1. DataFrame의 특징
2차원 데이터 구조로 index가 row와 column으로 구성되어 있다.
- column들이 서로 다른 타입일 수도 있다.
- 크기는 변할 수 있다.
- row는 각 개별 데이터를, column은 각 개별 속성(feautre)을 의미한다.
- row와 column에 산술 연산을 수행할 수 있다.
import pandas as pd
pandas.DataFrame
판다스 DataFrame은 다음과 같은 생성자를 사용해서 만들어진다.
| pandas.DataFrame( data, index, columns, dtype, copy ) | |
| data | ndarray, series, map, lists, dict, 상수 그리고 또 다른 DataFrame까지 변수의 형태로 가질 수 있다. |
| index | row 레이블의 경우, 인덱스 값이 없으면 0-based index (np.arange(n))가 기본으로 사용된다. |
| columns | column 레이블의 경우, 인덱스 값이 없으면 0-based index (np.arange(n))가 기본으로 사용된다. |
| dtype | 각 column 마다 데이터 유형을 나타낸다. |
| copy | 이 속성의 기본값이 False인 경우 데이터 복사에 사용된다. |
2. DataFrame의 구조
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('./train.csv')
train_data.head()
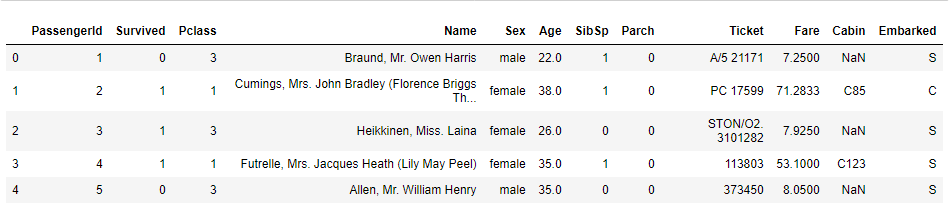
인덱스 (index)
- index 속성은 각 아이템을 특정할 수 있는 고유의 값을 저장한다.
- 복잡한 데이터의 경우, 멀티 인덱스(index가 2개, 3개 ....)로 표현 가능하다.
- index 속성을 이용해 다른 DataFrame를 생성할 때 index를 재사용 할 수 있다.
>>> train_data.index
RangeIndex(start=0, stop=892, step=1)
컬럼 (column)
- column 속성은 각각의 특성(feature)을 나타낸다.
- 복잡한 데이터의 경우, 멀티 컬럼(column이 2개, 3개 ....)로 표현 가능하다.
>>> train_data.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')
3. DataFrame의 데이터 파악하기
DataFrame.head()
# 데이터를 전체가 아닌 처음부터 5번째 열까지 간단하게 보기 위한 함수 (default: n=5)
# 출력하고 싶은 데이터 양을 늘리고 싶으면 n 속성 값을 지정하면 된다.
>>> train_data.head()
DataFrame.tail()
# 데이터를 전체가 아닌 마지막 5개를 간단하게 보기 위한 함수 (default: n=5)
# 출력하고 싶은 데이터 양을 늘리고 싶으면 n 속성 값을 지정하면 된다.
>>> train_data.tail()

DataFrame.shape
# 데이터의 형태를 알려준다. (row, column)
>>> train_data.shape
(891, 12)
DataFrame.describe()
# 숫자형 데이터의 통계치를 계산해준다.
>>> train_data.describe()

DataFrame.info()
# 각 column 마다 데이터 타입, 각 데이터의 아이템 개수를 출력해준다.
>>> train_data.info()

위 자료를 보면 Age, Cabin, Embarked feature에 데이터 손실이 있다는 것을 알 수 있다.
728x90
반응형
'데이터 사이언스 메뉴얼 > pandas' 카테고리의 다른 글
| 파이썬 Pandas NaN 데이터 처리하기 (0) | 2020.03.17 |
|---|---|
| 파이썬 Pandas DataFrame column 추가 / 삭제하기 (0) | 2020.03.16 |
| 파이썬 Pandas Data 선택하기 (0) | 2020.03.12 |
| 파이썬 Pandas DataFrame 생성하기 - 2 (0) | 2020.02.29 |
| 파이썬 Pandas DataFrame 생성하기 - 1 (0) | 2020.02.28 |

최근댓글