시계열 데이터 분석을 위해서 사용하는 데이터는
https://github.com/cheonbi/OnlineTSA/tree/master/Data/BikeSharingDemand에서 다운받을 수 있다.
cheonbi/OnlineTSA
Online Course of Time Series Analysis. Contribute to cheonbi/OnlineTSA development by creating an account on GitHub.
github.com
원본 데이터는 Kaggle에서 가져온 것으로
https://www.kaggle.com/c/bike-sharing-demand/overview
에서 다운받을 수 있다.
데이터 전처리 과정
- String to DateTime
- Frequency 설정
- 시계열 데이터 요소 추출 (Count_trend, Count_seasonal)
- rolling() (Count_Day, Count_Week)
- 그룹화(temp_group) + 더미 변수(pd.get_dummies)
- 지연값 추출(count_lag1,2)
데이터에 관한 설명을 간단하게 하자면, 일단 X의 값을 가지고 자전거 수요량을 예측하기 위해서 만든 데이터 값이다.
Y와 관련된 값으로는 casual, registered, count가 있다.
- casual : 자전거 서비스에 등록하지 않은 사람들의 자전거 사용량을 의미한다.
- registered : 자전거 서비스에 등록한 사람들의 자전거 사용량을 의미한다.
- count : 위의 두가지 수치를 더한 값으로, 총 자전거 사용량을 의미한다.
데이터 확인

1. String to Datetime
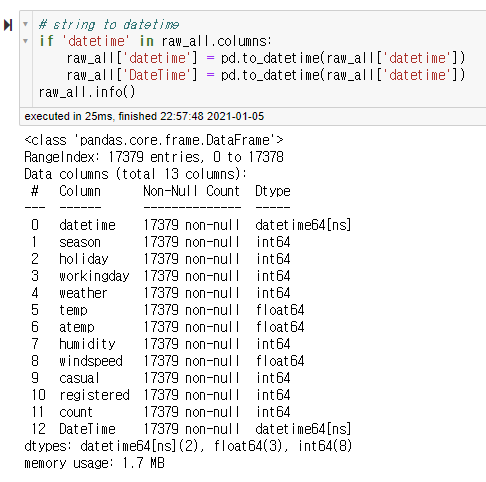
데이터를 불러오고 나서 확인하기 위해서 DataFrame을 출력한 결과이다.
가장 첫번째 Column인 datetime이 string형태로 되어있다.
시계열 데이터에서는 datetime에 입력된 형식의 datetime이라는 자료형이 있는데, 시계열 데이터 분석을 하기 위해서는 string으로 되어있는 datetime column의 데이터 형태를 datetime으로 변환해야 한다. 이때, pd.to_datetime() 함수를 이용한다.
# string to datetime
if 'datetime' in raw_all.columns:
raw_all['datetime'] = pd.to_datetime(raw_all['datetime'])
raw_all['DateTime'] = pd.to_datetime(raw_all['datetime'])
raw_all.info()함수를 사용하고 난 뒤의 데이터 형식을 보면
(if문을 사용한 이유는 셀을 중복으로 실행하는 경우 Column이 너무 많아지거나 중복된 Column 이름으로 인해서 에러가 발생하는 것을 방지하기 위해서이다.)
.info()를 통해서 확인했을 때 가장 첫번째 Column의 데이터 형식이 datetime64[ns]인 것을 확인할 수 있다.
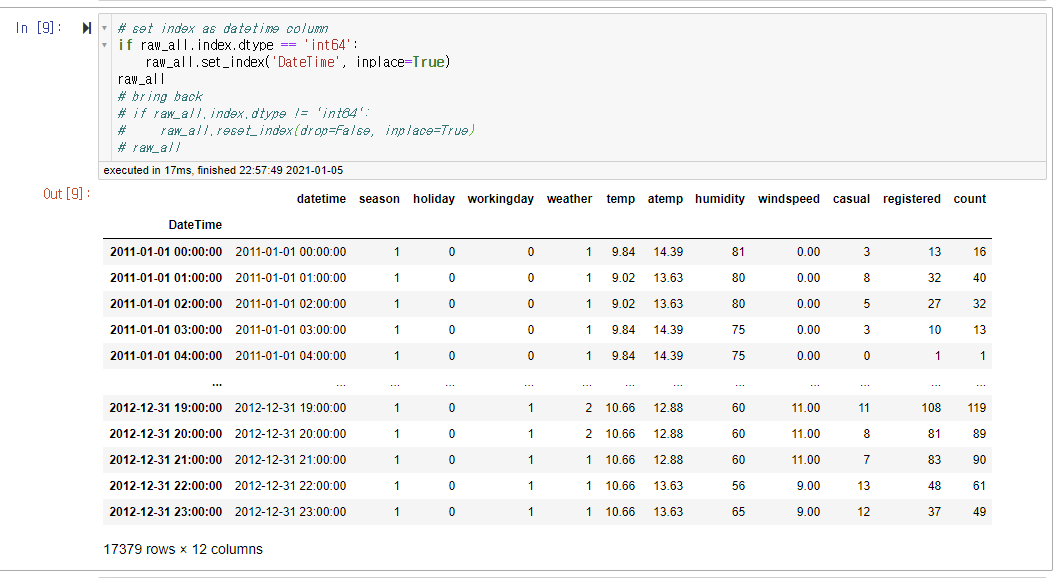
# set index as datetime column
if raw_all.index.dtype == 'int64':
raw_all.set_index('DateTime', inplace=True)
raw_all이후에는 set_index() 함수를 통해서 datetime 형식으로 되어있는 데이터를 인덱스로 설정한다.
(inplace는 True일 경우에는 해당 변수에 저장되어 있는 내용을 변경한 값으로 저장하는 것,
False인 경우에는 변경된 내용은 별도로 두고 해당 변수는 상태를 그대로 유지하는 것)
2. Frequency 설정
빈도(Frequency)란 사전적으로 "얼마나 자주"의 뜻을 가진 단어이지만, 시계열 데이터 분석에서 빈도는 분석에 주로 사용되는 시간의 단위라고 보면된다.
빈도를 설정하게 되면 위에서 우리가 인덱스로 설정한 datetime 데이터 형이 자동으로 맞춰준다.
이 기능을 하는 함수는 .asfreq('시간단위')이다. 여기에서는 시간(Hour) 단위로 설정을 해주었다.
raw_all.asfreq('H')(시간은 'H', 일(day)은 'D', 주(Week)는 'W' 등 한글자 알파벳을 통해서 시간의 빈도를 표현해준다. )
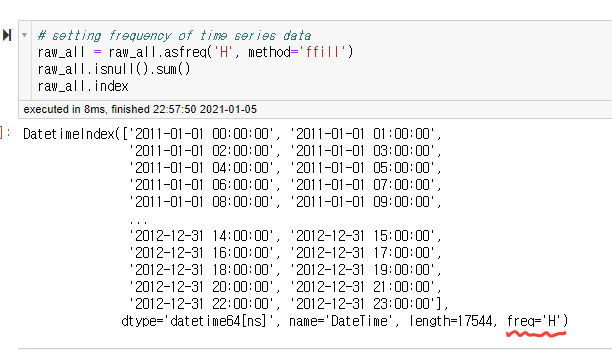
.asfreq()를 통해서 빈도를 설정한다면 단순히 의미적으로만 시간의 단위를 설정해주고 끝나는 것인가?
그렇다면 굳이 컴퓨터가 그것을 알아야 할 이유는 무엇일까?
.asfreq()를 통해서 시간의 빈도를 설정하면 단순히 데이터 분석에서 주로 사용하는 시간의 단위를 설정해주는 것 뿐만 아니라,
- 데이터에 존재하지 않았던, 혹은 누락되었던 시간도 빠짐없이 새로 생긴다.
(다만, 이 때 새로 생성된 행에 대한 나머지 데이터들은 NaN값으로 채워진다. ) - 새롭게 생성된 행들에서 NaN값을 채우기 위해서는 .asfreq()안의 method라는 인자를 통해서 채워줄 수 있다.
- method = 'bfill' : 뒤에 있는 데이터의 값을 그대로 가져와 NaN 값을 채우는 방식
- method = 'ffill' : 앞에 있는 데이터의 값을 그대로 가져와 NaN 값을 채우는 방식
( .asfreq()의 method parameter 이외에도, .fillna() 등을 통해서 NaN 값들을 채울 수 있다. )
3. 시계열 데이터 요소 추출(Trend, Seasonal, Residual)
Seasonal Decompose
statsmodels.api(sm)을 이용해서
sm.tsa.seasonal_decompose() 함수를 이용하면 데이터 값을 Trend(경향), Seasonal(주기성), Residual(잔차)로 분리할 수 있다.
일단 기본적으로 Y값이 'count' 특성이 어떤 형식으로 되어있는지 시각화를 통해서 확인한다.
# line plot of Y
raw_all[['count']].plot(kind='line', figsize=(20,6), linewidth=3, fontsize=20,
xlim=('2012-01-01', '2012-03-01'), ylim=(0,1000))
plt.title('Time Series of Target', fontsize=20)
plt.xlabel('Index', fontsize=15)
plt.ylabel('Demand', fontsize=15)
plt.show()
Y와 관련이 있는 데이터(casual, registered)들의 데이터와 count를 함께 시각화하여 확인해보자.
raw_all[['count','registered','casual']].plot(kind='line', figsize=(20,6), linewidth=3, fontsize=20,
xlim=('2012-01-01', '2012-06-01'), ylim=(0,1000))
plt.title('Time Series of Target', fontsize=20)
plt.xlabel('Index', fontsize=15)
plt.ylabel('Demand', fontsize=15)
plt.show()

Model Parameter
seasonal_decompose() 에서 model parameter는 additive와 multiplicative 두가지를 입력으로 받는다.
- additive : Trend + Seasonal + Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다.
- multiplicative : Trend X Seasonal X Residual로 데이터가 구성 되어있다고 가정을 하고 세가지 요소로 분리한다.
일반적으로 additive가 많이 쓰이고, multiplicative 방식으로 시계열 요소를 분리하는 것은 분리하는 데이터가 백분율 등의 비율을 나타내는 경우에 사용된다고 한다 .
(하지만, 둘 중 어느 방식을 택하는 것은 두가지를 모두 시행하고 시각화를 하여 더욱 적절한 데이터 분리 방식을 선정해야 한다.)
raw_all['count'] - seasonal_decompose(model = 'additive')
# split data as trend + seasonal + residual
plt.rcParams['figure.figsize'] = (14, 9)
sm.tsa.seasonal_decompose(raw_all['count'], model='additive').plot()
plt.show()(plt.rcParams['figure.figsize'] = (14,9)는 시각화 그래프 설정이므로 시계열 데이터 분석과는 무관한 부분이다. )

위에서부터 기존의 count 데이터, Trend, Seasonal, Residual을 나타내는 그래프이다.
raw_all['count'] - seasonal_decompose(model = 'multiplicative')
# split data as trend * seasonal * residual
sm.tsa.seasonal_decompose(raw_all['count'], model='multiplicative').plot()
plt.show()
model = 'additive'에서 반환된 그래프와 비교를 해보았을 때,
Trend, Seasonal에 대한 그래프는 어느정도 유사하지만, Residual에 관해서는 확실히 multiplicative보다는 additive가 더 적절한 그래프를 보여주고 있다는 것을 볼 수 있다.
Reference :
패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
'딥러닝 > 시계열' 카테고리의 다른 글
| 시계열 분석 실습 코드 - 3 (0) | 2021.02.18 |
|---|---|
| 시계열 데이터 분석 코드 - 2 (0) | 2021.02.17 |
| 시계열 데이터 분석 실습 코드 - 1 (0) | 2021.02.16 |
| 시계열 데이터 분리, 분석 성능 확인 (검증지표, 잔차진단) (0) | 2021.02.16 |
| 데이터 분석, Cycle, 용어 (0) | 2021.01.30 |

최근댓글