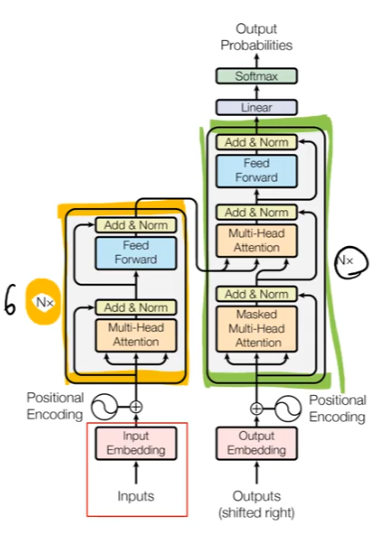
Transformer : Attention is all you need
- attention 메커니즘을 극대화시킨 모델(sequential -> atterntion)
- input embedding -> encoder -> decoder -> output의 구조를 가지고 있음.
encoding block vs docoding block

- unmasked(encoder) : 따로 masking 하지는 않음.
- masked(decoder) : 문장을 생성할 때 앞 -> 뒤로 순차적으로 만들어야하기 때문에 masking이 되어있음.
encoder 구조
- encoder block의 구조는 동일하나, 구조 안 가중치들은 학습을 통해 달라질 수 있음.
- 두 개의 sub layer로 이루어짐 (self-attention layer, feed forward NN)
- 각 word에 대해 self-attention -> feed forward NN를 각각 거침
decoder 구조
- encoder-decoder attention layer가 추가됨. 최종 output을 산출할 때, encoder 정보를 어떻게 반영할 것인지.
Input imbedding
- 처음 들어갈 정보들의 vector
- 첫 번째 encoder의 입력으로만 사용됨
- size는 512차원, 가장 아래 encoder만 word embedding으로 받고 다른 encoder는 이전 encoder를 이어받음.
- 한 sequence의 길이를 최대 몇 개까지 가져갈 것이냐? (ex - 상위 95%에 해당하는 token의 개수)
Positional Encoding
- input imbedding에서 encoder끼리 정보가 넘겨지면서 위치 정보가 손실될 수 있음.
- 이를 해결하고자 positional encoding이 나옴. (위치 정보를 반영할 수 있는 장치)
- input embedding과 positional encoding을 더해서 encoder로 넘겨줌(concat이 아닌 더하기 개념)
- 조건 1 : word embedding이란 동일한 크기의 벡터를 더해야 됨. 크기 자체가 위치에 따라 달라지면 안 됨. 두 단어의 거리가 멀어질수록 position encoding이 멀어지게 된다.
- 조건 2 : 평균에 비해 표준편차가 매우 작음.
Encoder

- self-attention에서는 서로 연관이 있음. (단어들 간의 관계가)
- feed-forward layer에서는 연관이 없음 -> 병렬화 가능 (각 feed-forward에서는 weight가 공유되는 하나의 dense layer를 거침, 다른 encoder계층에서는 weight가 공유되지 않음)
Self-attention

- it이라는 단어가 어디에 영향을 많이 받고 있는지.
Self-Attention in Detai
1) 3종류의 vector를 만듦.

- Query : 현재 processing하는 current word의 representations. 다른 단어들을 scoring하는 기준 값.
- Key : label과 같은 역할. relevant words를 찾을 때 key를 활용.
- value : key에 대한 실제 값

- input imbedding으로부터 각각의 해당되는 matrix가 존재. thinking이라는 x1에 wq를 곱하면 q1이 나오게 됨
- wq와 input imbedding의 연산으로 quey, key, value의 vector를 학습으로 구하는 미지수.
- input 차원(512)보다 q, k, v 의 차원(64)을 적게 잡음. (multi-head attention을 통과하는 vector들을 concat했을 때, 512차원이 다시 만들어지도록. 64x8[multi-head attention의 숫자] = 512)
2) query해당되는 key값을 찾아 value 매칭

query vector와 key vector들을 곱함.

3) 차원의 root값만큼 나눠줌. (gradient가 stable해지는데 도움이 됨)
4) softmax 연산을 거침. (-> 현재 position에 해당하는 단어가, 내가 보고 있는 token에 얼마나 중요한 역할을 하는가)

5) value와 softmax를 곱해줌.
6) softmax에 의해 가중합이 된 value값들을 첫 번째 token의 output으로 쓰겠다.(sum을 왜하지)
7) value와 score를 곱하게 되면 값이 클수록 크게 나타나고, socre가 작으면 남아있지 않음.
matrix 연산

- vector -> matrix 확장

- value vector와 score의 곱으로 나온 vector를 sum하는 이유?
- 각 토큰(x1, x2, ...)을 연산하고 난 모든 vector들을 각각 연산하면 똑같은 z1, z2, ...값이 나오게 되는 거 아닌지
Multi-headed attention
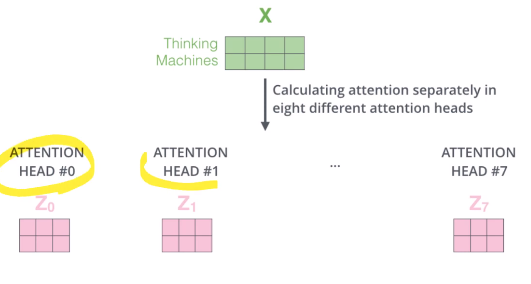
- single attention을 각각을 따로 한 multi head attention. attention을 여러개 쓰겠다.

1) attention heads로부터 나온 z값들을 concat
2) z를 concat한 차원을 row로 가지고, input vector의 차원을 가지는 w0 matrix 생성.
3) 두 matrix를 곱하면 원래 input imbedding의 dimension을 가지는 self-attention의 output을 가지게 됨.
Residual

- residual connection : 입력의 output의 자기 자신 x를 더해줌 -> d/dx 해주면 f'(x)+1이 나오게 됨. (1을 흘려주면 학습에서 유리)
- layer-normalization 사용
Position-wise Feed-Forward Networks

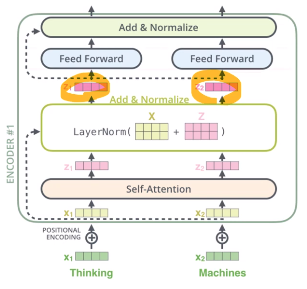
- fully-connected feed-forward network
- 각 포지션에 대해 relu function으로 0과 x중 큰 값을 더하고 weight를 곱하고 상수항을 더함
- 각 layer마다 서로 다른 파라미터 사용
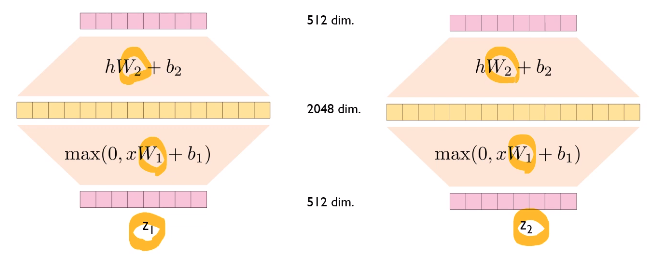
- 같은 block내에서는 동일한 가중치. 다른 block에서는 가중치가 다를수도
Masked Multi-Head Attention(Decoder attention)

- 자기 자신보다 앞 쪽에 해당하는 token들만 attention score를 볼 수 있음.
- 뒷 단은 볼 수 없음. (position에 해당하는 score값을 무한대로 바꿔줌.
Encoder-Decoder Attention

- Encoder를 지나온 block이 key value를 가지고 decoder에 각각 영향을 미쳐서 output이 나오게 됨.
The final linear and softmax layer
- linear layer : fc layer
- softmax layer : score probability
'딥러닝 > 자연어처리' 카테고리의 다른 글
| [NLP] GPT 논문 리뷰 (0) | 2023.01.13 |
|---|---|
| [NLP] Bert 논문 리뷰 (0) | 2023.01.13 |
| [NLP] seq2seq Learning (0) | 2023.01.03 |
| 자연어 처리 (0) | 2021.07.12 |
| NLP 논문리뷰 - Distilling the Knowledge in a Neural Network (1) | 2021.05.13 |

최근댓글