합성곱 신경망, Convolutional Neural Network (CNN)
완전 연결 계층, Fully connected layer (JY) Keras 사용해보기 1. What is keras? 케라스(Keras)는 텐서플로우 라이버러리 중 하나로, 딥러닝 모델 설계와 훈련을 위한 고수준 API이다. 사용자 친화적이고 모델의
dsbook.tistory.com
기존에는 완전 연결 계층을 이용해 이미지를 분류했었다. 완전 연결 계층이란 한 층(Layer)의 모든 뉴런이 다른 층(Layer)의 모든 뉴런과 연결되어 있는 형태로, 기본적으로 2차원의 흑백 이미지를 (컬러 이미지는 RGB의 채널이 들어가므로 3차원이다.) 1차원 배열로 평탄화시킨 후 연산 작업을 진행한다. 문제는 이 평탄화 작업이다. 이미지 데이터의 경우 인접한 픽셀들끼리의 명암 혹은 RGB채널의 픽셀 값은 관련이 많고, 멀리 떨어져 있는 픽셀들끼리는 서로 관련이 없는 등의 정보를 내포하고 있다. 하지만 평탄화, Flatten 작업을 통해 2차원(혹은 3차원) 배열을 1차원 배열로 펼치는 순간 이미지 데이터의 형상이 훼손된다. 이것이 왜 문제가 되느냐고 하면, 필기체 인식을 위해 28 * 28을 완전 연결 계층 (정확히는 Fully-connected multi-layered neural network, MLNN로 보는 것이 맞다.)으로 학습시켰다고 하자. 이렇게 학습된 가중치 값들은 그 주변의 픽셀 값들에 대한 정보가 없기 때문에, 글자의 크기가 달라지거나, 글자가 이동하거나 회전되거나, 혹은 변형이 조금만 생기더라도, 그리 좋은 결과를 기대하기가 어렵다. 즉, 글자의 형상을 전혀 고려하지 않는 방식이기 때문에 많은 학습 데이터와 거기에 맞는 학습시간을 대가로 지불해야 한다. 이 문제를 해결하기 위한 방식으로 제시된 방법이 CNN이다.
model = keras.Sequential([
keras.layers.Conv2D(32, kernel_size=(3, 3), input_shape=(28, 28, 1), padding="SAME", activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding="SAME"),
keras.layers.Conv2D(64, kernel_size=(3, 3), padding="SAME", activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding="SAME"),
keras.layers.Flatten(),
keras.layers.Dense(1024, activation="relu"),
keras.layers.Dense(10, activation="softmax"),
keras.layers.Dropout(0.25)
])CNN의 기본적인 모델 구성은 다음과 같다. FCL에서는 Affine계층과 활성화 함수로 구현됐지만, CNN에서는 합성곱 계층(Convolution Layer)과 풀링 계층 (Pooling Layer)이 추가된다. (여기서 Affine계층은 순 전파 과정에서 수행하는 뉴런에 가중치를 곱하고 편향을 더하는 계층, 즉 행렬의 내적이라고 생각하면 된다.)

1. 합성곱 계층, Convolutional Layer
합성곱 신경망에서 핵심이자 가장 중요한 구성 요소이다. 데이터의 형상을 유지하면서 학습시키기 위한 뉴런의 형태도 달라진다. 이때, 뉴런을 Filter 혹은 kernel이라고 부른다. 이 필터가 바로 합성곱 계층에서의 가중치에 해당하며, 학습단계에서 적절한 필터를 찾도록 학습하면서 업데이트된다. 필터를 적용해 유사한 이미지의 영역을 강조하는 특성 맵(feature map)을 출력하여 다음 계층으로 전달한다.
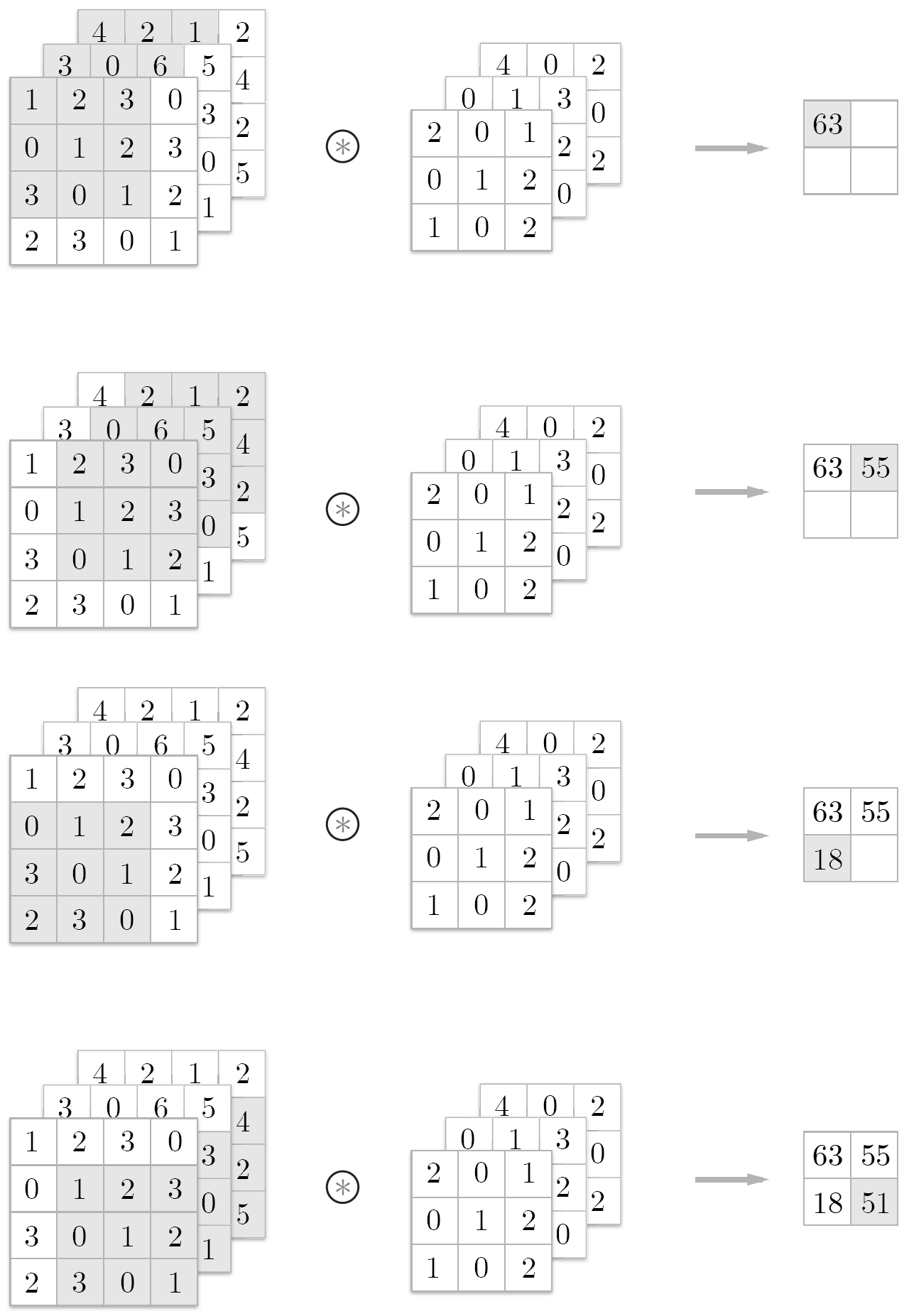
합성곱 계층을 연산할 때는 필터와 그에 대응하는 입력 데이터의 원소끼리 곱한 후 그 합을 구하여 추출한다. 이 방법을 Fused Multiply-Add 방법이라고 부르며, 마지막에 편향을 더해 마무리한다. 편향은 필터처럼 이미지 데이터와 같은 차원을 갖는 것이 아니라 항상 하나만 존재한다.
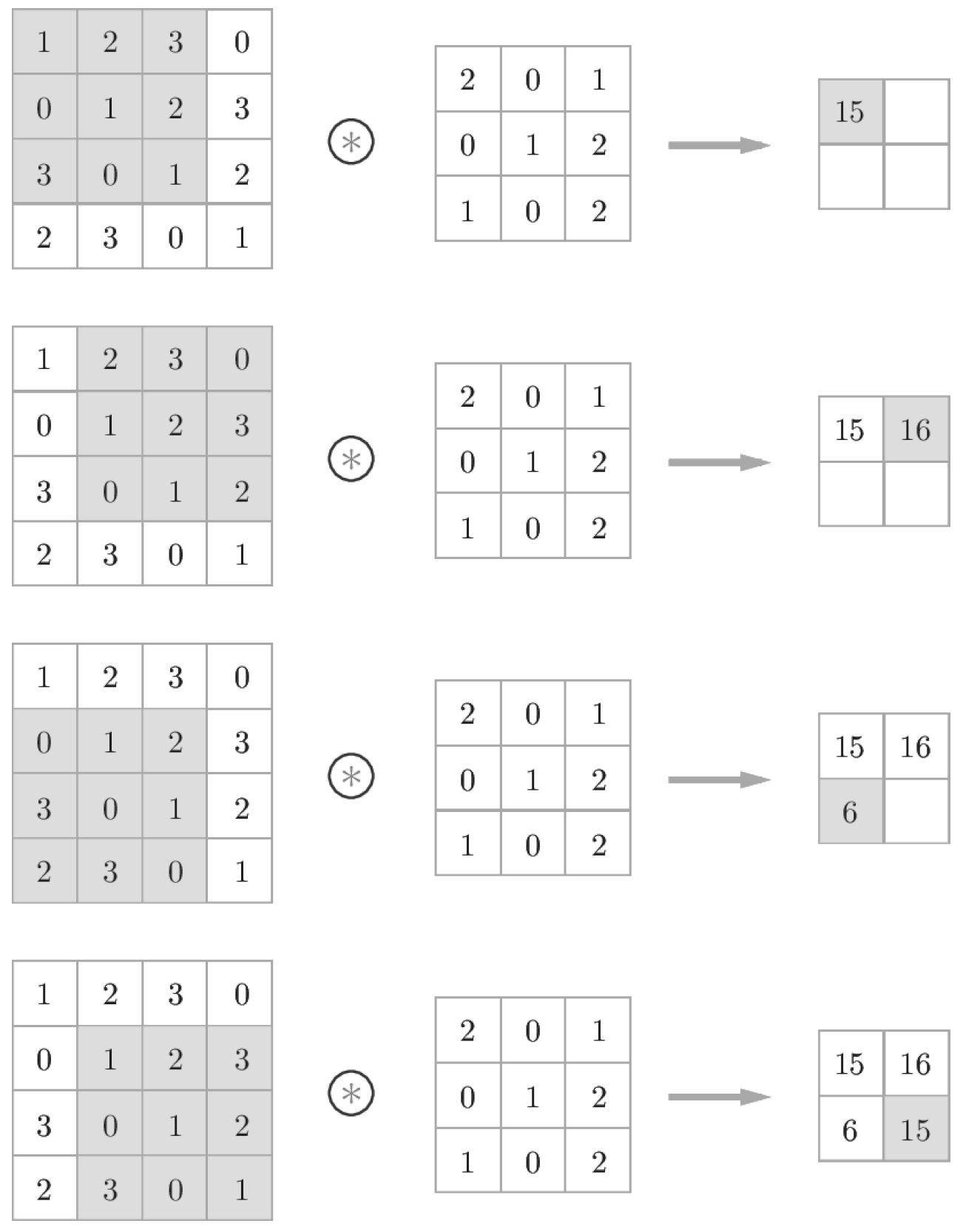
1) 패딩, Padding
필터로 입력 데이터의 특징맵(Feature map)을 추출할 때 중요하게 작용하는 요소가 2가지가 있는데, 패딩과 스트라이드이다. 위에서는 입력 데이터가 4*4, 필터가 3*3의 크기를 가지므로 최종적으로 나온 특징 맵은 2*2의 크기를 갖는다. 반대로, 필터가 2*2의 크기를 갖는다고 생각하고 연산해보면 특징 맵은 3*3의 크기를 갖는 것을 알 수 있다. 이처럼 필터의 크기가 커지면 커질수록 특징 맵의 크기는 작아진다. 크기가 작아질수록 모서리에 있는 이미지 데이터의 정보가 사라지게 되므로, 이를 조절해주기 위한 값이 패딩이다. 즉, 패딩은 출력 데이터의 공간적 크기를 조절해주기 위해 사용해주는 파라미터이다. 파라미터 값으로 더 나은 결과를 위해 조절해줄 수 있지만, 입력 데이터의 크기와 출력 데이터의 크기를 같게 해주는 'zero-padding' 혹은 'same-padding'을 주로 사용한다.

2) 스트라이드, Stride
기본적으로 입력 데이터와 필터를 연산할 때는 한 칸씩 이동하면서 연산을 한다. 이때, 스트라이드 값을 1이라고 한다. 즉, 스트라이드는 입력데이터에 필터를 적용할 때 이동할 간격을 조절해주는 파라미터이다. 스트라이드는 입력 데이터가 너무 큰 경우, 연산량을 줄이기 위한 목적으로 사용한다.
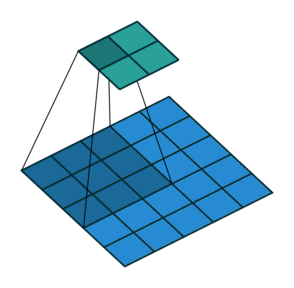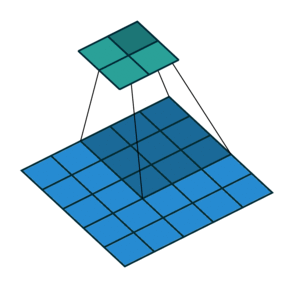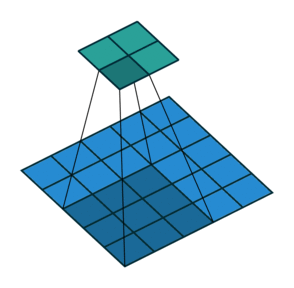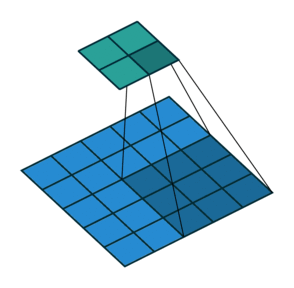
하지만 대부분 스트라이드 값을 1로 하고, 나중에 Pooling 계층을 통해 이미지의 크기를 줄이는 sub-sampling 과정을 거치는데, 그 이유는 앞서 패딩 값을 조절해주는 것과 마찬가지로 데이터의 특징 일부를 잃어버릴 수도 있기 때문이다. 아래의 그림은 스트라이드 값 2를 가지는 3 by 3의 필터로 합성곱 연산을 진행한 결과이다. 오른쪽 그림에서 연하게 칠해져 있는 부분의 특징을 거의 잃어버리면서 4 by 4의 특징 맵을 출력하게 된다.

3) Multi Channel
흑백 이미지와는 달리 RGB 색깔을 가지는 이미지는 채널의 개수가 3개이다. 이럴 때는 각각의 채널마다 합성곱 연산을 한 결과를 모두 더한 값으로 특징 맵으로 추출하게 된다. 이때 입력 데이터의 채널 수와 필터의 채널 수가 같아야 한다.
2. keras.layers.Conv2d
train_images = train_images / 255.0
test_images = test_images / 255.0
train_images = train_images.reshape([-1, 28, 28, 1]) # samples, rows, cols, channels
test_images = test_images.reshape([-1, 28, 28, 1]) # samples, rows, cols, channelsmodel = keras.Sequential([
keras.layers.Conv2D(32, kernel_size=(3, 3), input_shape=(28, 28, 1), padding="SAME", activation="relu"),
keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding="SAME"),
keras.layers.Conv2D(64, kernel_size=(3, 3), padding="SAME", activation="relu"),
keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding="SAME"),
keras.layers.Flatten(),
keras.layers.Dense(1024, activation="relu"),
keras.layers.Dense(10, activation="softmax"),
keras.layers.Dropout(0.25)
])케라스에는 다양한 합성곱 연산을 위한 도구를 제공한다. 그 중 우리는 이미지 데이터인, 2차원 데이터를 다루므로 Conv2d를 사용하여 합성곱 계층을 만들어 준다. Conv2d 함수는 4차원 데이터(batches, channels, rows, cols의 "channels_first"방식 혹은 batches, rows, cols, channels의 "channels_last"방식)를 입력으로 받고 연산 후 특징 맵 역시 같은 형태로 출력한다. 그래서 앞서 데이터를 학습시키기 전에 입력 데이터의 형태를 4차원 형태로, channels_last 방식으로 reshape 해주었다. Conv2d에는 다양한 인자를 입력받는데, 앞서 살펴봤던 것들 위주로 중요한 인자들이 무슨 역할을 하는지 살펴보자.
Input shape -> (batches_size, channels, rows, cols) or (batches_size, rows, cols, channels)
| keras.layers.Conv2d | |
| filters | 필터의 개수(=특징 맵의 개수), 정수 형태로 입력받는다. |
| kernel_size | 필터의 크기를 지정해준다. 주로 2개의 정수가 들어있는 튜플 혹은 리스트 형태를 입력으로 받지만, 필터의 가로와 세로의 길이가 같다면 정수 하나만 입력해도 된다. |
| strides | 스트라이드 값을 지정해준다. 주로 2개의 정수가 들어있는 튜플 혹은 리스트 형태를 입력으로 받지만, 움직이는 거리가 같다면 정수 하나만 입력해도 된다. |
| padding | "valid" 혹은 "same" 값을 입력으로 받는다. (default = "valid") |
| data_format | "channels_last" 혹은 "channels_first" 값을 입력으로 받는다. (default = "channels_last") |
| activation | Relu와 같은 활성화 함수를 입력으로 받는다. |
| input_shape | 이 계층을 처음 사용할 때, input_shape 인자 값을 지정해 주어야 한다. 이때, 튜플 혹은 리스트 형식으로 입력 받는데, 4차원 데이터 중 batches값을 뺀 (rows, cols, channels 혹은 channels, rows, cols)의 형태로 입력해주어야 한다. |
Output shape -> (batches_size, channels, rows, cols) or (batches_size, rows, cols, channels)
Return -> activation(conv2d(input, kernel) + bias)
3. Summary

Keras documentation: Conv2D layer
Conv2D layer Conv2D class tf.keras.layers.Conv2D( filters, kernel_size, strides=(1, 1), padding="valid", data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer="glorot_uniform", bias_initializer="zeros", kernel_regulariz
keras.io
Intuitively Understanding Convolutions for Deep Learning
Exploring the strong visual hierarchies that makes them work
towardsdatascience.com
[Part Ⅳ. CNN] 4. Convolution Layer [2] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic ...
blog.naver.com
'데이터 사이언스 메뉴얼 > Object classification' 카테고리의 다른 글
| 폴링 계층, Pooling Layer (1) | 2020.06.04 |
|---|---|
| 합성곱 신경망, Convolutional Neural Network (CNN) (1) | 2020.05.28 |
| 최적화, Optimizer (0) | 2020.05.23 |
| 손실 함수, Loss function (0) | 2020.05.17 |
| 완전 연결 계층, Fully connected layer (5) | 2020.05.12 |

최근댓글