1. What is keras?
케라스(Keras)는 텐서플로우 라이버러리 중 하나로, 딥러닝 모델 설계와 훈련을 위한 고수준 API이다. 사용자 친화적이고 모델의 구성이 쉽기 때문에 기본 이미지 분류 및 텍스트 분류에 권장되며, 실제로 텐서플로우 2.0 버전에서는 플레이스 홀더나 세션의 개념 등을 없애고 파이썬으로 작성된 케라스를 접목하여 파이썬 언어를 사용하는 개발자들의 생산성을 많이 높이기도 했다. 파이토치, CNTK 등의 많은 머신러닝 프레임워크가 있음에도 불구하고 많은 사람들이 텐서플로우를 사용하는 이유 중 하나가 바로 케라스의 존재 때문이라고 생각하기도 한다. 그럼 이 케라스를 사용하여 텐서플로우 공식 홈페이지 튜토리얼에도 나와있는 패션 mnist 이미지 분류 문제부터 접근해보자.
첫 번째 신경망 훈련하기: 기초적인 분류 문제 | TensorFlow Core
Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도 불구하고 공식 영문 문서의 내용과 일치하지 않을 수
www.tensorflow.org
2. 라이브러리 및 데이터 셋 불러오기
import tensorflow as tf
from tensorflow as keras
import numpy as np
import matplotlib.pyplot as plt
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()패션 mnist는 총 10개의 카테고리로 분류된 70,000개의 흑백이미지 데이터이다. 이 중 모델을 훈련 하는데 60,000개의 이미지를 사용하고, 이 모델의 성능이 얼마나 좋은지 10,000개의 이미지로 평가한다. 각각의 이미지는 28 * 28의 넘파이배열(해상도)를 가지고 있고, 각 픽셀마다 0~255의 값을 가진다.
- train_images, train_labels : 모델 학습에 사용되는 데이터셋 (60,000개)
- test_images, test_labels : 모델 검증에 사용되는 데이터셋 (10,000개)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']이 데이터 셋에는 각 클래스(feature) 별로 이름이 아닌 index가 들어가 있기 때문에 각각의 index가 어떤 클래스를 가리키는지 확인하기 위해 별도의 변수를 만들어 저장했다.
3. 데이터 탐색 및 전처리
우선 데이터가 어떻게 생겼는지 살펴보자.
train_images.shape # (60000, 28, 28)
train_labels # array([9, 0, 0, ..... ])
len(train_labels) # 60000
len(test_labels) # 10000위의 코드를 한 줄씩 jupyter notebook 에서 실행시켜보면 주석과 같은 결과가 나온다.
- train_images : 28 * 28 넘파이 배열을 가진 이미지가 총 60000개 가지고 있다는 것을 알 수 있다.
- train_labels : 0~9 사이의 정수값으로 이루어진 배열이다. 각 정수값은 앞서 저장한 class_names의 요소들과 같다.
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()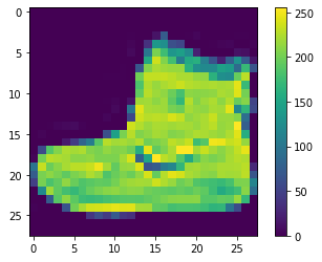
이제 각 이미지가 어떻게 저장되어 있는지 살펴보자. 위와 같은 코드를 통해 train_images의 첫번째 이미지를 보면 각 픽셀값의 범위가 0~255라는 것을 알 수 있다. 이를 신경망 모델에 주입하기 전에 이 값의 범위를 0~1사이로 조정해주자. (물론 test_images도 똑같이 전처리를 해주자.)
train_images = train_images / 255.0
test_images = test_images / 255.0
★ 4. 모델 구성
1) 층 설정 (layer)
케라스에서는 층(Layer)을 조합하여 딥러닝 모델(model)을 만든다. 모델은 일반적으로 이 층들의 조합, 그래프이며 가장 흔한 모델 구조는 층을 차례대로 쌓는 tf.keras.Sequential 모델이다.
model = keras.Sequential()
model.add(layers.Flatten(input_shape = (28, 28))) # 1
model.add(layers.Dense(128, activation='relu')) # 2
model.add(layers.Dense(10, activation='softmax')) # 3위의 모델을 하나씩 살펴보자. 먼저 첫번째 Layer은 입력받은 2차원 배열의 이미지(28*28)를 784개의 요소를 가진 1차원 벡터로 변환하는 과정이다. 이 과정에서는 학습되는 가중치가 없고 데이터를 변환하기만 한다.
이렇게 픽셀을 펼친 뒤에는 두번째와 세번째 Layer에서는 가중치와 편향(bias)를 이용하여 모델을 학습시킨다. 두 개의 Dense층이 연속되어 연결되어지는데 이 층을 밀집연결 또는 완전연결 계층(fully-connected layer)이라고 부른다. 처음 Dense층에서는 784개의 노드를 가중치와 편향을 이용해 128개의 노드로 변환시키는 과정이며 이때 활성화 함수는 Relu함수이다. 이 다음 두번째 Dense층에서는 길이가 10인 logit model array를 반환하며, 이때 활성화 함수는 softmax함수이다. 이 층은 10개의 확률을 반환하고, 이 때 반환된 값의 전체 합은 1이다.
정리해보면, 각 이미지가 0~9까지의 class중 어디에 속하는지를 나타내는 값이 마지막 노드를 통해 0~1사이의 실수값으로 나타내어 저장된다는 뜻이다.
2) 모델 컴파일 (model compile)
이렇게 모델을 만들었으면, 추가적으로 몇 가지 설정을 더 해주어야 한다.
- 손실함수 (loss function) : 훈련하는 동안 모델의 오차를 측정하며, 모델이 올바른 방향으로 향하려면 이 함숫값을 최소화 하는 방향으로 가야한다.
- 최적화 (Optimizer) : 데이터의 손실 함수를 최소화 하는 방향으로 모델의 업데이트 방법을 결정한다.
- 지표 (Metrics) : 훈련 단계와 테스트 단계를 모니터링 하기 위해 사용한다. 주로 '정확도'를 사용한다.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
5. 모델 훈련
이렇게 만들어진 모델을 실제 train_images를 통해 훈련시켜 보자.
model.fit(train_images, train_labels, epochs=5)
epochs는 모델 훈련 횟수를 뜻한다. 모델을 총 5번 반복시키면서 가중치와 편향을 train_images와 train_labels에 맞게 업데이트 시킨다. 훈련 데이터셋으로 모델을 5번 훈련시켰을 때 정확도는 총 89%가 나온다. 이렇게 훈련시킨 모델을 test_images와 test_labels로 검증해보자.
(test_loss, test_acc) = model.evaluate(test_images, test_labels, verbose=2)
print('\n테스트 정확도:', test_acc)
테스트 데이터셋으로 검증했을 때 정확도는 87%가 나온다. 훈련 데이터셋에 비해 정확도가 더 낮게 나오는데, 이는 과적합(Overfitting)이다. 딥러닝 모델이 훈련 데이터셋에 너무 잘 맞아서, 즉 훈련 데이터셋 에서의 사소한 디테일까지 모두 기억하여 테스트 데이터셋으로 모델의 성능을 평가했을 때 부정적인 영향을 미칠수도 있다. 따라서 새로운 데이터셋에서 성능이 더 안좋아지는 것이다.
6. 예측하기
predictions = model.predict(test_images)
predictions[0]
위의 훈련된 모델을 사용해서 테스트 데이터셋의 각 이미지들이 어떤 클래스를 가지고 있는지 예측할 수 있다. 위의 predictions의 각각의 요소에는 10개의 클래스에 대한 예측값이 배열의 형태로 담겨있다. 이 값들은 모델의 신뢰도(confidence)를 나타내며 가장 높은 신뢰도를 가진 class가 해당 image의 label이라고 판단할 수 있다. 실제로 해당 predictions의 첫번째 요소의 최댓값과 test_labels의 첫번째 값이 일치하는 것을 확인할 수 있다.
np.argmax(predictions[0]) # 9
test_labels[0] # 9
이를 그래프로 나타내 확인해보자. matplot library에 대한 설명은 여기서 더 자세히 확인할 수 있다.
# 이미지와 예측값이 맞으면 푸른색 글자로, 맞지 않으면 빨간색 글자로 나타난다.
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
# 이미지와 예측값이 맞는 막대는 푸른색으로, 맞지 않으면 회색으로 나타난다.
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()
'데이터 사이언스 메뉴얼 > Object classification' 카테고리의 다른 글
| 합성곱 신경망, Convolutional Neural Network (CNN) (1) | 2020.05.28 |
|---|---|
| 최적화, Optimizer (0) | 2020.05.23 |
| 손실 함수, Loss function (0) | 2020.05.17 |
| 완전 연결 계층, Fully connected layer (5) | 2020.05.12 |
| 텐서플로우, Tensorflow (0) | 2020.05.07 |

최근댓글