조건수에 대해서 알아보기 전에 기본적인 데이터 분석의 목표를 알아보자.
데이터 분석의 공통적인 목표 : Train과 Test Data의 예측 성능을 높이는 것
하지만, 실질적으로 Train과 Test 데이터의 예측 성능을 동시에 올리는 것이 쉽지 않다.
(Train을 과도하게 학습하면 Overfitting이 발생하기 때문이다. )
하지만, 최종적으로 우리가 높여야 할 성능 1순위는 Test Data의 예측 성능이다.
그렇다면,
Train의 성능을 조금 희생하더라도 Test의 성능이 더 잘 나올수 있도록 하는 방향으로 분석을 진행해야 한다.
이러한 방향으로 데이터 분석을 진행하는 데에, 조건수(Condition Number)라는 개념이 사용된다.
조건 수 (Condition Number)


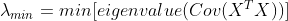
조건수의 감소 목적 :
- 비수학적인 이해 :
독립변수들의 절대적 수치크기나 서로간의 의존도가 분석결과에 미치는 영향을 줄이고, 독립변수의 상대적인 비교효과 반영 - 수학적 이해 :
공분산 행렬의 변동성을 줄여 분석 결과의 변동을 줄인다.
<예시>
데이터 분석에서 특정 X값을 입력받아 예측한 값이 (1, 1, 1, 1)이라고 하자.
- 조건수가 큰 경우 : X의 값이 아주 조금 변화하였음에도, 예측한 값이 (4, 19, -37, 25)처럼 무작위로 변한다.
- 조건수가 작은 경우: X의 값이 아주 조금 변화했다면, 예측한 값이 (1.00001, 1.00001, 1.00001, 1.00001)등 기존에 예측한 Y의 값과 거의 차이가 없도록 나온다.
★조건수가 큰 경우, X의 변화는 아주 미미함에도 불구하고, (1, 1, 1, 1)과 (4, 19, -37, 25)와 같은 예측값이 존재한다면, 결론적으로 두 예측값 모두 불확실성에 의해서 사용하지 못하게 되는 경우가 발생하게 된다!
이것을 다른 말로 하면
Condition Number가 작을수록 Overfitting의 확률이 낮다는 것을 의미한다.
1. 조건수가 작은 행렬을 사용하는 경우
# 조건수가 작을 때
# X 데이터
import numpy as np
A = np.eye(4)
A
# Y 데이터
Y = np.ones(4)
Y

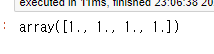
# 계수 추정
np.linalg.solve(A, Y)
여기에서 해가 ([1., 1., 1., 1.])로 나온 것을 확인할 수 있다.
이제 기존의 데이터 행렬 (A)에서 대각 성분에 0.0001을 더하고 계수를 추정해보면,
#X 데이터 오차반영
A_new = A + 0.0001 * np.eye(4)
A_new
# 계수 추정
np.linalg.solve(A_new, Y)
이전에 계수의 값이 [1., 1., 1., 1.] 이었던 것을 생각하면 A가 작게 변하면, 그에 대한 답(계수)도 크게 변화하지 않는다는 것을 볼 수 있다.
# 조건수 확인
np.linalg.cond(A)
행렬 A의 조건수를 계산해보면, 값이 1이 나오게 된다.
2. 조건수가 큰 행렬을 사용하는 경우
# 조건수가 클 때
# X 데이터
from scipy.linalg import hilbert
A = hilbert(4)
A

scipy.linalg의 hilbert함수를 이용해서 Condition Number가 큰 행렬 A를 생성한다.
(여기 내용에서는 힐버트 변환에 대해서 알기보다는, 단지 조건수가 큰 행렬을 생성하기 위해서 사용한 도구 정도로 이해하면 될 것 같다. )
# Y 데이터
Y = np.ones(4)
Y
# 계수 추정
np.linalg.solve(A, Y)
일단, 처음에 계수를 추정했을 때, [-4, 60, -180, 140]의 결과가 계산된다. 이전과 마찬가지 방식으로 A의 각 대각 성분에 0.0001을 더한 후, 다시 계수를 추정해보자.
# X 데이터 오차반영
A_new = A + 0.0001 * np.eye(4)
A_new
# 계수 추정
np.linalg.solve(A_new, Y)
각 성분에 0.0001을 더했을 뿐인데, 첫번째 결과와는 전혀 관련성이 없는 새로운 계수들이 계산되는 것을 확인해 볼 수 있다.
여기에서 조건수를 확인해보면 ,
# 조건수 확인
np.linalg.cond(A)
이전의 경우에 조건수가 1이었던 것에 비해, 조건수가 엄청나게 큰 행렬인 것을 확인할 수 있다.
조건수를 낮추는 방법
- 변수들 단위차이를 없애주는 Scaling
- 독립 변수들 간 상관관계가 높은 '다중공선성'을 제거 (VIF, PCA 등의 방법을 이용)
- 독립 변수들 간 의존성이 높은 변수들에 페널티를 부과하는 방식
Reference : 패스트 캠퍼스 파이썬을 활용한 시계열 분석 A-Z
'딥러닝 > 시계열' 카테고리의 다른 글
| 정상성 (0) | 2021.03.22 |
|---|---|
| 조건수를 줄이는 방법 (0) | 2021.03.15 |
| [논문 Review] 콜센터 인입 콜량 예측을 위한 시계열 모델 비교 분석 2 (0) | 2021.03.13 |
| [논문 Review] 콜센터 인입 콜량 예측을 위한 시계열 모델 비교 분석 1 (0) | 2021.03.12 |
| 현실적인 데이터 전처리 (0) | 2021.03.05 |

최근댓글