
안녕하세요!!
삼성 SDS Brightics 서포터즈 3기 이상민입니다.
저번 포스팅으로
Brightics 서포터즈 3기 발대식 후기를 작성했었는데요
그 감동과 여운을 바탕으로
이번 포스팅은
주제를 정해 분석하는 개인 분석 프로젝트!!
주제 및 데이터셋 설명과 Data Load에 대해 작성하겠습니다 :)
주제 선정
아무래도 제가 가장 자신있는 분야이기도 하고
기존 연구실 경험을 살려 텍스트 데이터를 다뤄보는 주제로 선정하였습니다.
바로 '영화 리뷰 데이터 분석하기 with text analysis'라는 주제로
여러분들에게 친숙한
영화라는 데이터셋을 텍스트 데이터와 함께
분석해보는 시간을 가져보겠습니다.
텍스트 분석이란?
데이터의 유형에는 정형데이터, 이미지, 텍스트, 음성 등 여러 가지의 유형이 있고
텍스트라는 것은 말 그대로 글자를 뜻하는데요.
텍스트 분석은 텍스트 마이닝과도 유사한 의미로
고객의 리뷰 및 설문 조사를 분석하여
제품에 대한 만족도를 식별하는 데 사용됩니다.
데이터셋 수집
데이터셋은 kaggle에서 제공하는
imdb movies dataset을 활용하고자 합니다.
https://www.kaggle.com/datasets/harshitshankhdhar/imdb-dataset-of-top-1000-movies-and-tv-shows
imdb란 미국의 영화 정보 모음 사이트로
현재 아마존닷컴의 자회사입니다.
가장 큰 특징은 전 세계에서 가장 큰 영화 사이트로
영화부문 사이트 접속 순위 1위입니다.
데이터의 양이 가장 중요한 시대에서
imdb는 최고의 영화 데이터베이스를 가지고 있다고
볼 수 있겠죠??
데이터셋 Load
1주차에 봤던 친숙한 창이죠??
Brightics Studio에서 New를 클릭해
새로운 프로젝트를 생성해줍니다.
그 다음 우측에 있는 Palette를 눌러주는데요.
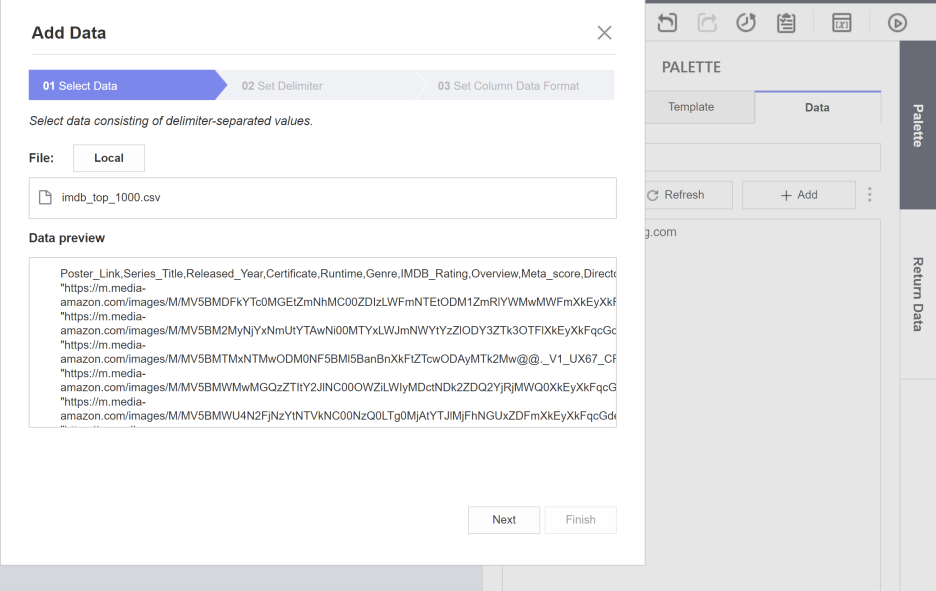
Palette를 클릭하고
Select Data에서 기존 local에 저장해놓은 데이터셋을 불러옵니다.
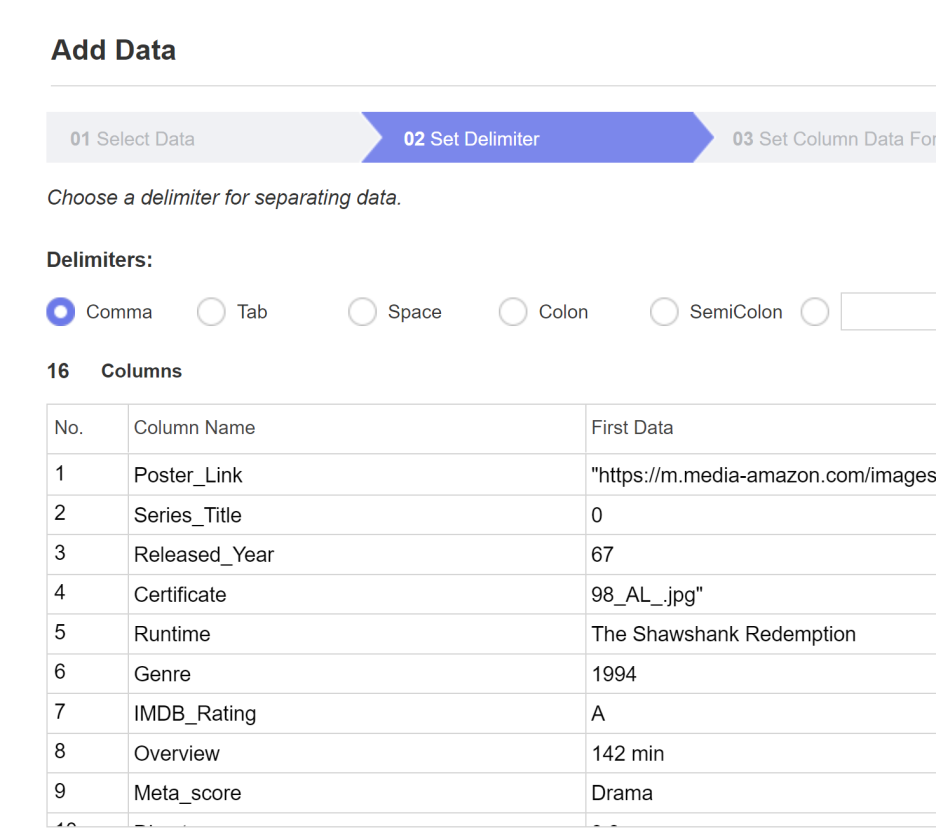
그 다음 두 번째 단계로
구분자를 선택해줘야 하는데요.
csv라는 데이터셋 특성상 comma를 기준으로
나눠지기 때문에 comma를 클릭하면
사진과 같이 자동으로 데이터를 나눠줍니다!
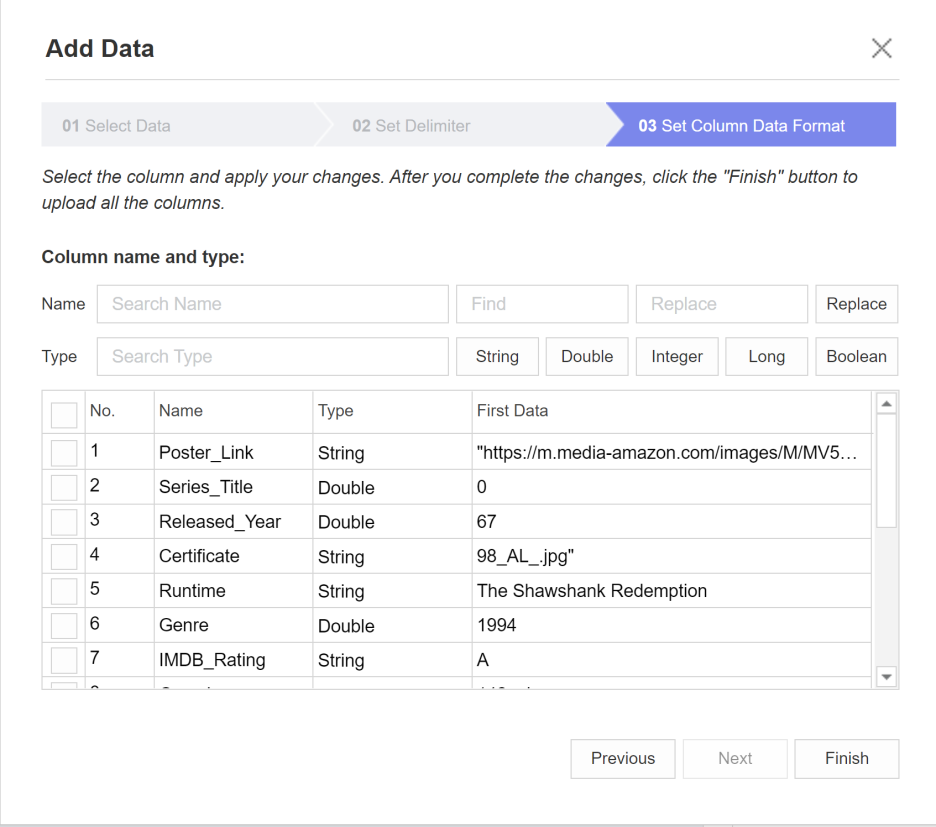
그 다음 마지막 단계로
column의 data type을 변경해줄 수 있는데요
저는 진짜 이 기능보고 깜짝 놀랐습니다..
원하는 column의 type을
변경하고자 하는 type으로 변환해주는 점이
굉장히 신기했어요
기존 python에서는 pandas라이브러리나
내장함수를 사용해서 변환해줘야 했는데
간편하게 load 단계에서 불러오는 것이 정말 편리했습니다.
하지만!!
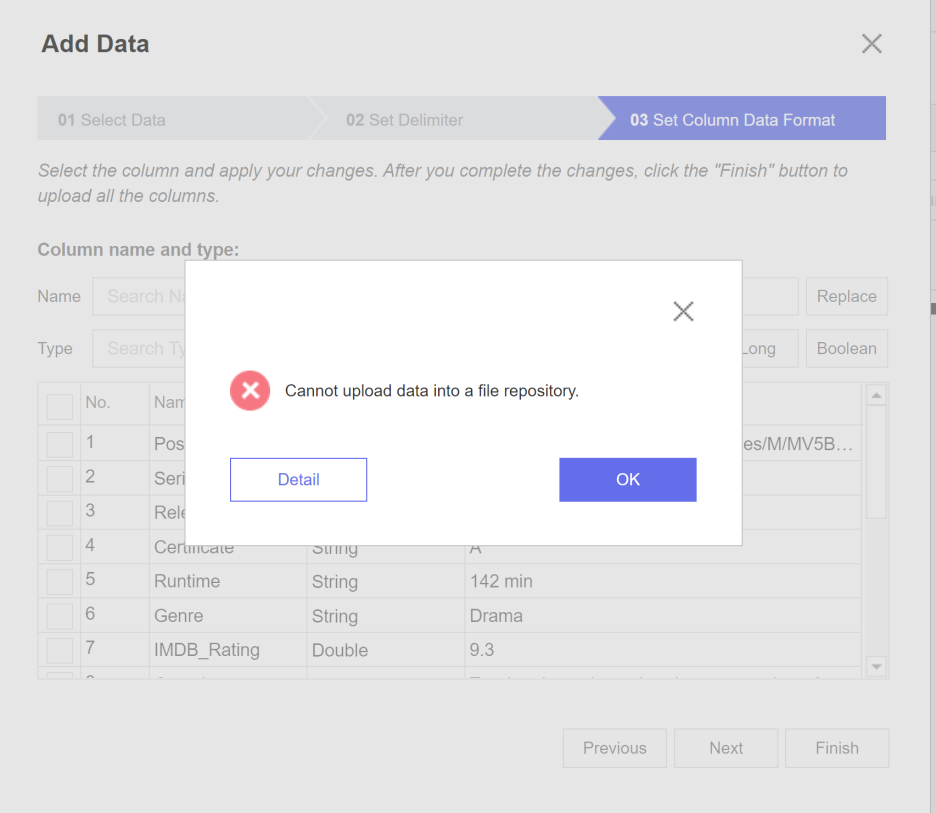
위와 같은 오류가 뜨게 되는데요..
이 때부터 난관에 봉착하게 됩니다.
detail을 클릭했을 때도 오류메시지만 뜰 뿐..
하지만 데이터분석가는 오류에 두려워하면 안 되겠죠?
바로 구글링을 검색합니다.
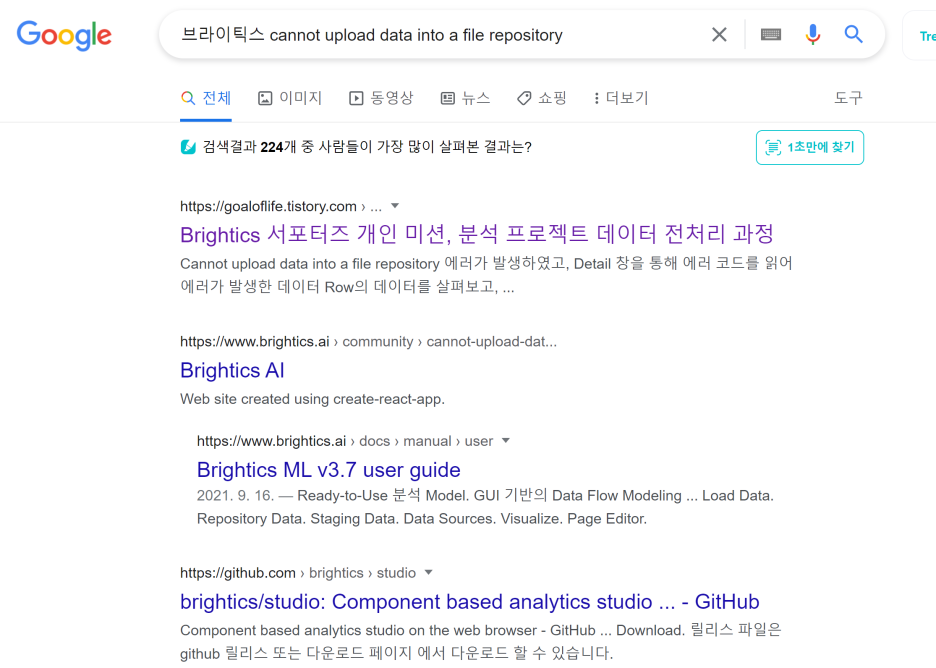
역시 선배 서포터즈 분께서도
같은 오류를 겪고 해결하셨는데요
정리하자면
1) " <- 쌍따옴표가 데이터에 들어가면 Load 오류가 난다.
2) 데이터에 ,가 있을 시 "가 자동으로 생긴다.
위와 같은 해결방법으로
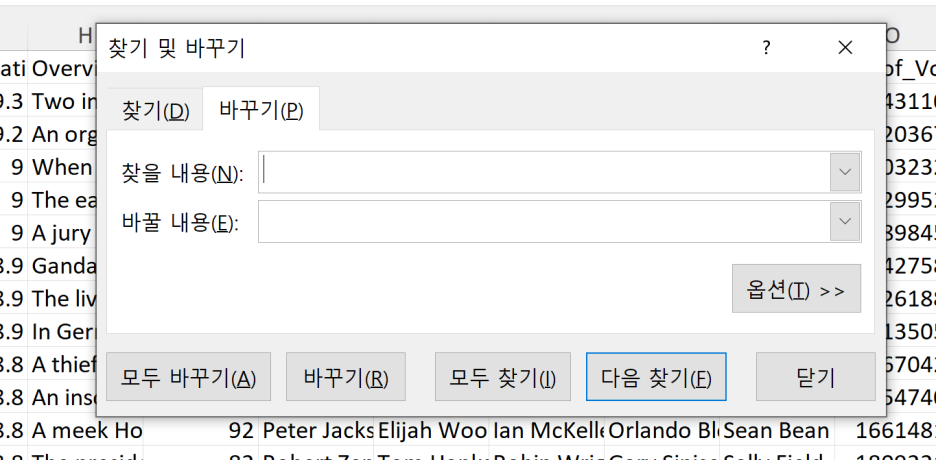
excel 창을 열고 찾기 바꾸기를 클릭한 후에
"를 먼저 제거해주고
,도 제거해줍니다.
그 결과!!
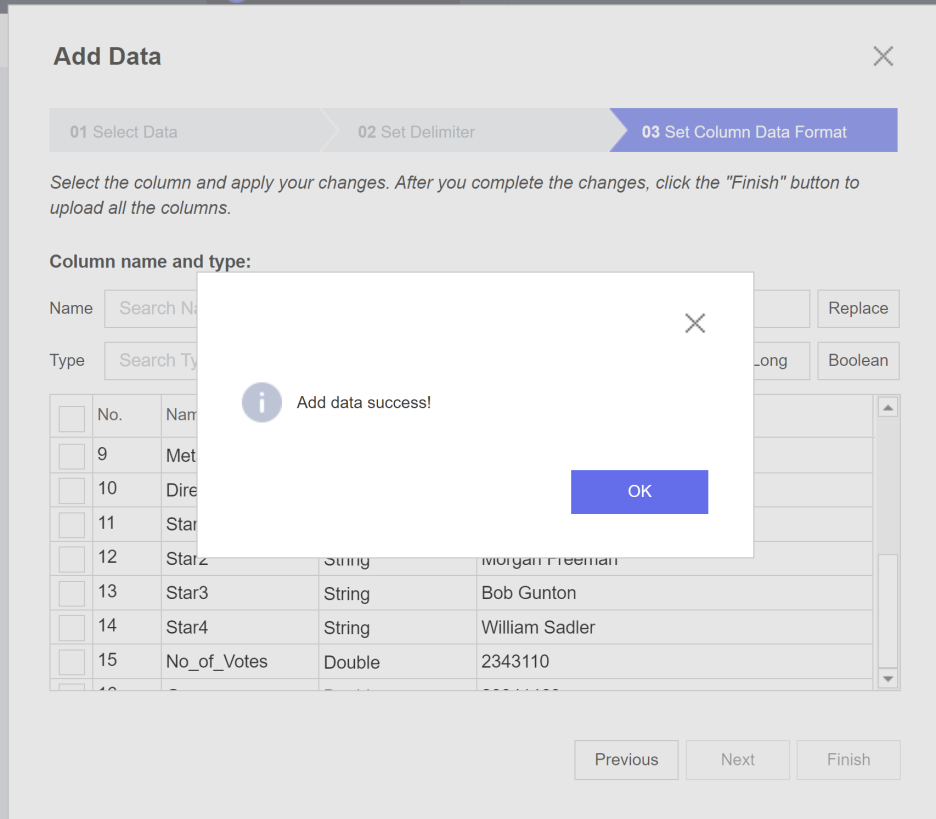
성공적으로 데이터를 불러왔습니다 :)
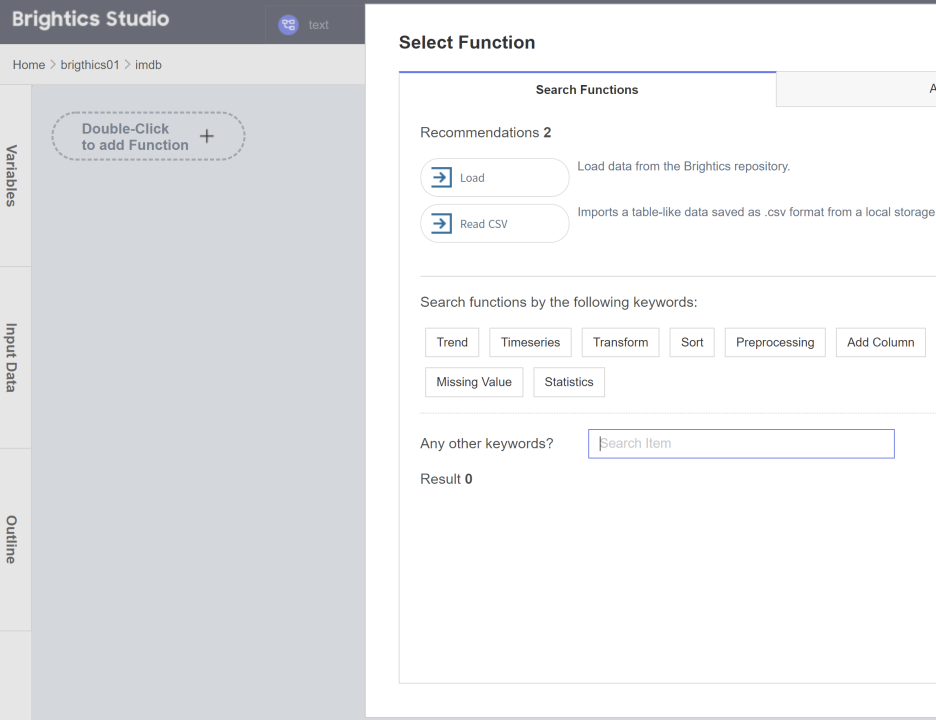
빈 템플릿에
마우스를 가져다 보면 +가 뜨는데요
해당 버튼을 클릭하면
Load와 Read CSV중에 고를 수 있습니다.
그 중 Load를 클릭하면 아래와 같이 뜨게 되는데요
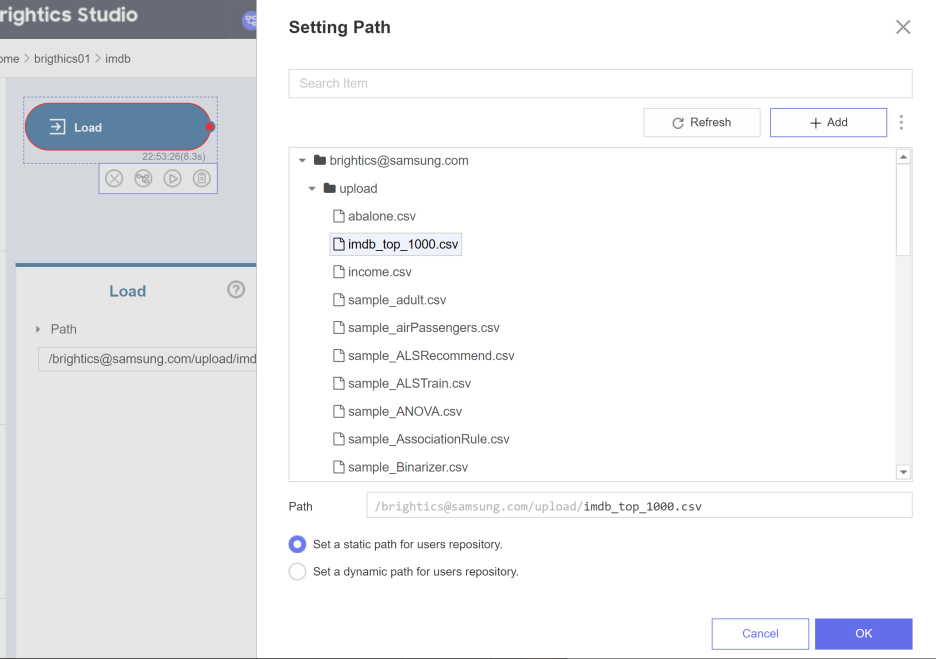
Path를 클릭하고
아까 불러왔던 imdb_top_1000.csv 데이터셋을
불러와줍니다.
기타 자료
브라이틱스 유튜브
https://www.youtube.com/channel/UCglq4GNV2E_RIEKYSDGvyPw
브라이틱스 AI 튜토리얼
https://www.brightics.ai/kr/docs/ai/manual/tutorial/index.html
2-1 데이터셋 설명과 데이터 로드 후기
브라이틱스 Data Load가 반이라는 말이 있는데요
텍스트 데이터를 불러올 때는
특히 더 조심해야 하는 것 같습니다.
각종 부호들이 인식이 안 될 수도 있으니
기본적으로 처리해주는 게 좋아요!!
하지만 Data를 불러오는 과정에서
불필요한 함수를 입력하지 않아도 되고
단계별로 체계적으로 불러오는 점이
브라이틱스만의 강점이라고 볼 수 있는데요
기존 python을 사용했던 사람으로서
정말정말정말 편리했습니다 :)
그럼 데이터를 불러왔으니
다음은 데이터 전처리에 대해 다뤄보겠습니다.
지금까지 삼성 SDS Brightics 서포터즈 3기 이상민이었습니다!
귀한 시간 내어 읽어주셔서 감사합니다.
* 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.

'삼성 SDS Brightics' 카테고리의 다른 글
| [Brightics Studio] # 팀 분석 프로젝트 - 01 기획 및 구상, 텍스트 데이터로 MBTI 예측하기 (0) | 2022.08.17 |
|---|---|
| [Brightics Studio] #02-3 영화 리뷰 데이터를 분석하기 - Modeling and Text Analysis (0) | 2022.07.12 |
| [Brightics Studio] #02-2 영화 리뷰 데이터를 분석하기 - Data Preprocessing (0) | 2022.07.05 |
| [삼성 SDS Brightics] 서포터즈 3기 발대식 후기 (0) | 2022.06.28 |
| [Brightics Studio] #01 코딩 없이 데이터 분석을 한다고?? 설치부터 체험까지! (0) | 2022.06.21 |
최근댓글