import pandas as pd
train_data = pd.read_csv('./train.csv')
train_data.head()

Groupby 이해하기
모든 groupby 연산은 기존 객체에 대해 다음과 같은 연산 중 하나를 포함한다.
- 데이터 분할하기
- 데이터 연산하기 (통계적으로 계산, 조건에 맞는 데이터 걸러내기, 그룹별 작업 수행)
- 데이터 병합하기
1. 데이터 분할하기
1) groupby()를 이용한 데이터 분할
Pandas 객체를 분할할 때는 groupby() 메소드를 사용하며 인자로는 column이름이나 column으로 이루어진 리스트를 전달하면 된다.
class_group = train_data.groupby('Pclass')

class_group.groups

그렇게 만들어진 class_group의 속성을 살펴보면, class_group는 DataFrameGroupBy 객체이며 각 column과 column에 속한 index를 dict형태로 표현한 것을 알 수 있다. key는 해당 column의 카테고리이고, value는 key와 일치하는 값을 가진 row의 index이다. 다수의 column을 group하면 key는 각각의 column의 카테고리를 튜플 형태로 나타낸다.
class_and_gender_group = train_data.groupby(['Pclass', 'Sex'])
class_and_gender_group.groups

2) index를 이용한 데이터 분할
- set_index() : column 데이터를 index레벨로 변경
- reset_index() : index 초기화
set_index를 통해 우리가 원하는 column을 index레벨로 변경할 수 있다. column 들을 리스트 형태로 묶으면 다중 index를 만들 수 있다.
train_data.set_index(['Pclass', 'Sex'])

이렇게 만들어진 인덱스 레벨을 다시 원래 dataframe에 넣고 싶으면 reset_index를 사용하면된다. reset_index를 사용하면 index레벨에 있던 column이 dataframe으로 돌아가며, 그 위치는 맨 처음이 된다. 다중 index에서도 가능하다.
train_data.set_index(['Pclass', 'Sex']).reset_index()

이렇게 우리가 원하는 column을 index로 설정했으면, 우리는 groupby(level = int)를 통해 index를 기준으로 그룹핑 할 수 있다. 여기서 level은 index의 깊이를 의미하며 가장 왼쪽에서부터 0에서부터 1씩 증가한다. 앞에서 다수의 column으로 그룹핑 한 것처럼 level을 이용해서 다수의 column으로 그룹핑 할 수 있는데, 이때는 level을 리스트 형식으로 만들어 그룹핑 하고 싶은 column을 int형식으로 제공해주면 된다. (다중 index로 설정할 때 가장 중요하다.)
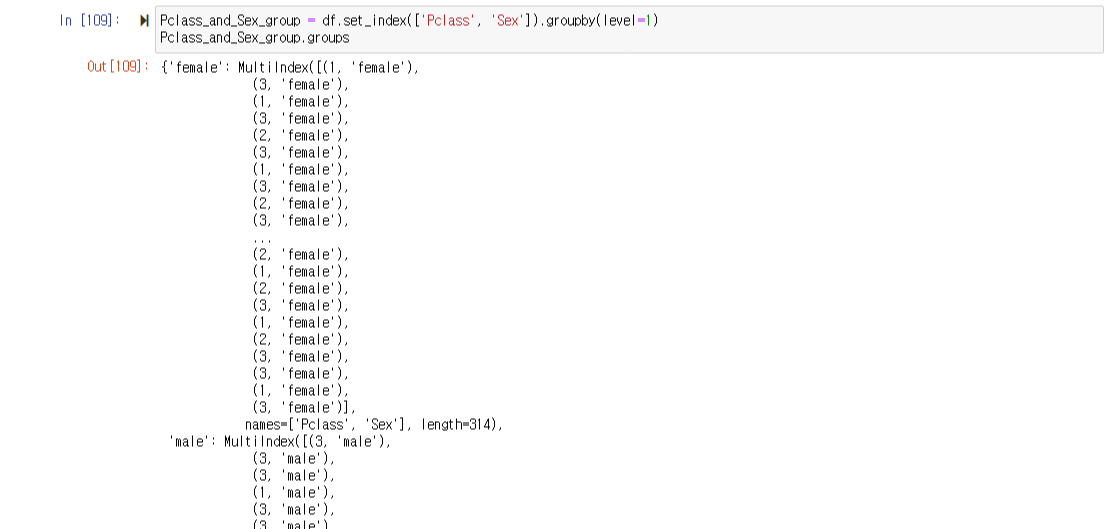
그룹핑할 때, level = 1로 설정했으므로 Pclass_and_Sex_group의 key 값은 Sex로 설정된다.
(만약, Pclass와 Sex로 그룹핑하고 싶으면 level = [0, 1]로 설정해 주면 된다. 이때, 순서에 따라 어떤 그룹으로 묶이는지 달라진다. 즉 level = [0, 1]과 level = [1, 0]은 다르다는 말이다.)
Pclass_and_Sex_group = df.set_index(['Pclass', 'Sex']).groupby(level=1)
Pclass_and_Sex_group.groups
2. 데이터 연산하기 -1)
1) 각종 함수 활용하여 연산하기
앞에서 각각의 column들을 그룹핑하였으면, 그룹핑한 객체를 기반으로 연산할 수 있는 다양한 함수들이 있다. 그 중에서 대표적인 10개만 나열해보았다. (NaN 데이터는 제외하고 연산한다.)
- count() : 그룹 내 Non-NA 갯수
- sum() : 그룹 내 Non-NA 들의 합
- min() : 최솟값
- max() : 최댓값
- mean() : 평균값
- std() : 표준편차
- var() : 분산
- first() : 그룹 내 Non-NA 값 중 첫번째 값
- last() : 그룹 내 Non-NA 값 중 마지막 값
- describe() : 그룹의 기술 통계량
다중 index를 활용한 연산
Pclass_and_Sex_group = train_data.set_index(['Pclass', 'Sex']).groupby(level=[0, 1])
Pclass_and_Sex_group.mean()

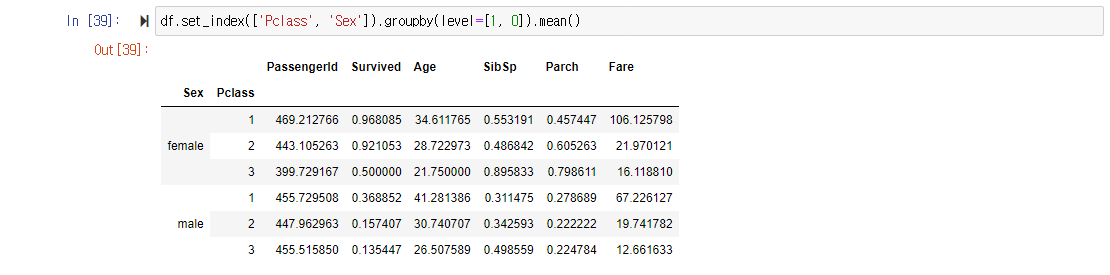
Pclass_and_Sex_group = train_data.set_index(['Pclass', 'Sex']).groupby(level=[1, 0])
Pclass_and_Sex_group.mean()
2) 연산하고 싶은 함수를 직접 만들어 활용하기: Aggregate(), Agg()
내장된 함수에 내가 원하는 연산의 함수가 없을 수도 있다. 보통 그럴 때는 내가 원하는 함수를 직접 만들어 사용하는데 이렇게 만든 함수를 agg() 혹은 aggregate()를 이용해서 dataframe에 적용시킬 수 있다.
Pclass_and_Sex_group = train_data.set_index(['Pclass', 'Sex']).groupby(level=[0, 1])
Pclass_and_Sex_group.agg([np.mean, np.sum, np.max])

'데이터 사이언스 메뉴얼 > pandas' 카테고리의 다른 글
| 파이썬 Pandas groupby 이해하고 활용하기 -3 (0) | 2020.04.06 |
|---|---|
| 파이썬 Pandas groupby 이해하고 활용하기 -2 (0) | 2020.04.06 |
| 파이썬 Pandas NaN 데이터 처리하기 (0) | 2020.03.17 |
| 파이썬 Pandas DataFrame column 추가 / 삭제하기 (0) | 2020.03.16 |
| 파이썬 Pandas Data 선택하기 (0) | 2020.03.12 |

최근댓글