사이킷런에서는 분류를 위한 결정트리 클래스인 DecisionTreeClassifier와, 회귀를 위한 결정트리클래스인DecisionTreeRegression을 제공한다.
두가지 클래스는 다음의 하이퍼파라미터를 동일하게 제공한다. 대부분의 알고리즘이 직면한 문제가 과적합인 만큼 결정트리의 하이퍼 파라미터 외에도 대부분의 머신러닝 알고리즘들의 하이퍼 파라미터는 과적합을 제어하기 위한 목적으로 설정해준다고 생각을 하면 이해하기 쉽다.
결정트리 하이퍼 파라미터
- min_samples_split :
노드를 분할하기 위한 최소한의 샘플 데이터 수. -> 과적합을 제어하는 데 사용됨.
디폴트는 2이고 작게 설정할수록 분할되는 노드가 많아져서 과적합 가능성 증가
과적합 제어. 1로 설정할 경우 분할되는 노드가 많아져서 과적합 가능성 증가.
- min_samples_leaf :
말단 노드가 되기 위한 최소한의 샘플 데이터 수.
min_samples_split와 유사하게 과적합 제어용도. 그러나 비대칭적 데이터의 경우,
특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요
- max_features :
최적의 분할을 위해 고려할 최대 피처의 개수 ,
디폴드는 None으로 모든 피처를 사용하여 분할 수행
int형 지정 -> 피처의 개수
float 형 지정 -> 피처의 퍼센트
'sqrt' -> 전체 피처의 개수의 제곱근
'auto' = 'sqrt'
'log' -> log2(전체피처의 개수)
- max_depth :
트리의 최대 깊이를 규정
디폴트는 None - 완벽하게 클래스 결정값이 될 때까지 계속.
깊이가 깊어지면 min_samples_split 설정대로 최대 분할하여 과적합할 수 있으므로 적절한 제어가 필요
- max_leaf_nodes :
말단 노드(Leaf)의 최대 개수
결정 트리 모델의 시각화
Graphviz라는 패키지를 사용하여, 결정트리의 구조를 시각화 할 수 있다.
Graphviz 설치 방법
1.
https://graphviz.gitlab.io/_pages/Download/Download_windows.html
Redirecting…
graphviz.gitlab.io
홈페이지에 들어가 스크린 샷에서 마우스 커서가 가리키고 있는 Stable Windows install packages를 클릭한다.
그렇게 되면 현재 아직 완성된거 같지 않은 페이지가 나타나는데,
'10/' -> 'msbuild/' -> 'Release/'-> 'Win32/'를 클릭하여 들어가 준 후에 .msi파일을 다운로드 받는다.
(64비트 운영체제를 사용하더라도 해당 파일을 다운받으면 된다.)
다운로드 받은 후에는 파일을 클릭하여 바로 설치를 해준다.
2.
Anaconda prompt를 열어서 conda install graphviz로 Graphviz의 파이썬 래퍼 모듈을 다운받는다.
3.
1. 에서 설치한 파일은 C:\Program Files(x86)\Graphviz2.38라는 디렉토리에 설치된다.
Graphviz와 파이썬 래퍼를 연결하기 위해서는 컴퓨터 환경 변수 설정에서 설정을 해주어야 한다.
환경 변수 설정에 들어가면 변수 목록이 크게 2개로 나뉘어져 있다.
위쪽 환경 변수 설정(user에 대한 사용자 변수)에 기존에 있는 Path라는 변수에 편집을 누르고
C:\Program Files(x86)\Graphviz2.38\bin을 추가해준다.
아래쪽 환경 변수 설정(시스템 변수)도 마찬가지로 Path라는 변수에 편집을 누르고
C:\Program Files(x86)\Graphviz2.38\bin\dot.exe를 추가한다.
4.
이후에 주피터 노트북을 재가동 하면 graphviz 프로그램을 사용할 수 있다.
결정트리 시각화
결정트리 시각화에 예제 데이터 세트로 사용되는 데이터는 이전에 포스팅에서 다루었던 iris_data이다.
사이킷런에서 Graphviz와 관련된 API를 export_graphviz()라는 함수로 제공한다.
해당 함수에는 학습이 완료된 estimator, 피처의 이름 리스트 , 레이블 이름 리스트를 입력하면 시각화해준다.
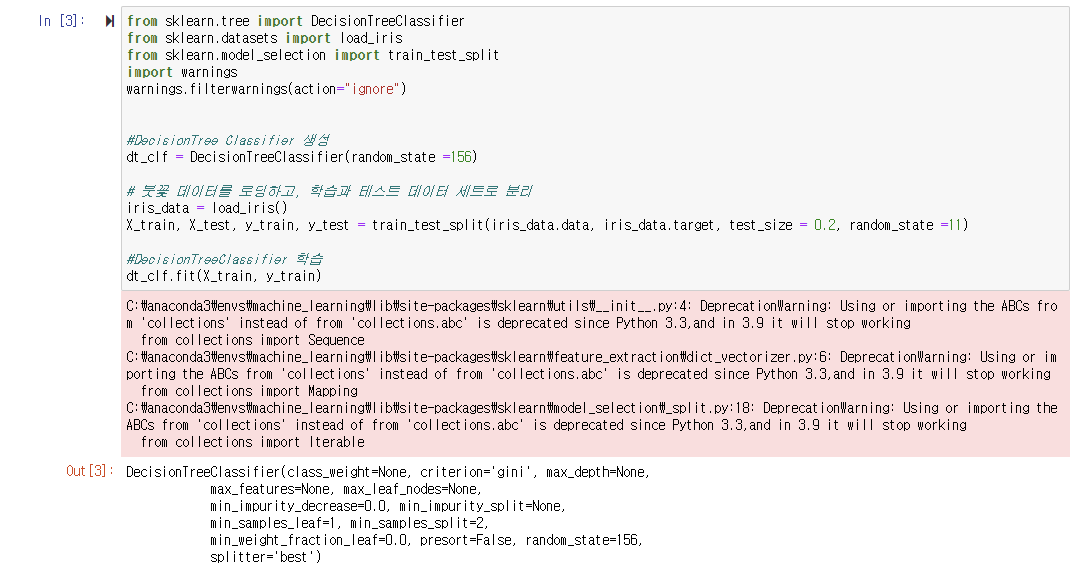
결정트리 객체를 불러오고, 데이터를 학습 데이터 세트와 테스트 데이터 세트로 분리한다.

export_graphviz를 import 하고 위에서 언급했던 요소들을 인자로 넣어준다. 그리고 out_file을 "tree.dot"이라는 파일명을 통해 저장한다.

이후, "tree.dot"파일을 열고 graphviz.Source() 함수를 통해서 파일을 실행한다.
그 결과,
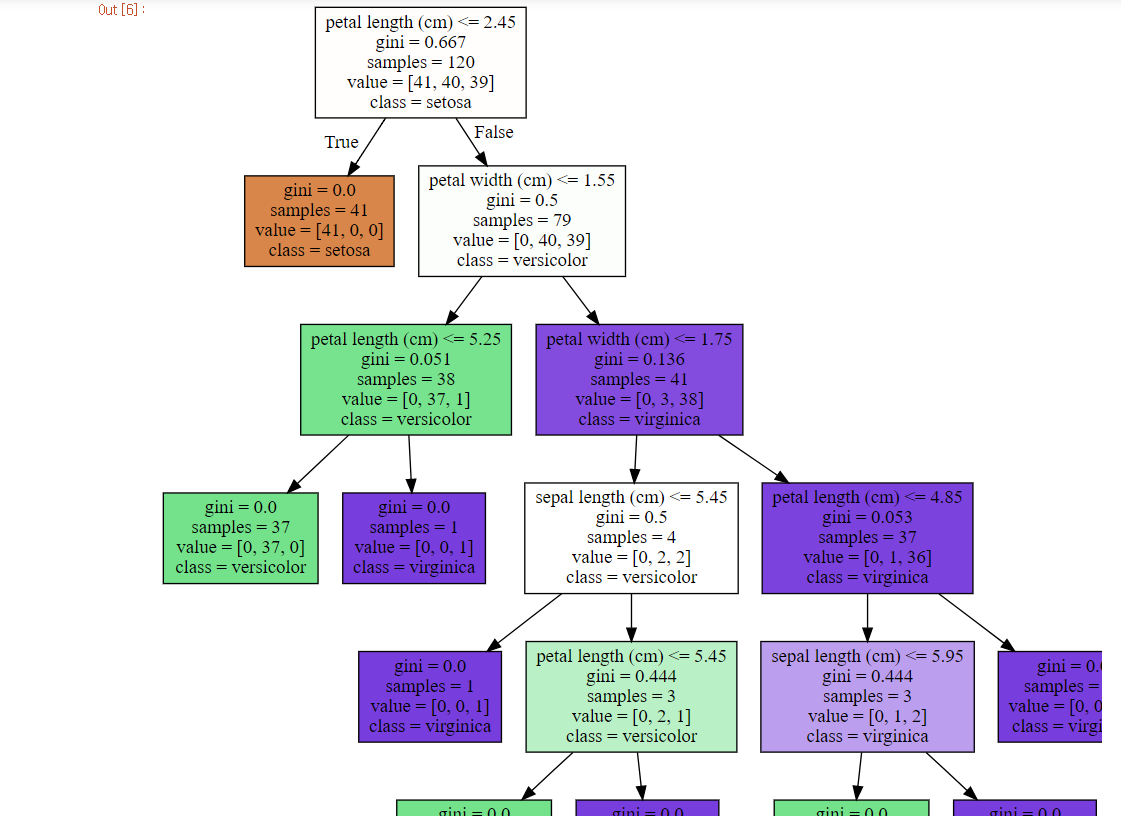
각 노드의 가장 위에 있는 조건식은 자식노드를 분리하는 기준을 적어놓은 것이고,
2번째 줄은 지니계수(균일도를 측정하는 수치)
3번째는 해당 노드에 존재하고 있는 데이터의 개수
4번째는 현재 레이블의 종류가 3가지가 존재하는 데, 각 노드에 존재하는 레이블마다의 데이터 개수를 리스트 형태로 표현한 것이다.
마지막은 해당 노드가 가장 많이 가지고 있는 레이블을 표현한다.
각 클래스마다 (주황색, 초록색, 보라색) 별도의 색을 가지고 있고, 균일도가 높을수록 색이 진한 것을 볼 수 있다. 즉, 지니 계수가 낮을수록 색의 진한 정도가 강해진다.
'기계학습 > Machine Learning' 카테고리의 다른 글
| [파이썬 머신러닝 완벽가이드] : 사이킷 런 앙상블 러닝 ( Boosting ) (0) | 2020.08.21 |
|---|---|
| [파이썬 머신러닝 완벽가이드] : 사이킷 런 앙상블 러닝 ( Voting / Bagging ) (0) | 2020.08.19 |
| [파이썬 머신러닝 완벽가이드] : 사이킷 런 앙상블러닝, 결정 트리 (0) | 2020.08.10 |
| [파이썬 머신러닝 완벽가이드] : 사이킷 런 평가지표 (F1 Score, ROC&AUC) (0) | 2020.08.07 |
| [파이썬 머신러닝 완벽가이드] : 사이킷 런 평가지표 (정밀도, 재현율) (0) | 2020.08.06 |

최근댓글