Gradient Descent는 cost function을 최소화하기 위해 이용할 수 있는 방법 중 하나이며, cost function 말고도 각종 optimization에 이용되는 일반적인 방법이다. hypothesis function의 최적의 parameter를 찾는 방법이다.
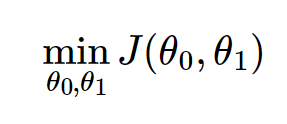

Gradient Descent Outline은 위처럼 초기 파라미터값으로 시작하여, 희망하는 최소값으로 줄 때까지 계속 갱신해나간다.

cost function을 세타j에 대해 미분하고 학습률을 곱해 계속 갱신해나간다. 주의해야 될 점은 파라미터를 단계적으로 갱신해나가는 것이 아니라, 동신에 업데이트 해야 된다는 점이다. 알파값은 learning rate라고 하는데, 이 크기가 클수록 한 번에 더 많이 움직이게 된다.

learning rate가 너무 작으면 수렴하는데 오래걸리고, 너무 크면 최소값에 이르지 못해 발산하여 적절한 learning rate를 고르는 것이 중요하다.

gradient descent를 linear regression에 적용해보자면,

Linear regression에서 정의한 cost function을 위치에 맞게 대입하기만 하면 된다. 아래 xi가 밖으로 나온 이유는 세타1에 대해 미분했기 때문에 xi가 나온 것이다. 여기서 m은 training set size이고, xi와 yi는 training set의 데이터인데 순차적으로 업데이트 되는 것이 아닌 동시에 업데이트 된다는 것에 주의해야 한다. 처음에는 임의로 설정한 parameter에서 출발하여 iteration이 거듭될수록 점점 정확한 hypothesis가 되는 것이고, linear regression cost function은 convex이므로 항상 global optima에 수렴한다. (왜 convex라고 해서 global optima에 수렴하는거지?)
'기계학습 > Machine Learning' 카테고리의 다른 글
| Feature Scaling이란? (0) | 2021.07.23 |
|---|---|
| Multivariate Linear Regression이란? (0) | 2021.07.22 |
| Machine Learning- 회귀 (0) | 2021.07.22 |
| [파이썬 머신러닝 완벽 가이드] 회귀 실습(기본) - 자전거 대여 수요 예측 (0) | 2021.07.09 |
| [파이썬 머신러닝 완벽 가이드] 전처리, 로지스틱 회귀, 회귀 트리 (0) | 2021.07.08 |

최근댓글