NLP 논문리뷰
논문제목 : Enriching Word Vectors with Subword Information
논문링크 : arxiv.org/abs/1607.04606
1. Abstract & information

기존 모델은 단어마다 다른 벡터를 할당하여 단어의 형태를 무시한다.

위와 같은 문제점을 해결하기 위해 Skip-gram을 기반으로 한 모델에 각 단어를 character n-gram 벡터의 조합으로 표현하였다.

그랬더니 학습 속도가 빠르고, 학습 데이터에 등장하지 않은 단어도 표현이 가능해졌다.

9개 언어에 대해 단어 유사도 및 추론 태스크를 통해 평가했더니 SOTA(state-of-the-art)를 달성하였다.

기존 모델은 parameter를 공유하지 않는 다른 벡터로 단어를 표현하였다. 그랬더니 형태학적으로 복잡한 언어는 잘 표현하지 못하였다. ex) Turk-ish, Finnish

단어의 형태가 일정한 룰을 따르고 있으나 철자 단위 정보를 사용하여 더 좋은 단어 표현을 만들기로 하였다.
2. Related work
X
3. Model
3.2 Subword model

where -> <where>과 같이 단어의 양 끝에 <,>를 더하여 접두사와 접미사를 구분할 수 있도록 했다.

n은 3<=n<=6의 범위 n-gram을 사용하였고, 위 그림과 같이 wh, whe, her, ere, re처럼 단어가 분리된다.

단어를 n-gram 벡터의 합으로 나타냈고, 단어 간에 표현을 공유하도록 하여 희소 단어도 의미 있는 표현을 배웠다. 예를 들면 eat, eating, eats와 같이 eat라는 원래 단어에서 파생된 단어들의 표현을 공유함으로써, 학습시켰다.
4. Experimental setup
4.4 Datasets

데이터셋은 wikipedia에서 다운로드 하였고 Arabic 등 9개 언어를 사용하였다.
5. Results
5.1 Human similarity judgement

Baseline model로 sg, cbow, sisg-(OOV에 대해 nul vector로 표현), sisg(n-gram 벡터의 합으로 표현)의 성능을 비교하였는데 sisg가 Arabic, German, Russian에서 더 좋은 성능을 보였다. 즉 형태적으로 복잡하거나 합성어가 많은 언어에서 성능 개선이 더 많이 일어난 것으로 볼 수 있다. (+ RW > WS353)

위 4개의 언어에서 구조적(Syntactic)인 추론이 의미적(Semantic)인 추론보다 기존 모델에 비해 더 뛰어난 성능 향상이 있었다.
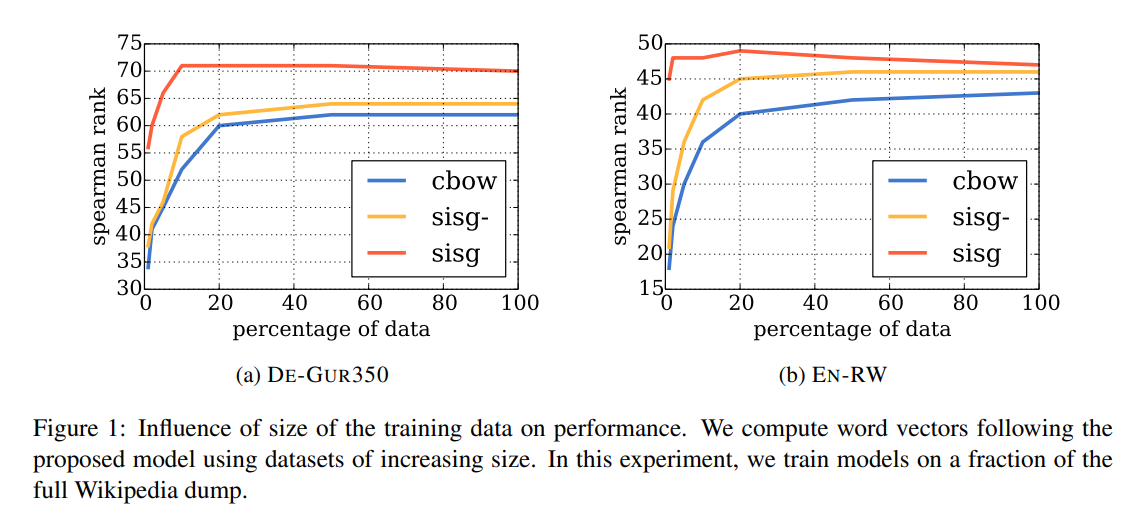
데이터가 적을 때(전체 데이터의 1~20%), 확실히 이전 모델보다 더 좋은 성능을 보였다.

Syntactic task에서는 작은 n을 고려할 때 성능이 더 좋고, Semantic task에서는 큰 n만 고려할 때 성능이 더 좋다.

모든 언어에서 다른 모델보다 더 좋은 성능을 보였다. 특히 Vocab size가 큰 슬라브 언어(Czech, Russian)에서 Perplexity의 감소폭이 두드러진다.
6. Quanlitative analysis

코사인 유사도를 사용하여 주어진 단어와 가장 유사한 단어 2개를 뽑은 테이블.
sisg(subword information + skip-gram)가 sg(skip-gram)보다 구조(형태)적으로 유사한 단어를 더 찾아줌.
tech-rich라는 단어를 봤을 때 → tech-dominated, tech-heavy(sisg)이고 / technology-heavy, .ixic(sg) 의미적으로는 sg가 유사할 수 있지만 구조(형태)적으로 봤을 때 sisg가 매우 유사하다.

주어진 단어에서 가장 중요한 3개의 character n-gram을 추출한 결과
→ 합성 명사와 접두사 접미사를 잘 표현함
ex - autofahrer → auto + fahrer
kindness → kind + ness>
starfish → star + fish
결과를 봤을 때, 중요한 단어들이 n-grams에 다 표현됨.

X축 : OOV(등장하지 않은 단어)
Y축 : 학습 데이터 셋 내 단어
X, Y축 사이의 character n-gram 유사도 → 비슷한 뜻을 가진 단어들끼리 유사도가 높은 것(짙은 빨강)을 볼 수 있다.
"pav-", "-sphal-" : (아스팔트) 포장
"young", "adoles" : 어린(이)
7. Conclusion
기존 skip-gram 기반의 단어 표현에 character n-gram으로 subword information을 넣어봤을 때, 성능이 더 좋고 형태(구조)적 분석에 의존한 방법임을 알 수 있다.
'딥러닝 > 자연어처리' 카테고리의 다른 글
| Transformer - Attention is All you need (0) | 2021.04.08 |
|---|---|
| NLP논문리뷰 - ELMo (Deep contextualized word representations) (0) | 2021.03.31 |
| [파이썬으로 배우는 응용 텍스트 분석] 텍스트 분석 도구 (0) | 2021.02.18 |
| NLP(자연어처리) - 정규표현식 with python (2) (0) | 2021.02.11 |
| NLP(자연어처리) - 정규표현식 with python (1) (0) | 2021.02.10 |

최근댓글