지난 시간 배운 것

score function와 loss function, regularization의 효과
-> 가중치가 변함에 따라 loss가 얼마나 변하는지(미분=gradient)
optimaization : loss를 최소화하는 w를 찾아가는 과정

역전파의 효과 : 학습을 함에 있어서 각 vector가 얼마정도의 영향을 주는지 알아보는 과정


z의 값을 h만큼 증가시킨다면 f의 값은 3만큼 늘어난다. 3배만큼 영향력을 주고 있다.
Chain Rule

df/dy 는 바로 구할 수 없음. 오른쪽과 같이 식의 곱으로 나타낼 수 있음. (-4 x 1)
dq/dy는 df/dy에 직접적으로 영향을 주기에 local gradient라고 함. df/dq는 global gradient

local gradient와 backward gradients를 곱해줌으로써 최종 gradient를 구할 수 있음.

sigmoid function은 미분하면 자기 자신으로 표현이 됨. 그러므로 sigmoid gate를 다 거치지 않고 미분을 한 수식에 대입해서 local gradient를 구할 수 있음.
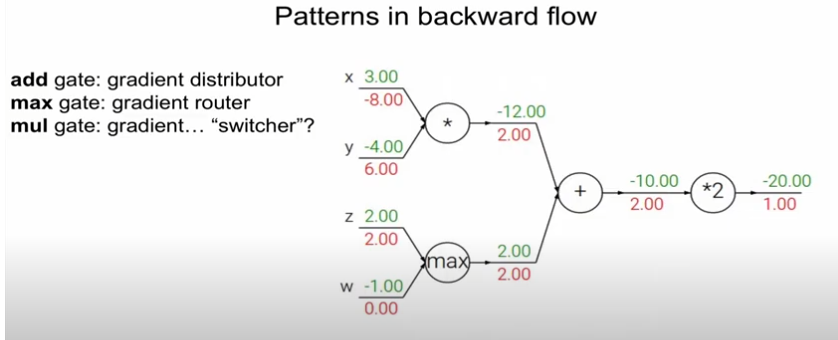
+ gate : gradient를 온전히 전해주는 기능
max gate : 큰 놈만 gradient를 전해주는 기능
mul gate : gradient를 switcher(교환)하는 기능

코드 구현 예시
Neural Network

NN은 activation function을 거침 (기능 : linear -> nonlinear하게 만듦)
hidden layer의 기능은 feature라고 보면 됨. ex) car사진에서 앞쪽의 빨간색 부분을 담당하는 특징
하나의 class에 대해 여러개의 classify가 존재 (paramatic apporach)
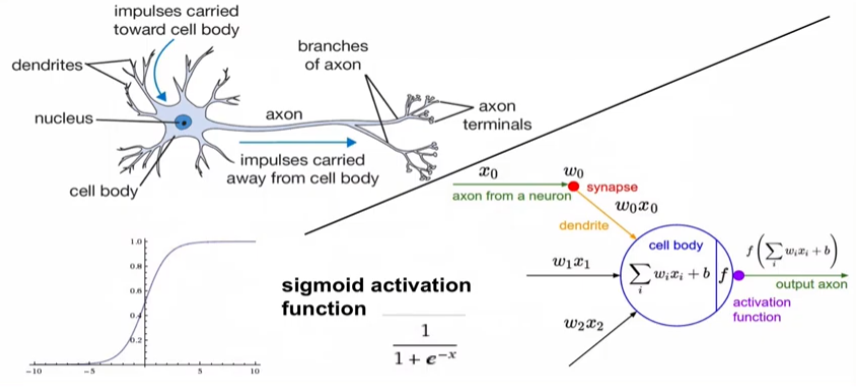
input vector와 weight 곱 -> cell body (sum) -> activation (non-linear) -> output (next neuron)
sigmoid activation : 특정 뉴런의 확률값을 0~1 사이로 특정해주기 쉬움
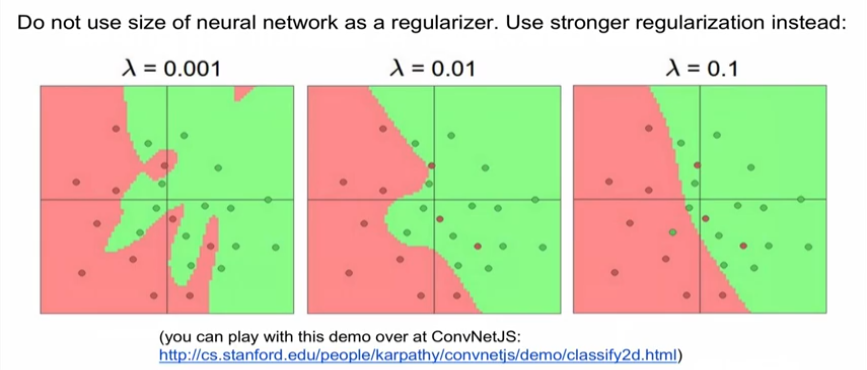
data의 과적합을 방지하기 위해서는 network를 작게 만드는 것이 아니라 규제 값을 더 높여줘야 한다.
네트워크는 크면 클수록 좋다.
'딥러닝 > Deep Learning' 카테고리의 다른 글
| [cs231n] 3강 리뷰 - optimization (0) | 2022.12.28 |
|---|---|
| [cs231n] 3강 리뷰 - loss function (1) | 2022.12.28 |
| [cs 231n] 2강 리뷰 - Image classification pipeline (0) | 2022.12.27 |
| SSH 원격 서버 사용과 도커 연결하기 with pycharm (0) | 2021.05.13 |
| Deep Learning - 신경망과 활성화 함수 (0) | 2021.02.09 |

최근댓글