GPT-2 : Language Models are Unsupervised Multitask Learners
- GPT와 구조는 똑같으나 훨씬 더 대용량 데이터를 학습(40GB, WebText)
- GPT Medium(345M Parameters = BERT Larget) -> Large -> Extra Large model 확장
GPT-2 vs BERT

- BERT는 Bidirectional 학습, GPT-2는 auto-regressive
* auto-regressive : 각 token이 생성이 되면, 생성된 token이 그 다음 token을 생성하기 위한 input으로 사용.
- GPT2는 1024개의 token을 처리할 수 있음.
trained GPT-2
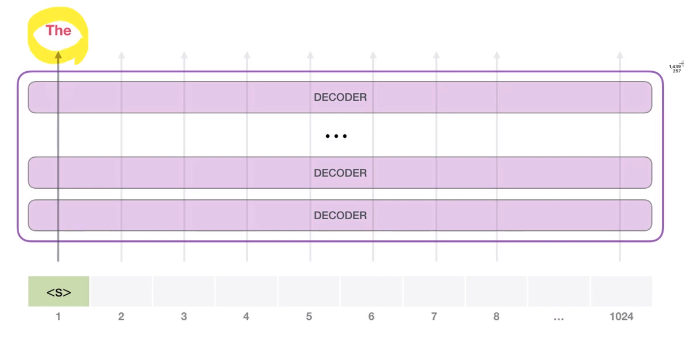
- unconditional samples를 통해 단어를 생성해냄
- top-k라는 파라미터를 가지고 있어서 최대 k개의 그럴듯한 단어들을 제시해줌.
- 첫 번째 token을 2번째 token을 처리함에 있어, weight를 다시 학습시키지 않는다.

- token embedding + positional encoding -> docoding block를 통과하면서 output을 만들어 냄.

- 1과 A(2와 B)는 구조는 동일. 구조 안에서의 weight는 다름. (decoding block이 다름)

- it이라는 단어가 auto-regressive를 진행하며 masked self-attention이 수행 됨.
- 자기 자신의 attention score는 18%, a -> 30%, robot ->50%의 attention score가 나옴. (it -> a robot을 가리킨다고 해석)
Model Output
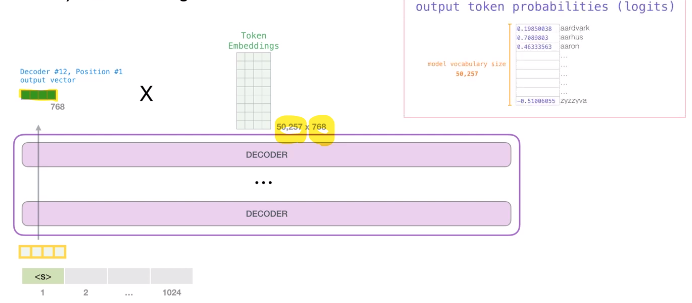
- decoder를 통과한 output vector(768dim)와 token embeddings을 연산을 해서 token probabilities를 구함.
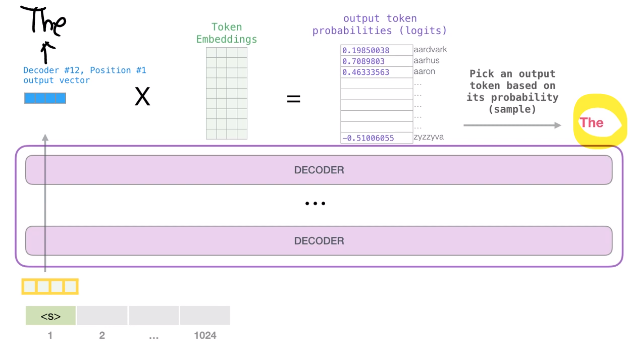
- 그 중 the라는 단어가 logitis 값이 가장 크게 나오면, The라는 단어로 최종 산출이 됨.
GPT-2 특징
- token을 만들 때 Byte Pair Encoding을 사용함.
* Byte Pair Encoding : https://ratsgo.github.io/nlpbook/docs/preprocess/bpe/
데이터 가장 많이 등장한 문자열을 병합해서 데이터를 압축. -> bi-gram 쌍으로 압축(빈도 합치기) -> 우선순위에 따라 병합
말뭉치의 likelihood를 높이는 워드피스와는 다름 (두 단어가 연이어 등장할 확률 / 단어 각각 등장할 확률의 곱)
- 동시에 처리하는 규모는 512 token (최대 token은 1024 token)
- layer normalization이 transformer 구조에서는 매우 중요
'딥러닝 > 자연어처리' 카테고리의 다른 글
| [Transformer 모델 구조 분석] Attention Is All You Need (0) | 2023.02.20 |
|---|---|
| [NLP] GPT 논문 리뷰 (0) | 2023.01.13 |
| [NLP] Bert 논문 리뷰 (0) | 2023.01.13 |
| [NLP] Transformer 논문 리뷰 (0) | 2023.01.03 |
| [NLP] seq2seq Learning (0) | 2023.01.03 |

최근댓글