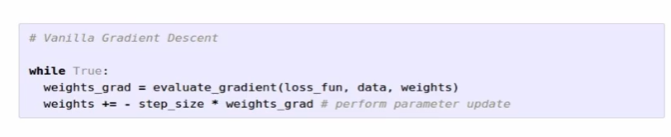
loss fun, data, weight로 gradient를 구하고, step size(lr)를 곱한 후 기존 weight에서 빼줌

full-batch gradient descent : training set 전체를 사용
mini-batch '' : training set의 일부만을 활용 -> 효율적 (size = 32/64/128/256), cpu/gpu의 환경에 따라 설정
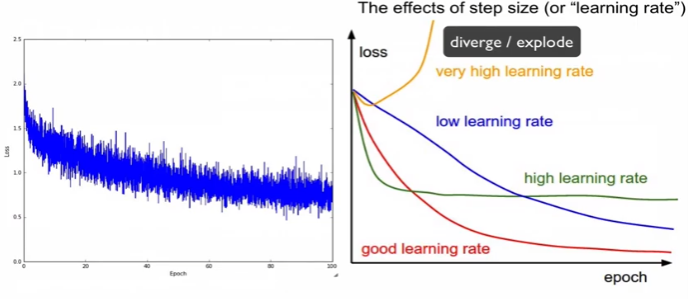
mini-batch는 loss가 많이 튐(적은 데이터만을 사용하기에)
적절한 lr를 설정해야 함.
decay : lr를 점점 낮춰가는 것
이미지를 분류한다는 것
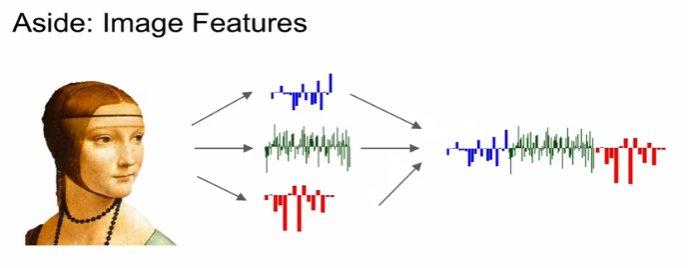
feature 추출 -> concat -> linear classifier에 적용
example : color histogram
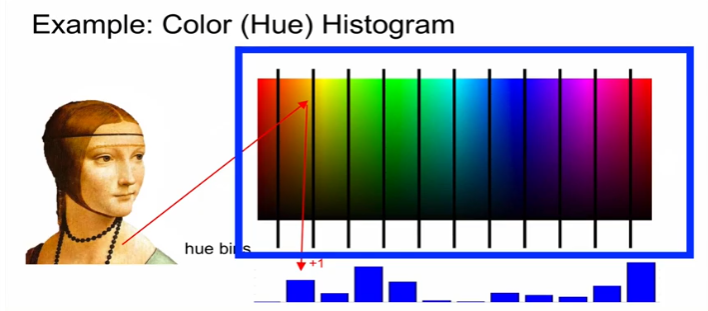
모든 pixel의 color 파악 -> 각 color의 bin이 몇 개인지 -> 이미지 내의 각 bin에 해당하는 pixel이 몇개인가
example : hog/sift features

edge 방향을 구분해서, 방향에 몇 개가 속하는가
example : bag of words
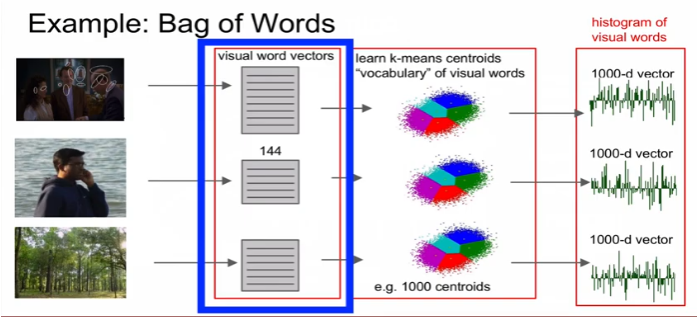
주파수 등을 통해 vector로 표현, 가장 유사한 words를 추출해서 vector 적용
전통적 방식(feature 추출) vs 딥러닝(이미지 자체를 함수에 던져줌)
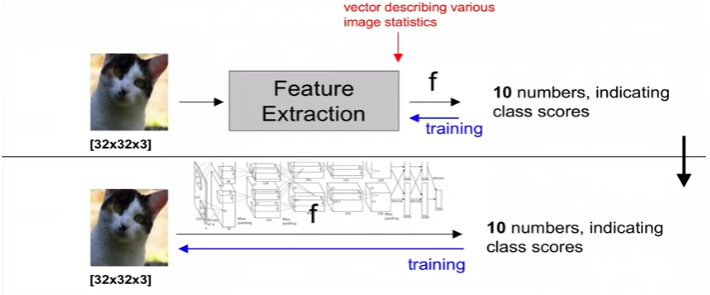
- 딥러닝에서는 feature 추출할 필요가 없음
'딥러닝 > Deep Learning' 카테고리의 다른 글
| [cs231n] 4강 리뷰 - backpropagation (0) | 2022.12.28 |
|---|---|
| [cs231n] 3강 리뷰 - loss function (1) | 2022.12.28 |
| [cs 231n] 2강 리뷰 - Image classification pipeline (0) | 2022.12.27 |
| SSH 원격 서버 사용과 도커 연결하기 with pycharm (0) | 2021.05.13 |
| Deep Learning - 신경망과 활성화 함수 (0) | 2021.02.09 |

최근댓글