데이터 분리
데이터 분석
K-fold 교차 검증을 이용하여 무작위로 데이터를 섞은 다음, 추출하여 일정한 비율만큼을 훈련과 테스트 셋으로 정한다.
시계열 데이터 분석
- 바로 다음 단계(혹은 2단계)의 데이터를
- 차례대로 하나씩
일반적인 데이터 분석과 시계열 데이터 분석에서 훈련 / 테스트 데이터를 분리할 때 가장 특징적인 차이점은
시간 순서의 유지 여부이다.
이미지에서 볼 수 있듯이, 이전 데이터들을 학습하여 바로 다음의 값을 예측하고, 이후에 예측한 값 자체를 훈련 데이터와 합하여 그 다음 예측을 진행해 나가는 1스텝 교차 검사(One-step Ahead Cross-Validation)이 있고, 하나를 건너 뛰어서 같은 원리로 예측과 훈련을 반복적으로 수행하는 2스텝 교차검사 (Two-step Ahead Cross-Validation)이 있다.

분석 성능 확인 (검증 지표, 잔차 진단)
편향 - 분산 Trade-off
분석의 성능에 많은 영향을 주는 요인으로는 편향(Bias)과 분산(Variance)가 있다.
- 편향 : 전체적인 경향성이 중심으로부터 벗어난 것을 의미한다.
- 분산 : 평균을 기준으로 나머지 데이터들이 평균과의 차이가 얼마나 심한지를 수치적으로 나타낸 것이다.
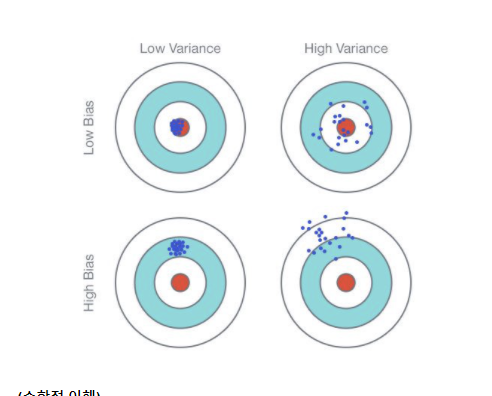
편향이 큰 경우에는 Underfitting, 분산이 적절한 지점까지 작아지지 못한 경우는 Overfitting이라고 부른다.
또한, 편향을 줄이게 되면 분산이 증가하고, 분산을 줄이게 되면 편향이 증가하여, 이것을 '편향-분산 트레이드 오프'라고 한다. 따라서, 둘의 총량을 일정 부분 이하로 줄이는 것이 어려운 경우가 많다.
검증 지표
검증 지표는 시계열 데이터 분석 뿐만 아니라, 대부분의 데이터 분석에서 성능을 평가하는 지표로 많이 사용한다.
- R-squared(R^2):
추정된 (선형)모형이 주어진 데이터에 잘 적합된 정도, 계량경제학에서는 모델에 의해 설명되는 데이터 분산의 정도(퍼센트), (−∞,1] - Mean Absolute Error(MAE):
각 데이터의 단위를 보존하는 성능지표, [0,+∞) - Mean Squared Error(MSE):
가장 많이 사용되며 큰 오차에 패널티(Penalty)를 높게 부여하는 성능지표, [0,+∞) - Mean Squared Logarithmic Error(MSLE):
MSE와 유사하나 큰값/작은값에 적은/많은 비중(Weignt)을 부여하는 성능지표, Exponential 추세가 있는 데이터에 많이 활용, [0,+∞)
지금 당장 이런 지표들의 개념을 완벽하게 숙지를 해서 사용하는 것이 어렵다면,
R-Sqaured는 1에 가까운 값을, 나머지 지표들을 작은 값을 가질 때 성능이 더 좋은 것을 숙지하고 있으면 된다.
잔차진단
앞의 내용에서 기존의 종속변수를 Trend, Seasonal, Residual로 분리를 하였다. 통상적으로 잔차는 Y - Trend - Seasonal을 통해서 만들어진다.
이것을 거꾸로 뒤집어서 생각하면, 잔차에 Trend, Seasonal이 가지고 있어야할 특성이 남아있다면 아직까지 Trend와 Seasonal 부분이 완벽하게 추출되지 않았음을 확인할 수 있다.
잔차는 어떤 형식이어야 하는가?
일반적으로 잔차는 백색잡음(White Noise, WN)의 특성을 가져야 한다. 여기에서 말하는 백색 잡음의 특징은
- 잔차는 평균이 0이어야 하고, 분산이 일정해야 한다.(무조건 1이어야 하는 것은 아니다.)
- 잔차는 정규분포를 따른다.
- 잔차의 자기상관도함수 값은 0이다.
(Autocorrelation : 자기상관도라고 하며, 시계열의 특성상, 다른 column과의 비교 뿐만 아니라, 자신의 특성이 시간의 흐름에 따라 연관이 되어 있는 부분이 있는지를 이것으로 판단한다.)
잔차가 위의 백색잡음의 특성을 가지고 있는지 판단을 할 때에는 가설검정을 사용하는 경우가 많다.
- 등분산성 테스트(Homoscedasticity Test)
Goldfeld-Quandt test, Breusch-Pagan test 등
귀무 가설 : 시계열 데이터는 등분산이다.
대립 가설 : 시계열 데이터는 등분산이 아니다. (발산하는 분산이다.) - 정규분포 테스트(Normality Test)
Shapiro-Wilk test, Kolmogorov-Smirnov test, Jarque-Bera test, Pearson's chi-squared test 등
귀무 가설 : 데이터는 정규분포의 형태이다.
대립 가설 : 데이터는 정규분포가 아닌 형태이다. - 자기상관 테스트(Autocorrelation Test)
Ljung-Box test, Portmanteau test, Durbin-Watson statistic 등
귀무 가설 : 시계열 데이터의 Autocorrelation은 존재하지 않는다.
대립 가설 : 시계열 데이터의 Autocorrelation은 0이 아니다.(존재한다.)
(Durbin-Watson에서는 통계량의 범위가 [0, 4]인데, 통계량이 2 근방의 값으로 나온다면, 귀무 가설을 채택, 0 또는 4 근방의 값으로 나온다면 대립 가설을 채택한다. )
앞의 내용에서 기존의 종속변수 Y를 Trend, Seasonal, Residual로 분리를 하였다.
통상적으로 잔차는 Y - Trend - Seasonal을 통해서 만들어진다.
이것을 거꾸로 뒤집어서 생각하면, 잔차에 Trend, Seasonal이 가지고 있어야할 특성이 남아있다면 아직까지 Trend와 Seasonal 부분이 완벽하게 추출되지 않았음을 확인할 수 있다.
실습 공부 중, 잔차를 시각화하여 그래프를 그리고, 해당 x 지점에서 잔차들의 평균을 빨간색 선으로 연결해 놓았다.

이 그래프를 확인했을 때, 잔차들의 평균이 오른쪽으로 가면서 계속 하락하고 있는 것을 확인할 수 있다. 이런 경우에는 Trend(추세)에 대한 추출이 아직 잔차에서 완전히 추출되지 않았음을 알 수 있다.
자료 출처 : https://github.com/cheonbi/OnlineTSA
'딥러닝 > 시계열' 카테고리의 다른 글
| 시계열 분석 실습 코드 - 3 (0) | 2021.02.18 |
|---|---|
| 시계열 데이터 분석 코드 - 2 (0) | 2021.02.17 |
| 시계열 데이터 분석 실습 코드 - 1 (0) | 2021.02.16 |
| 시계열 데이터 패턴 추출 (Feature Engineering) 1 (3) | 2021.02.01 |
| 데이터 분석, Cycle, 용어 (0) | 2021.01.30 |

최근댓글