
computer vision 분야의 기본은 이미지를 분류하는 것 -> 개, 고양이, 강아지
기타 파생된 분야가 detection, segmentation, image captioning
분류를 하는데 semantic gap이라는 문제점이 생김

이미지는 기본적으로 height x width x channel의 곱으로 이루어짐 (여기서 channel이란 색상=RGB)
이미지의 도전과제
- Viewpoint Variation (보는 시각에 따라서 이미지가 다르게 보임)
- Illumination (조명)
- Deformation (형태의 변형)
- Occulusion (숨어있는 이미지)
- Background clutter (배경하고 구분이 안 되는 형체)
- Intraclass variation (비슷한 형태 간의 구분)
기본적인 이미지의 분류

함수의 input값으로 image를 넣으면 class label을 output으로 출력함
-> 하지만 이미지는 hard coding이 안 되는 단점

허나 rule-based(edge, 배열상태)로 비교하는 시도가 있긴 했음
이 점을 해결하고자 Data-driven apporach가 나옴

data와 label을 통해 학습을 시키고 test image set에 대해 학습시킨 것들을 평가함
+ model에 학습이라는 것이 추가된 것(image, label -> model 도출)
First Classifier : NN Classifier(거리기반 분류기)
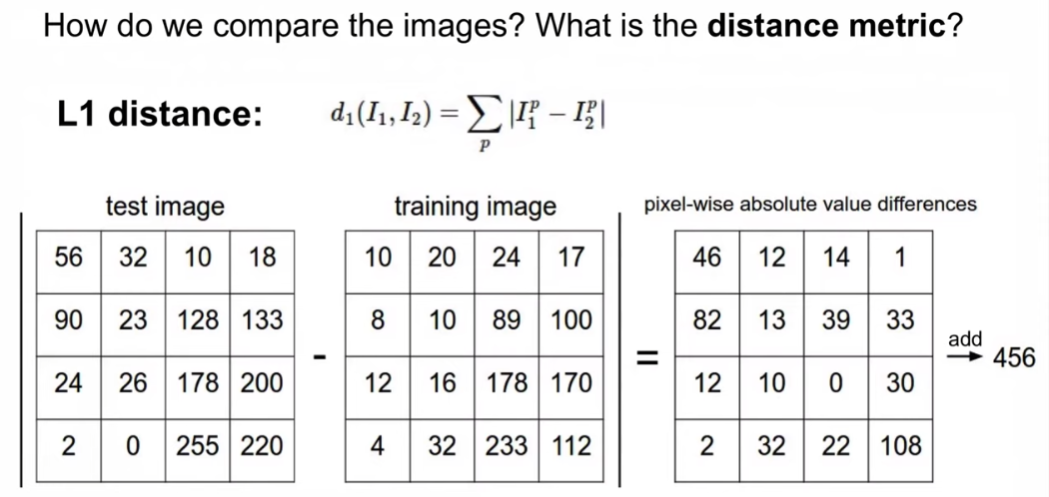
l1 distance로 제대로 분류했는지 판별함
l1 distance : 거리 차이의 절대값의 합(맨해튼 거리)
model 학습의 코드 - l1 distance가 가장 작은 image 셋을 찾는 것

Q. train data와 분류 작업은 linear한 관계가 있음(train data가 늘어나면 분류작업도 비례해서 늘어남)
최적의 하이퍼파라미터를 찾아야 함(distance)

k-NN : k개의 가장 가까운 이미지들을 찾아서, 보팅함

일반적인 NN Classifier로 train data를 평가척도로 삼으면 정확도 100%가 나옴(해서는 안 되는 것 - 비교를 위해)
하지만 k-NN으로 판단하면 k의 개수에 따라 정확도가 달라짐
best distnace는?
k개의 개수는?
-> 이런 것들은 하이퍼 파라미터
-> 하이퍼 파라미터는 여러 개를 실험해보고 퍼포먼스 비굥
하이퍼 파라미터 비교 실험
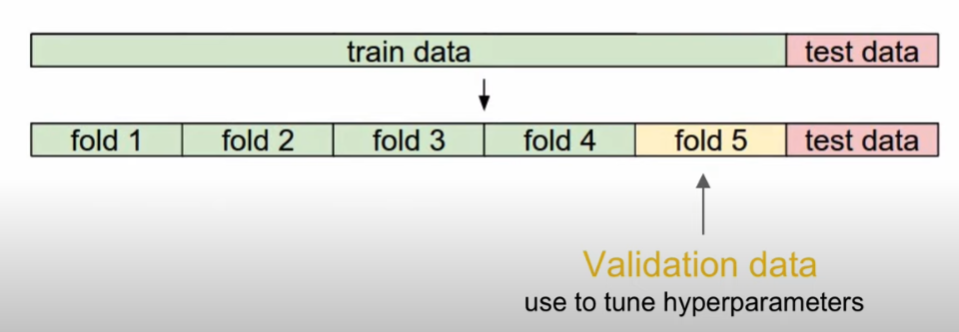
validation data를 따로 설정하여 하이퍼 파라미터를 체크함(test data는 건들면 안됨 -> 일반화 성능)
train data가 적으면 cross-validation (n번 반복해서 정확도 평균)

정확도가 가장 높은 값 -> k가 7

kNN은 거리기반이기 때문에 위 사진들이 모두 거리 값이 같게 나옴
Linear Classification

- 파라미터를 유추하는 것(W)
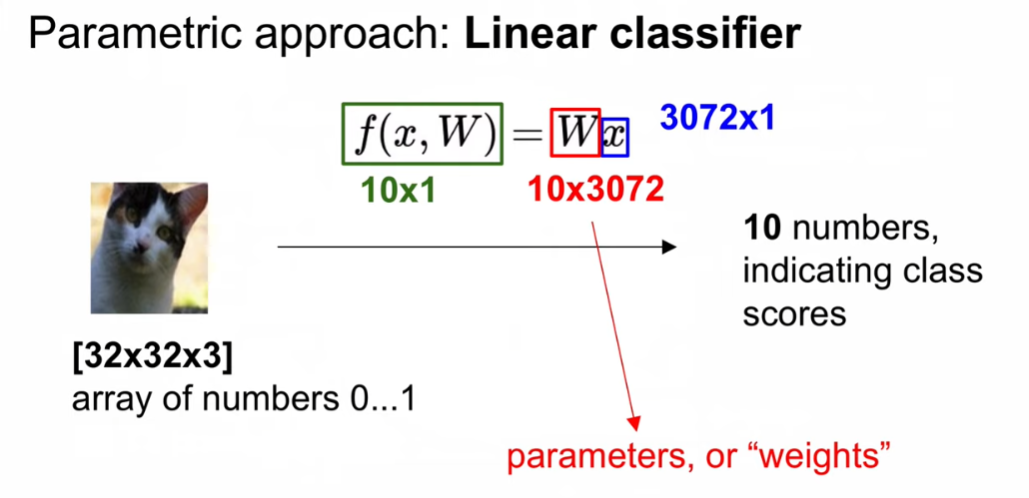
- weight의 차원은 맞춰줘야 함
- 10x1의 아웃풋이 나옴
- x는 image의 pixel 값
위와 같은 행렬 곱 형태

linear classifier의 의미 : weighted sum of image / 공간적 위치의 컬러를 카운팅

결국에는 데이터의 분산 공간을 분류하는 것
어려운 점
1) negative color(정반대의 색상) 구분
2) gray image 구분
3) 형태는 다르지만 색상은 동일

결국 우리가 한 것은 score function을 정의한 것
-> 점수를 기반으로 loss function을 정의해야 함(score가 어느정도 좋고 나쁘냐 정량화)
'딥러닝 > Deep Learning' 카테고리의 다른 글
| [cs231n] 3강 리뷰 - optimization (0) | 2022.12.28 |
|---|---|
| [cs231n] 3강 리뷰 - loss function (1) | 2022.12.28 |
| SSH 원격 서버 사용과 도커 연결하기 with pycharm (0) | 2021.05.13 |
| Deep Learning - 신경망과 활성화 함수 (0) | 2021.02.09 |
| Deep Learning - 신경망 학습과 손실 함수 (0) | 2021.02.03 |

최근댓글